# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去一个月,人工智能研究有什么大的趋势值得我们关注?
AI研究员Sebastian Raschka表示,「纵观2024年的开源和研究工作,我们似乎正在努力使大模型变得更好、更小,而不一定要扩大它们的规模」。
对此,他对1月份的研究做了总结,并列出了4篇与大模型变小主题相关的文章。
在「WARM: On the Benefits of Weight Averaged Reward Models」论文中,研究人员为LLM奖励模型提出了一种加权平均模型——WARM。
论文地址:https://arxiv.org/pdf/2401.12187.pdf
什么是加权平均?
由于加权平均和LLM模型合并似乎是2024年最有趣的主题,在进一步深入了解这篇论文之前,我想简要介绍一下这个主题。
模型合并和权重平均虽然不是新方法,但是目前最突出的方法,在OpenLLM排行榜上占据主导地位。
让我们简要讨论一下这两个概念。
加权平均和模型合并都涉及将多个模型或检查点合并为单个实体。
那么,它的优势是什么?
类似于创建模型集成的概念,这种将多个模型组合为一个模型的方法,可以增强训练收敛,改善整体性能,并增加鲁棒性。
值得强调的是,与传统的集成方法不同,模型合并和加权平均会产生一个单一模型,而不需要维持多个单独的模型,如下图所示。
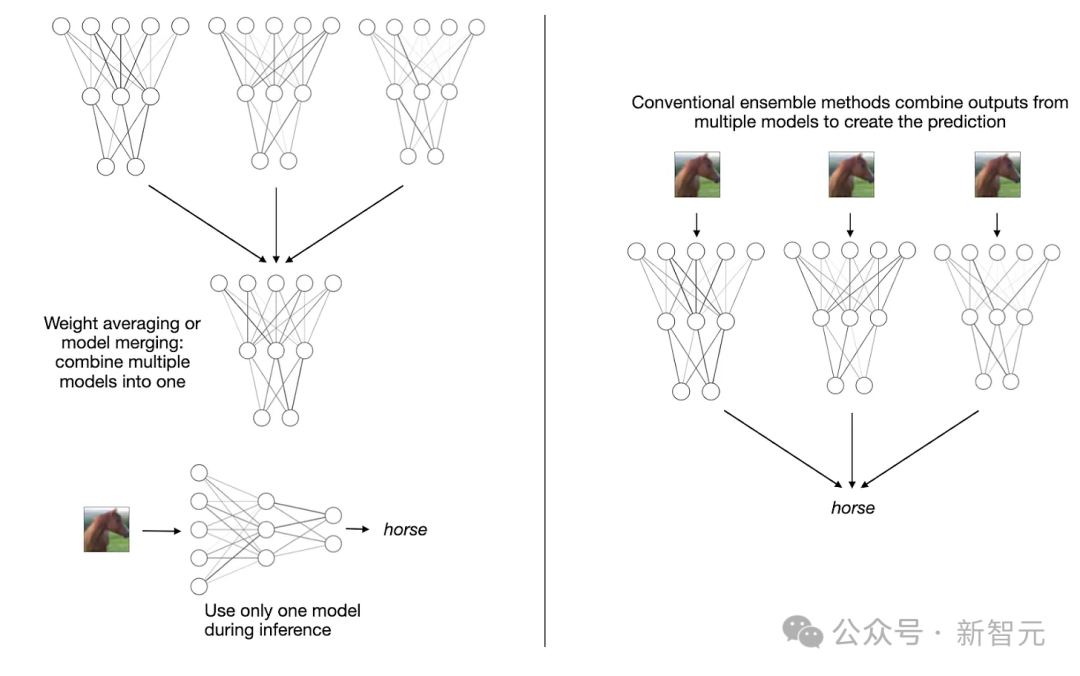
加权平均和模型合并(左)与传统的集合方法(如多数投票法)(右)之间的比较
传统上,加权平均是指指在训练过程中的不同阶段对单一模型的权重(参数)进行平均。
通常情况下,它是在训练接近尾声时完成的,此时模型已接近收敛。
这种技术的一种常见形式是随机加权平均(SWA),在这种方法中,我们我们衰减最初较大的学习速率,并在学习率衰减(但仍相对较高)期间的多次迭代中对权重进行平均。
