# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 大牛 Andrej Karpathy 又「上新」了,这次一口气放出了长达四个小时的视频。
视频主题为「让我们来复现 GPT-2(1.24 亿参数)」。

Karpathy 表示,此次视频之所以这么长,是因为它很全面:从空文件开始,最后得到一个 GPT-2(124M)模型。
具体实现步骤包括如下:
该视频以「Zero To Hero」系列视频为基础,有些地方参考了以往视频。你可以根据该视频构建 nanoGPT 存储库,到最后大约有 90% 相似。
当然,Karpathy 上传了相关的 GitHub 存储库「build-nanogpt」,包含了全部提交历史,这样你可以一步步看到视频中所有的代码变化。
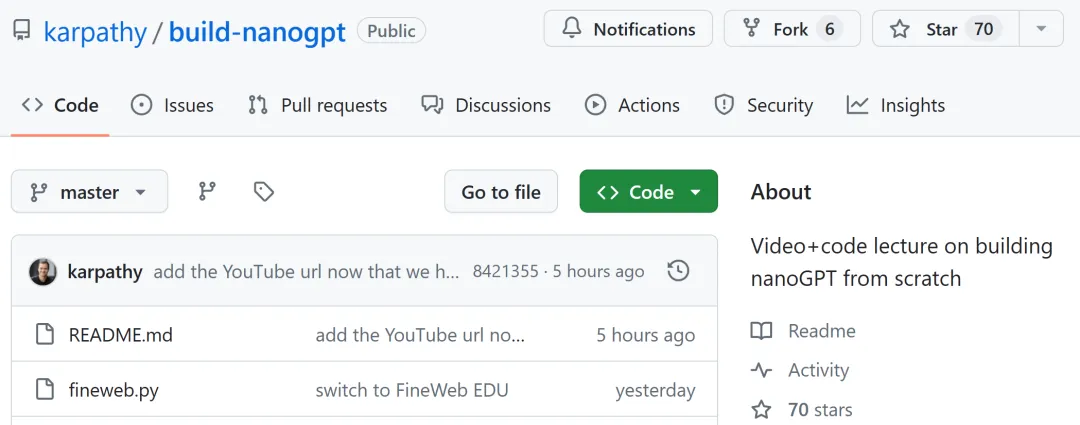
GitHub 地址:https://github.com/karpathy/build-nanogpt
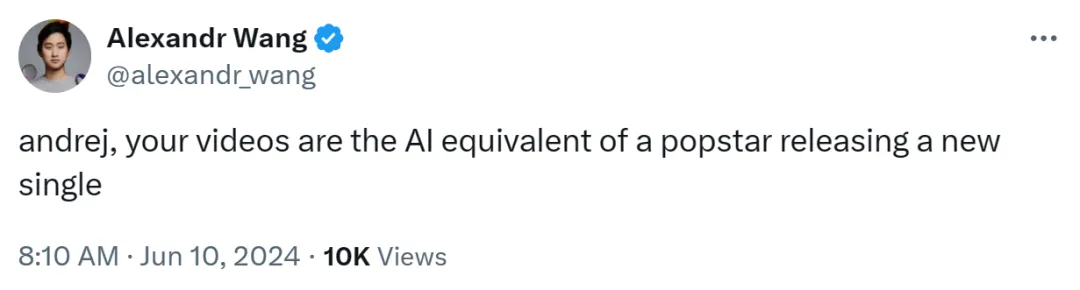
AI 独角兽 Scale AI CEO Alexandr Wang 表示,Karpathy 发布视频就像是流行歌手发布新单曲一样。
甚至还有人将 Karpathy 的推特内容通过文生音乐模型 Suno 转换为了一首 Rap,简直了。
视频概览
该视频分为了四大部分:建立网络(很多是以往教程回顾)、加快训练速度、设置运行和结果。
视频第一部分内容(带时间戳)具体如下:
视频第二部分内容(带时间戳)具体如下:
视频第三部分内容(带时间戳)具体如下:
视频第四部分内容(带时间戳)具体如下:
03:59:39 总结,并上传「build-nanogpt github」存储库
文章来源于“机器之心”



