# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
360 度场景生成是计算机视觉的重要任务,主流方法主要可分为两类,一类利用图像扩散模型分别生成 360 度场景的多个视角。由于图像扩散模型缺乏场景全局结构的先验知识,这类方法无法有效生成多样的 360 度视角,导致场景内主要的目标被多次重复生成,如图 1 的床和雕塑。

图 1. 缺乏场景全局结构的先验知识导致一个卧室出现多张床,一个公园出现多个雕塑。
另一类方法将 360 度场景用一张 Equirectangular Image 来表示,并用 GAN 或扩散模型直接生成。由于该表征的局限性,这类方法通常无法有效完成 360 度闭环(如图 2 每张图片的中间部分),导致 360 度的连接处出现明显的分界线。同时由于缺少大规模训练数据,这类方法有时无法生成复合输入条件的场景。最后,这类方法通常只能接受文字作为输入。

图 2. 现有方法的闭环问题.
为了解决这些问题,来自美国英特尔研究院的 Zhipeng Cai 等人提出了 L-MAGIC(Language Model Assisted Generation of Images with Coherence),通过使用语言模型控制图像扩散模型有效实现高质量、多模态、零样本泛化的 360 度场景生成。L-MAGIC 的 live demo 已被选为英特尔公司 2024 年的 5 个技术突破之一,在 ISC HPC 2024 上展示。该论文已被 CVPR 2024 接收。

方法概览
如图 3 所示,L-MAGIC 是一个结合了语言模型及扩散模型的场景生成框架。L-MAGIC 通过自然图像连接各类不同模态的输入。当输入不是一张自然图像时,L-MAGIC 使用成熟的条件扩散模型如 ControlNet 从各种模态的输入(文字,手绘草图,深度图等等)生成一张自然图像。
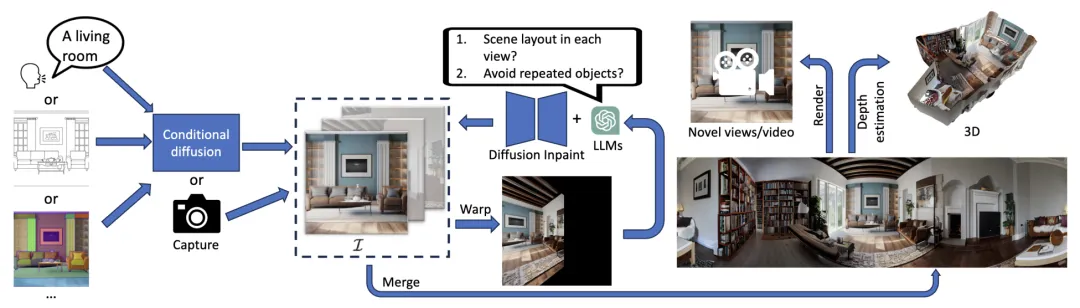
图 3.L-MAGIC 流程图。
在获得自然图像之后,L-MAGIC 通过 iterative warping and inpainting 来生成 360 度场景的多个视角。在每一个 iteration 中,warping step 将已生成的多视角 warp 到一个新的视角,实例中的黑色部分代表新视角中的缺失像素。Inpainting step 使用基于扩散的图像 inpainting 模型(Stable Diffusion v2)生成缺失像素。为了使图像扩散模型能够生成多样的全局场景结构,L-MAGIC 使用语言模型控制扩散模型在每个视角需要生成的场景内容。
除了生成 360 度场景的全景图,利用深度估计模型,L-MAGIC 还能够生成包含相机旋转及平移的沉浸式视频,以及场景的三维点云。由于无需微调,L-MAGIC 能够有效地保持语言及扩散模型的泛化性,实现多样化场景的高质量生成。
L-MAGIC 的核心是使用语言模型全自动地控制扩散模型。如图 4 所示若用户未提供场景的文字描述,L-MAGIC 使用视觉语言模型(如 BLIP-2)基于输入图像获得场景的整体描述(line 2)。
获得场景描述后,L-MAGIC 使用如 ChatGPT 的语言模型(开源代码已支持 ChatGPT-3.5、ChatGPT-4、Llama3),使其根据整体场景描述生成各个视角的描述(line 3),并决定对该场景是否需要防止重复物体的生成(line 5,如树林里各个视角都是树是合理的,但卧室有 5 张床就比较少见,L-MAGIC 利用大语言模型的泛化性能自适应地规避不合理的重复目标)。
由于扩散模型训练数据的 bias,有时扩散模型的输出无法完全符合语言模型的 prompt 要求。为了解决该问题,L-MAGIC 再次使用视觉语言模型监督扩散模型的输出(line 14-18),如果扩散模型的输出不符合语言模型的要求,L-MAGIC 会重新进行当前视角的生成。

图 4. L-MAGIC 算法。
实验结果
如图 5 所示,L-MAGIC 在图像到 360 度场景生成及文字到 360 度场景生成任务中均达到了 SOTA。
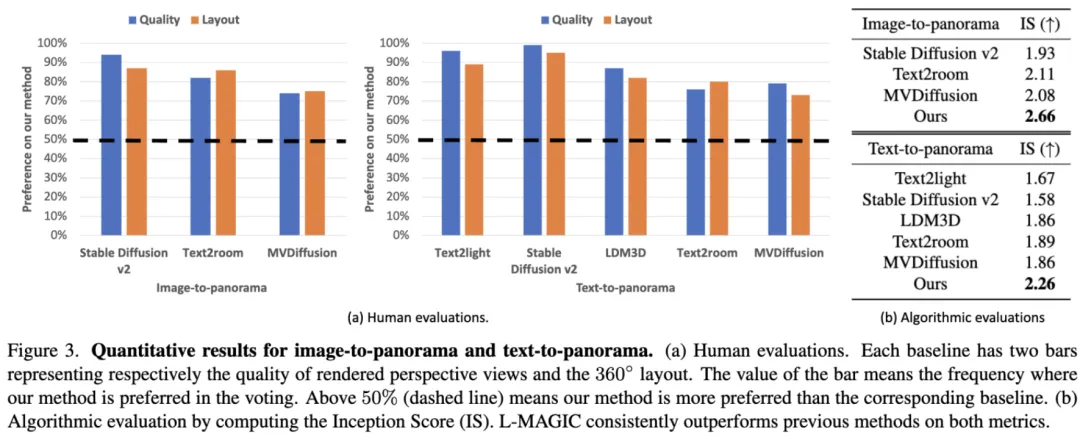
图 5. 定量实验。
如图 6 及图 7 所示,L-MAGIC 在多样的输入及场景下均能够生成具有多样化 360 度场景结构的全景图,并且能够平滑地完成 360 度闭环。

图 6. 图像到 360 度场景生成。

图 7. 文字到 360 度场景生成
如图 8 所示,除了文字及自然图像之外,L-MAGIC 还能够使用 ControlNet 接受多样化的输入,例如深度图、设计草图等。

图 8. 更多不同模态的输入。
通过利用成熟的计算机视觉算法例如深度估计,L-MAGIC 还能够生成场景的沉浸式视频 (见 presentation video)以及三维点云(图 9)。有趣的是,我们能够清晰地分辨海底场景点云中鱼以及珊瑚的几何结构。

图 9. 三维点云生成结果。
文章来源于“机器之心”,作者“蔡志鹏”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