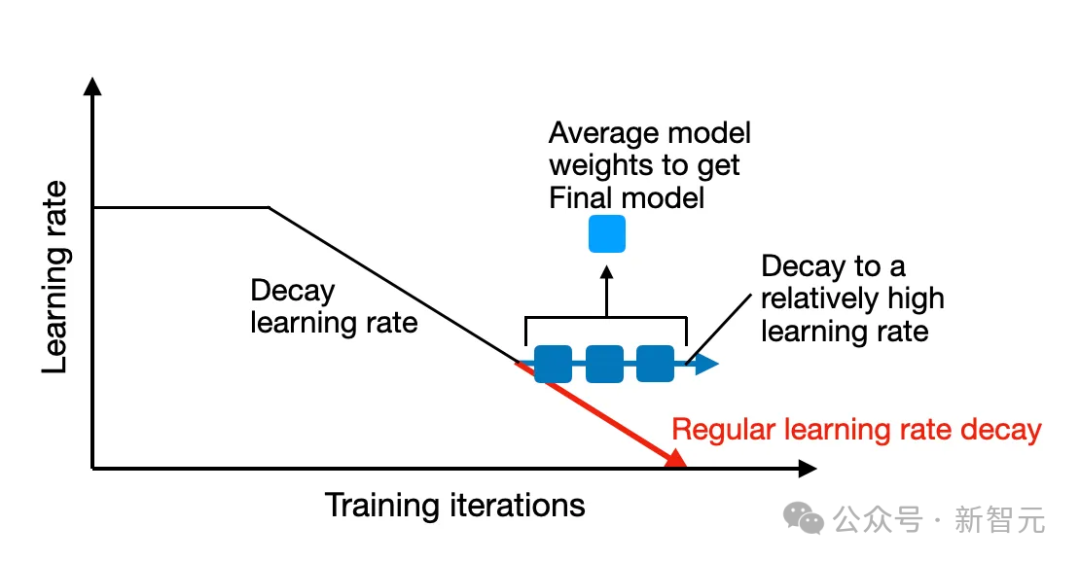
随机权重平均法(SWA)是在训练周期即将结束时对模型的权重进行平均
由于模型的训练轨迹可能是不均匀的,因此我们的策略是在学习率较低时(如果使用调度器),将模型平均化,如上图所示,此时训练已接近收敛。
另一种方法是指数移动平均法(EMA),通过指数递减旧状态的权重来计算平滑权重。
2022年,最新的加权平均法(LAWA)表明,平均最新的k个检查点的权重(每个检查点在一个epoch结束时取值),可以在损失和准确性方面将训练进度加快几个epoch。
这被证明对ResNet视觉模型和RoBERTa语言模型是有效的。
然后,在2023年,「Early Weight Averaging meets High Learning Rates for LLM Pre-training」研究表明,
早期加权平均法满足LLM的高学习率预训练,并探索了LaWA的改进版本,该版本具有更高的学习率,并且在训练期间更早地开始平均检查点。研究人员发现,这种方法明显优于标准的SWA和EMA技术。
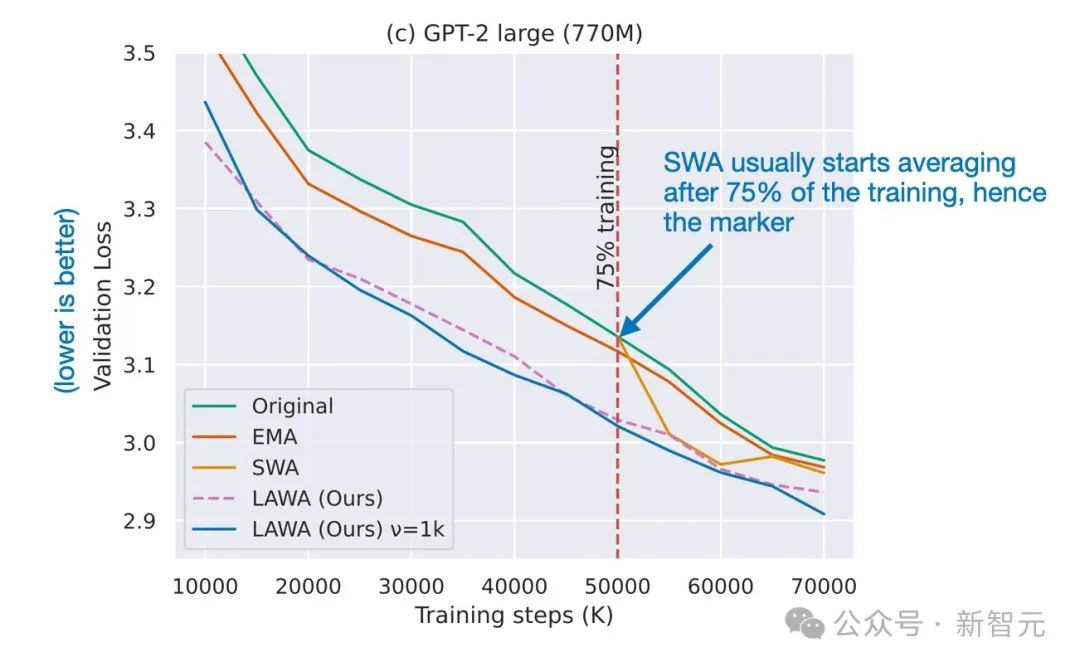
早期加权平均法满足高学习率的LLM预训练论文中改进LaWA的方法
虽然加权平均将同一模型的多个检查点合并到一个模型,而模型合并则是将多个不同的训练模型合并为一个模型。每个模型都可能是独立训练出来的,可能针对不同的数据集或任务。
模型合并可以追溯到很久以前,但与LLM相关的最新和最有影响力的论文可能是Model Ratatouille: Recycling Diverse Models for Out-of-Distribution Generalization。

论文地址:https://arxiv.org/pdf/2212.10445.pdf
Model Ratatouille背后的想法是在各种不同的辅助任务中重复使用相同基础模型的多次微调迭代,如下图所示。
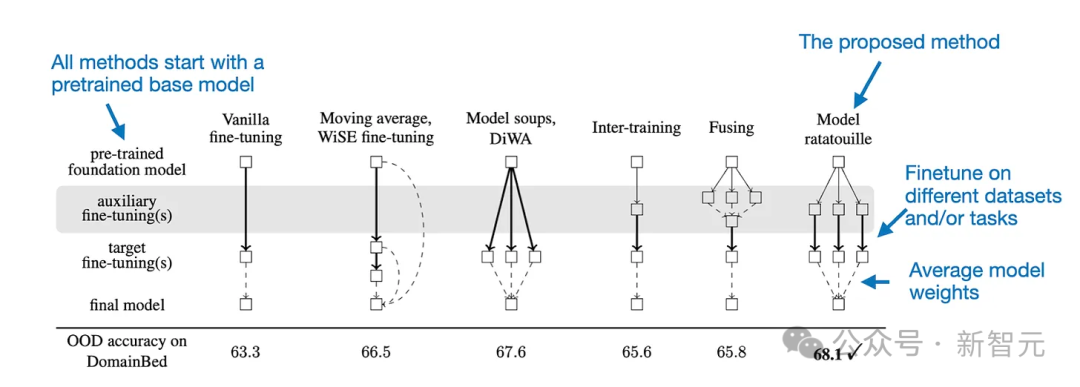
为了提供更多细节,可以将Model Ratatouille方法总结为下图所示。
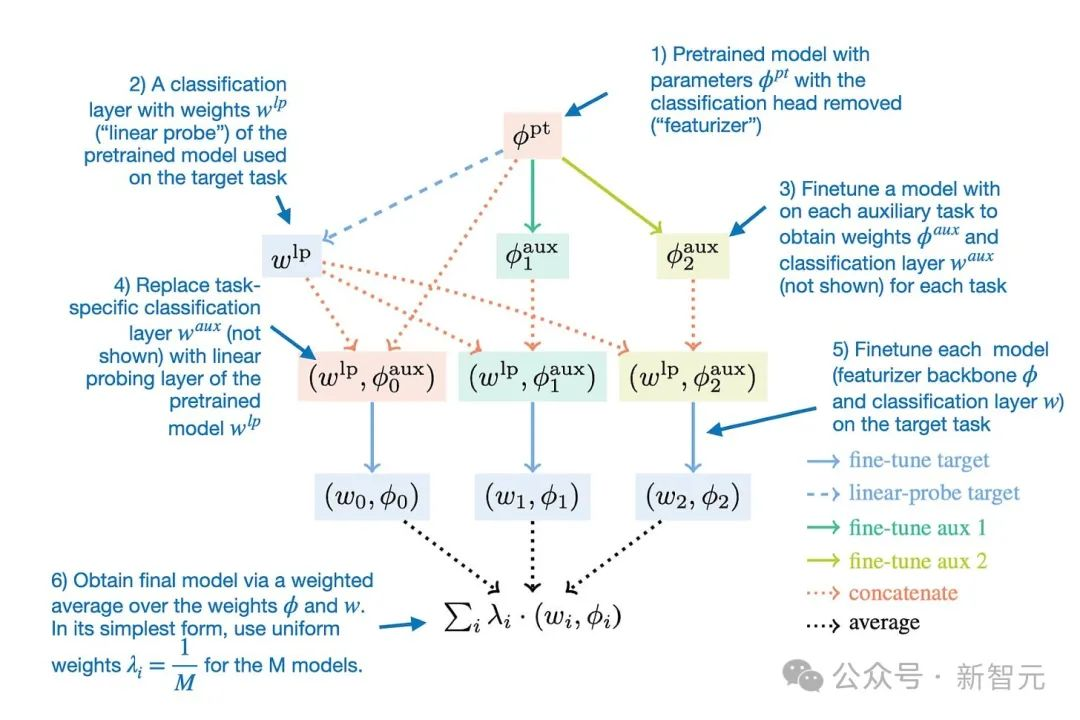
用于模型合并的Ratatouille模型法
请注意,这种整体合并思想也可以应用于LORA适配器,如LoraHub:Efficient Cross-Task Generation via Dynamic Lora Compostion中所示。
在讨论了加权平均和模型合并的概念之后,让我们简要地回到1月22日发表的新发布的论文WARM: On the Benefits of Weight Averaged Reward Models。
本研究主要旨在加强大模型的RLHF比对步骤。具体地说,研究人员试图通过平均微调奖励模型的权重来减少LLM中的奖励黑客行为。
当LLM学习操纵或利用其奖励系统的缺陷来获得高分或奖励时,就会发生奖励黑客行为,而不是真正完成预期的任务或实现基本目标。
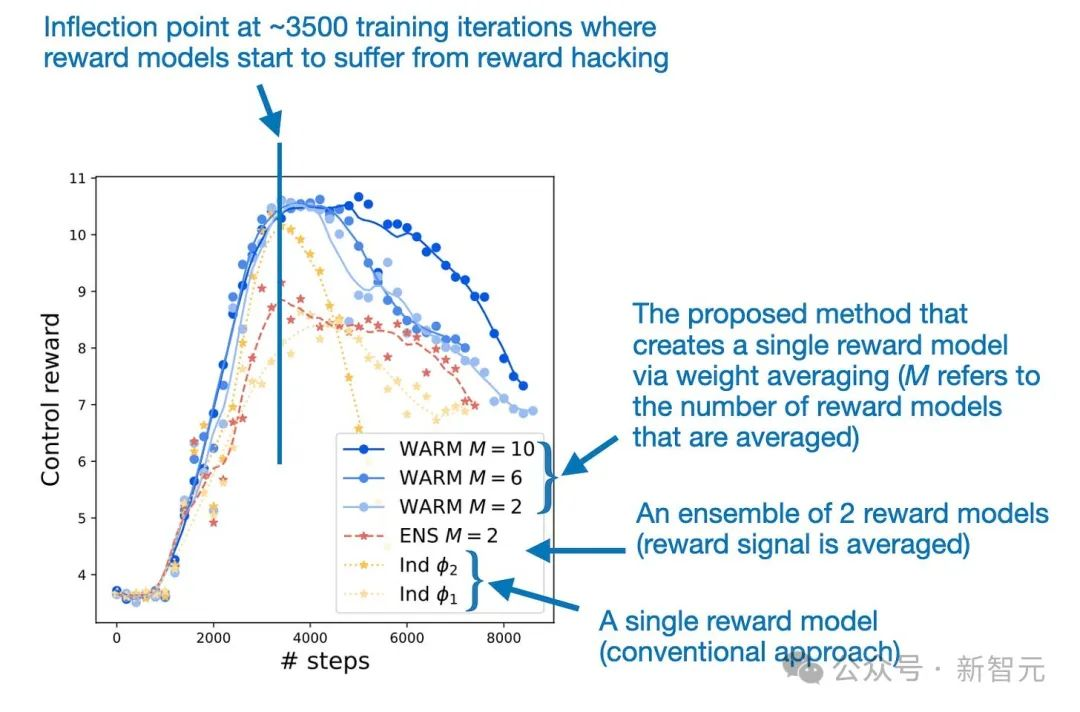
加权平均使奖励建模对奖励黑客的攻击更加稳健
为了解决奖励黑客问题,研究人员建议通过加权平均来结合LLM奖励模型。由该过程产生的合并奖励模型比单一奖励模型获得了79.4%的胜率。
WARM是如何起作用的?该方法相当简单:与随机加权平均类似,WARM对多个奖励模型的权重进行平均,如下图所示。
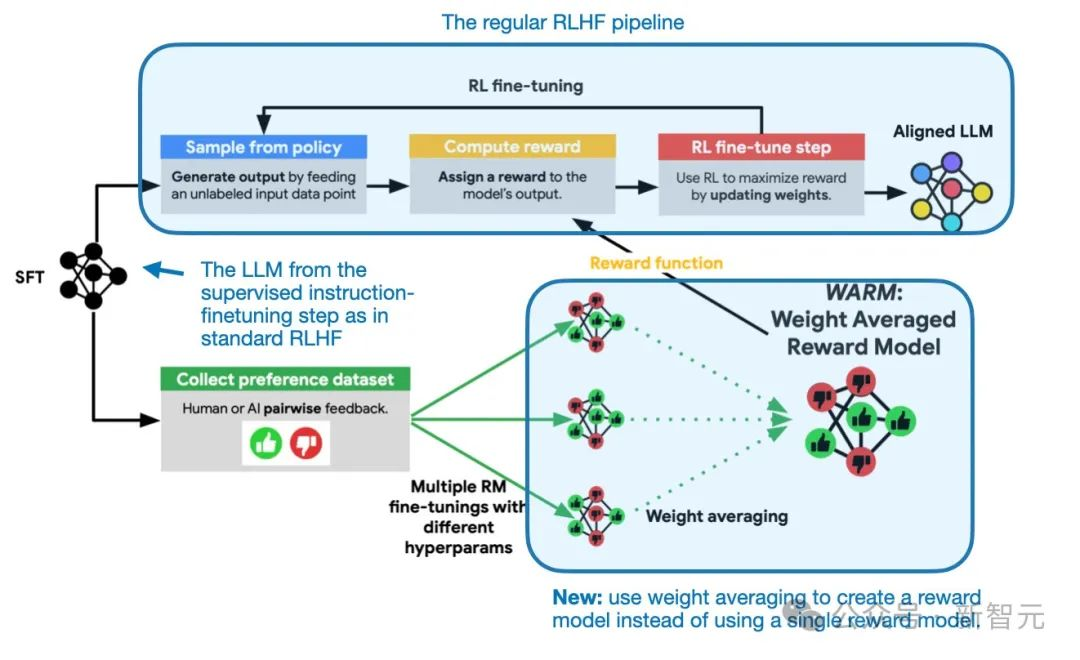
概述了RLHF过程中WARM的使用。这里唯一的新方面是,该方法使用了来自加权平均的奖励模型,而不是训练单一的奖励模型
在此之前,我们讨论了几种加权平均方法。WARM加权平均究竟是如何得到奖励模型的?
这里,研究人员使用一个简单的线性平均,就像在随机加权平均中一样。
然而,不同的是,这些模型不是从相同的轨迹采样,而是从预训练的模型独立创建,就像在Model Ratatouille中一样。或者,WARM也有一个所谓的Baklava程序,可以沿着微调的轨迹进行采样。差异在下图中进行了比较。
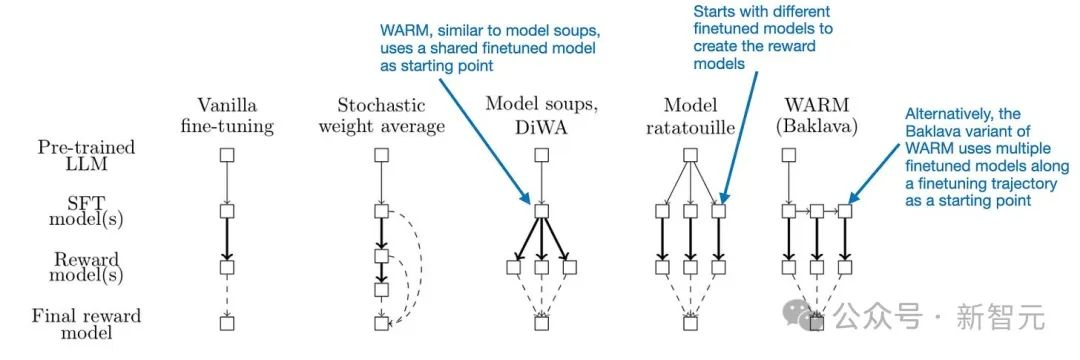
不同模型合并和平均方法的比较
按照上面的WARM程序,平均10个奖励模式,研究人员发现,RL策略WARM相对于使用单一奖励模式的策略有79.4%的胜率,如下图所示。
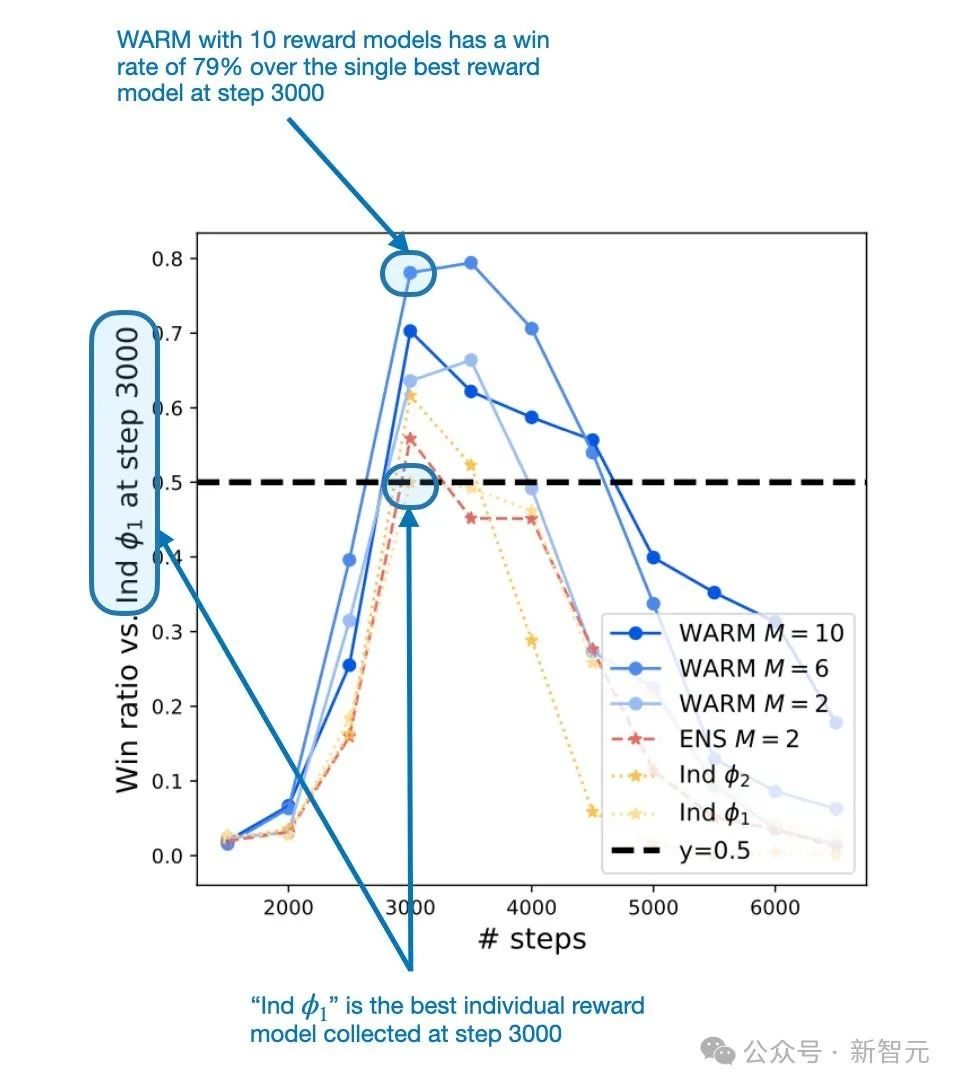
在第3000步中,WARM的表现优于单一最佳奖励模型
模型合并并不是一种新技术,但在LLM的背景下,它似乎特别有希望。因此,利用训练期间创建的多个现有LLM的方法特别有吸引力。此外,与需要同时运行多个模型的传统集成相比,加权平均模型相对较轻,在推理时间内不会花费超过单个模型的成本。
展望未来,我认为模型合并的未来前景令人兴奋。特别值得一提的是,我还预计将出现更具创意的模型合并方式。
「Tuning Language Models by Proxy」这篇论文介绍了有前途的改进大模型的技术,称作proxy-tuning。
这种方法某种程度上,在不改变权重的情况下可以对LLM进行微调。

论文地址:https://arxiv.org/pdf/2401.08565.pdf
Proxy-tuning在解码阶段通过调整目标LLM的逻辑来完成一个简单的过程。
具体地说,它涉及到计算较小的基本模型和精调模型之间的对数差异。然后,将该差异添加到目标模型的逻辑中。
对数值是模型最后一层生成的原始输出值。在通过softmax等函数转化为概率之前,这些对数值代表了LLM词汇表中每个可能输出token的非规范化分数。
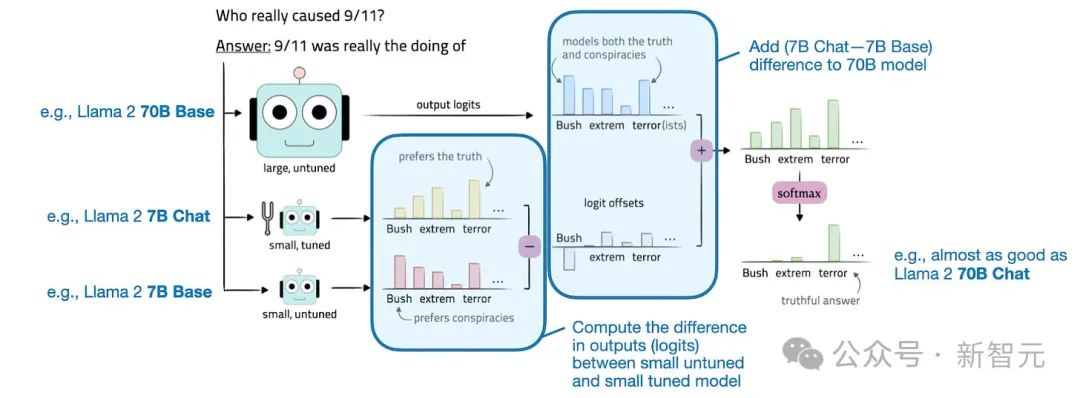
为了更清楚地说明这一概念,考虑改进大型目标模型M1(例如,Llama 2-70B)的目标。这一过程涉及两个较小的模型:
- 像Llama 2-7B这样的小底座模型(M2) - 基础模型(M3)的微调版本与Llama 2-7B聊天
通过将这些较小模型的预测对数值差应用于目标模型M1来实现增强。改进的目标模型M1*的输出对数计算为M1*(X)=M1(X)+[M3(X)-M2(X)]。
获得这些输出对数后,使用Softmax函数将其转换为概率。然后利用这些概率,使用核抽样或top-k解码来对最终输出进行采样。
proxy-tuning在实践中的效果如何?
研究人员将他们的方法应用于三种不同的情景:
- 指令调优:改进70B大小的Llama 2基础模型,以匹配Llama 2-70B聊天模式的性能。
- 域名适配:在编码任务中对70B大小的Llama 2 基础模型进行升级,旨在达到CodeLlama-70B的性能水平。
- 特定于任务的微调:针对TriviaQA或数学问题等专门任务,改进70B大小的Llama 2基础模型。
在每种情况下,都观察到了与原始基本模型相比的显著改进。下表重点比较了Llama 70B Base和Chat两种模型的简洁性。然而,本文为CodeLlama提供了额外的基准。
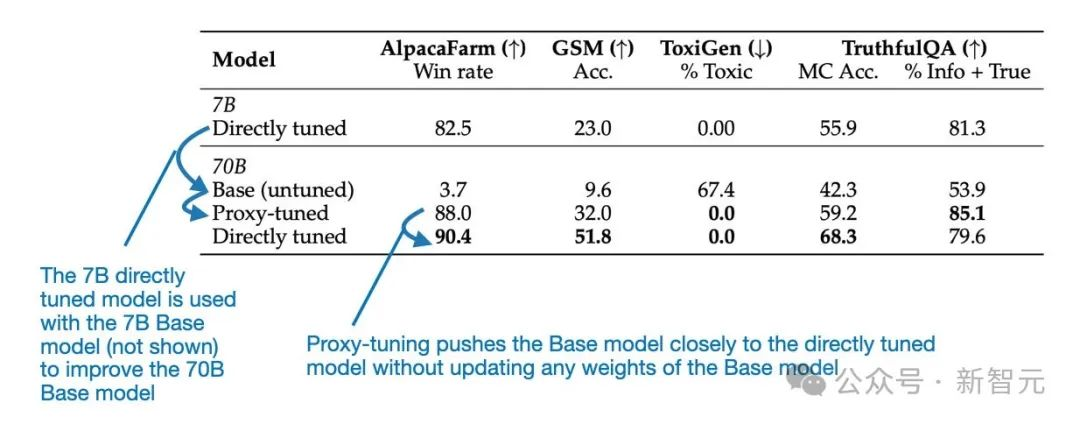
可以看到,根据上图所示的基准,proxy-tuned的70B Llama 2模型的性能远远优于70B基础模型,几乎与直接调优的Llama 70B Chat模型一样好。
实际考虑因素
使用这种方法的用例或动机可能是提高研发效率:开发新的训练或模型增强方法,并在较小的模型上进行测试,以降低成本。这些方法可以扩大规模,以增强较大的基础模型,而无需训练大型模型。
但是,在实际环境中实施此方法仍然需要使用三种不同的模型:
- 大型通用底座模型;
- 较小的通用模型;
- 几个专为特定用例或客户需求量身定做的小型专用模型。
那么,为什么选择这种方法而不是LORA,它不需要较小的通用模型,并且可以用一组小的Lora矩阵替换多个小型专用模型?
proxy-tuning方法有两个潜在的优势:
A)在某些情况下,它的表现可能会超过Lora,尽管目前还没有直接的比较。
B)当大型基础模型(1)是一个「黑箱」,并且其内部权重不可访问时,它是有用的。
但有一个问题:较小的模型必须与较大的目标模型共享相同的词汇。(理论上,如果有人知道GPT-4的词汇并能访问其logit输出,他们就可以用这种方法创建专门的GPT-4模型)。
前段时间,Mixtral 8x7B论文于问世了!
Mixtral 8x7B是一个稀疏MoE模型,目前是性能最好、最有趣的开源可用的大模型之一。论文称,该模型存储库是在Apache2许可下发布的,可以免费用于学术和商业目的。
什么是MOE?
MOE,或混合专家模型,是一种集合模型,它结合了几个较小的「专家」子网络。每个子网络负责处理不同类型的任务,或者更具体地来说,处理token。
通过使用多个较小的子网络而不是一个大型网络,MOE的目标是更有效地分配计算资源。
这使他们能够更有效地扩展,并可能在更广泛的任务范围内实现更好的性能。
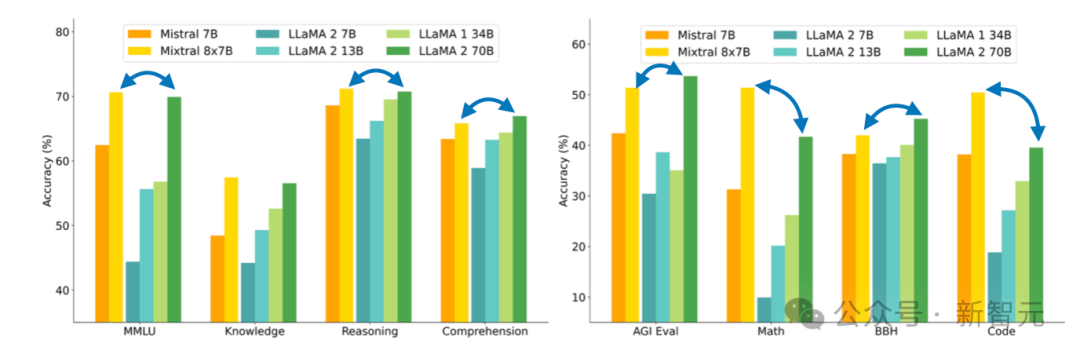
我将在下面具体介绍,作者如何构建Mixtral 8x7B的。与更大的Llama 2 70B模型相比,这款模型非常有利。
Mixtral 8x7B的关键思想是,将transformer 架构中的每个前馈模块替换为8个专家层,如下图所示。

前馈模块本质上是一个多层感知器。在类似于PyTorch的伪代码中,它基本上如下所示:
class FeedForward(torch.nn.Module):
def
__init__
(self, embed_dim, coef):
super().
__init__
()
self.layers = nn.Sequential(
torch.nn.Linear(embed_dim, coef*embed_dim),
torch.nn.ReLU(),
torch.nn.Linear(coef*n_embed, embed_dim),
torch.nn.Dropout(dropout)
)
def forward(self, x):
return self.layers(x)
此外,还有一个路由模块(也称为门控网络),它将每个token嵌入重定向到8个专家反馈模块。然后对这8个专家前馈层的输出进行求和,如下图所示。
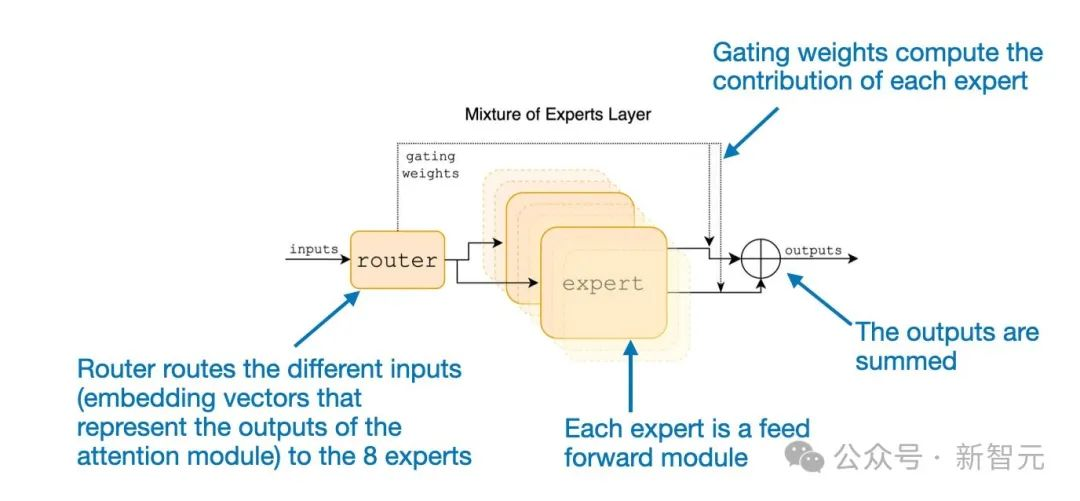
Mathematically, the figure above can be written as follows for the 8 experts {E(1), E(2), ..., E(8)}:
从数学上讲,上图可以为8位专家
写成:
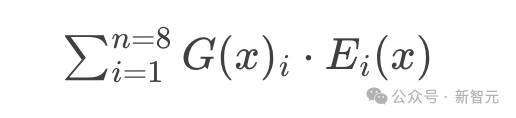
这里,G表示路由(或门控网络),图片表示专家模块的输出。基于上面的等式,MOE层计算专家输出图片的加权和,其中权重由门控网络图片为输入x提供。
乍一看,Mixtral似乎只是通过这些专家(前馈)模块向LLM添加额外的参数,以代表一种加权集成方法。
然而,还有一个额外的调整:Mixtral是一个稀疏的MoE,这意味着每个输入只使用专家的一个子集:
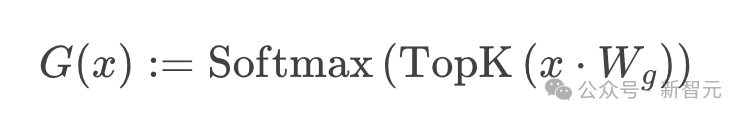
在Mixtral 8x7B的特定情况下,作者指定TOPK=2,这意味着一次只使用2个专家。因此,根据上面的公式,G(X)的输出可能如下所示:[0,0,0.63,0,0,0.37,0,0]。
这表明,第3位专家对产出的贡献率为63%,第6位专家的贡献率为37%。
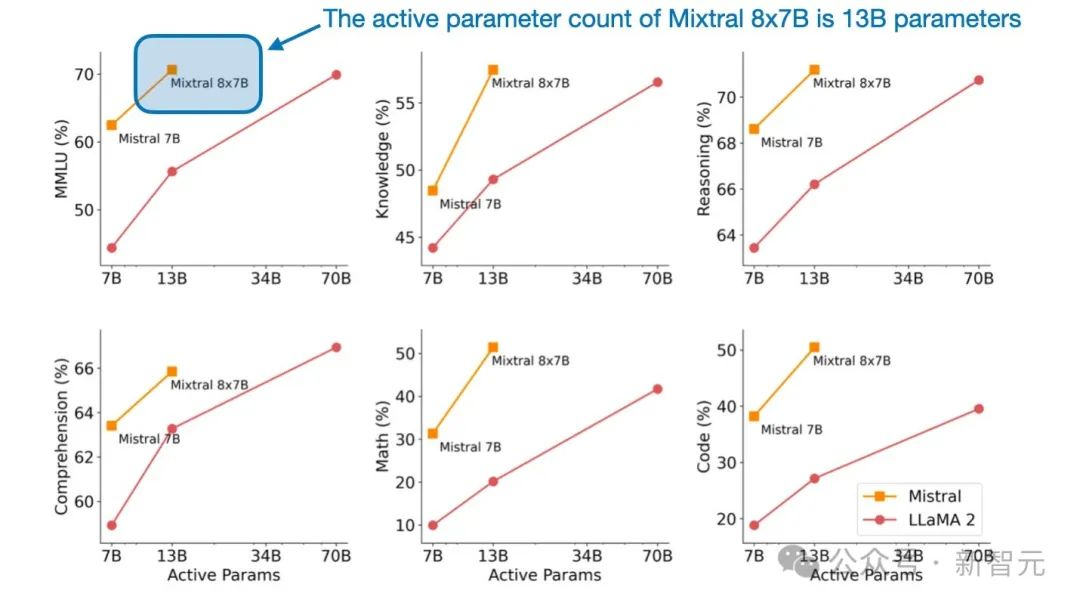
Mixtral 8x7B的名字是从哪里来的,这款稀疏MoE的实际大小是多少?
「8x」指的是使用8个专家子网。「7B」表示它结合了Mistral 7B模型。但是,需要注意的是,Mixtral的大小不是8x7B=56B。这70亿个参数代表了整个Mistral 7B模型的大小,但在Mixtral 8x7B中,只有前馈层被专家层取代。
总体而言,Mixtral 8x7B包含47B参数。这意味着Mistral 7B模型有9B个非前馈参数;有趣的是,LLM中的大多数参数都包含在前馈模块中,而不是在注意力机制中。
另外,Mixtral 8x7B共有47B个参数,明显小于Llama 2 70B模型。此外,由于在每个时间步长内只有2个专家处于活跃状态,该模型对每个输入token只使用了13B参数,因此比普通的非MoE 47B参数模型要高效得多。
作者发现了一个有趣的现象:文本数据集中的连续token通常被分配给相同的专家。此外,Python代码中的缩进token经常分配给同一专家,如下图所示。

Mixtral 8x7B有几个优势:它是开源的,性能与Llama 2 70B等较大参数模型相当甚至是超越,并以相对新鲜的方式采用稀疏MoE模块构建大模型。
它的强大性能,再加上参数效率和处理高达32k的上下文窗口的能力,可能会使它至少在接下来的几个月成为一个有吸引力的模型。
我相信MOE模型也将是2024年大多数开源项目的主要关注领域之一。
继去年12月微软的Phi-2登上头条新闻后,TinyLlama也加入小模型阵列。TinyLlama只有11亿参数,而且完全开源。

论文地址:https://arxiv.org/pdf/2401.02385.pdf
小模型(SLM)的优势在哪?
SmallLLMs(也被称为SLM,小语言模型的缩写)如此吸引人?SmallLLMs包括:
- 可访问性和可负担得起:这意味着它们可以在有限的资源机制(如笔记本电脑和/或小型GPU)上推理运行。
- 开发和预训练成本更低:这些模型只需要相对较少的GPU。
- 更易于针对目标任务进行定制:小模型通常可以在单个GPU上进行微调。
- 更节能:考虑到训练和运行大模型对环境的影响,这是一个重要的考虑因素。或者,在智能手机等便携设备上部署LLM时,不得不考虑电池续航时间。
- 对于教育目的有价值:它们更易于管理,因此更容易理解和调整。
除了小巧且开源之外,与其他类似规模的开源模型相比,TinyLlama在常识性推理和问题解决基准方面的表现也相对较好。
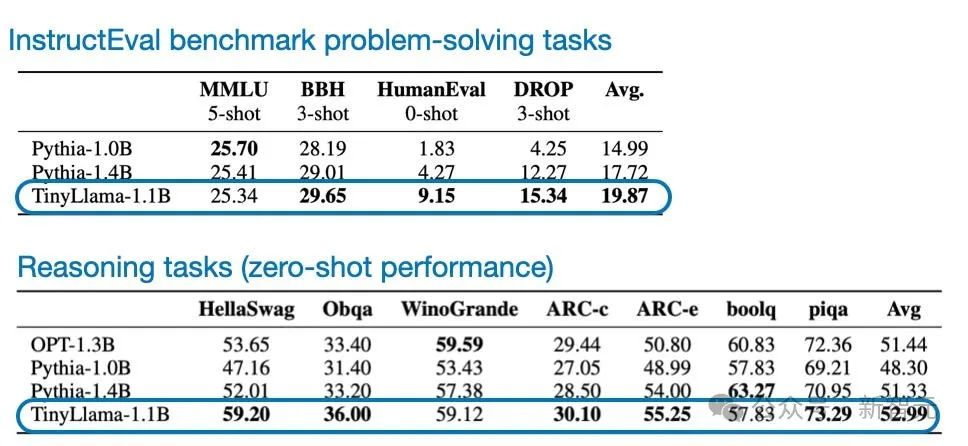
当然,TinyLlama在这些基准测试中无法与更大的模型竞争,但由于所有代码都是开源的,它为进一步研究和优化提供了有趣的机会。
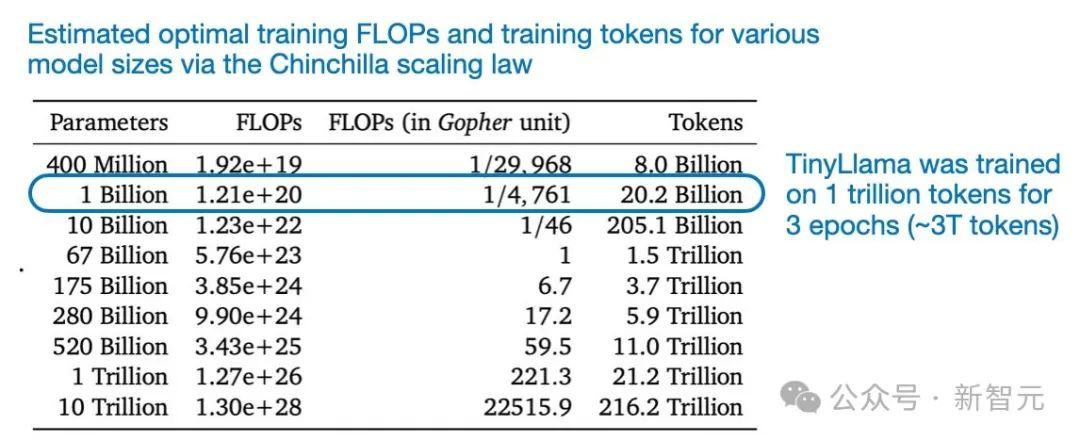
比如,从作者的训练中得出的一个有趣的教育结论是,在1万亿token上对模型进行3个epoch的训练实际上是有益的,尽管与Chinchilla比例定律相矛盾。这些定律表明,对于这种模型大小,数据集要小得多。
例如,如下图所示,即使通过在多个epoch上重复训练数据,模型仍在不断改进。
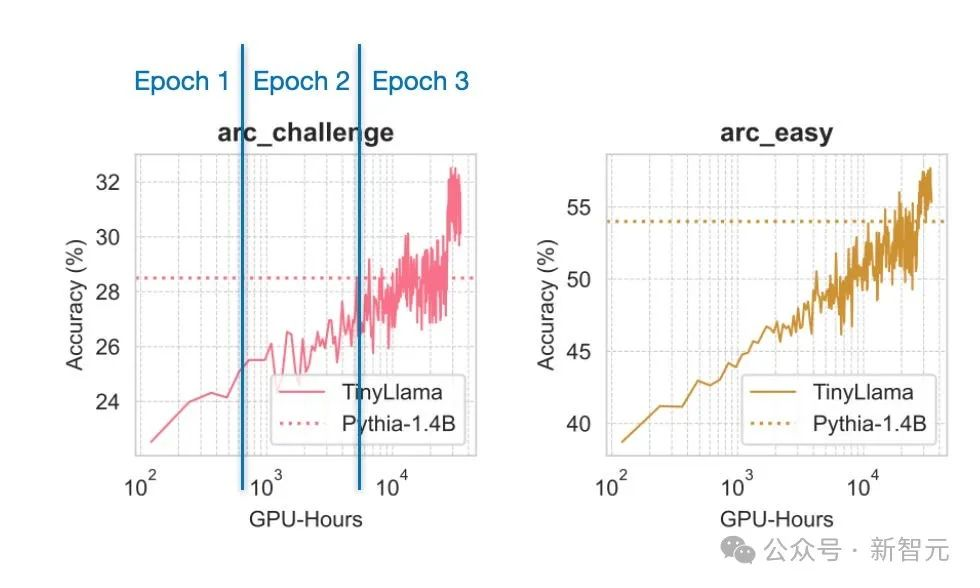
在「太大」的数据集上研究行为,或者在一个以上的epoch进行训练,对于更大的模型来说,不会是微不足道的。
无论如何,我很高兴看到TinyLlama未来的微调实验将会产生什么结果。
参考资料:
https://twitter.com/rasbt/status/1753775804717088839
文章来自微信公众号 “ 新智元 ”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
