# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一直以来,让 AI 成为手机操作助手都是一项颇具挑战性的任务。在该场景下,AI 需要根据用户的要求自动操作手机,逐步完成任务。
随着多模态大语言模型(Multimodal Large Language Model,MLLM)的快速发展,以 MLLM 为基础的多模态 agent 逐渐应用于各种实际应用场景中,这使得借助多模态 agent 实现手机操作助手成为了可能。
本文将介绍一篇最新的利用多模态 agent 实现 AI 操作手机的研究《Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception》。

能力展示
首先为大家介绍 Mobile-Agent 可以自动做哪些有趣的任务。
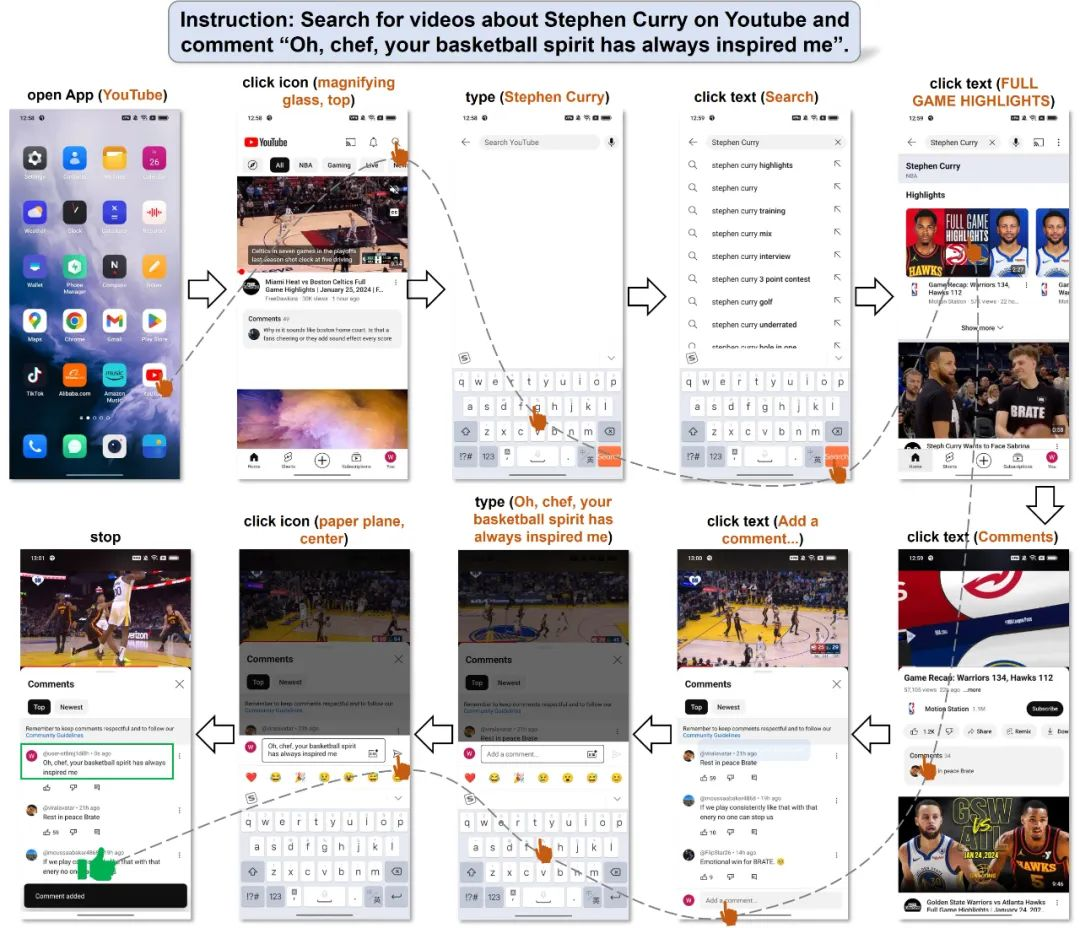
下面是一个在 YouTube 里找相关视频并发表评论的例子,用户的要求是在 YouTube 里搜索视频,找到一个和某个明星相关的视频,然后发表评论。在整个过程中,Mobile-Agent 没有出现任何错误、不必要或无效的操作,完美地完成了任务。
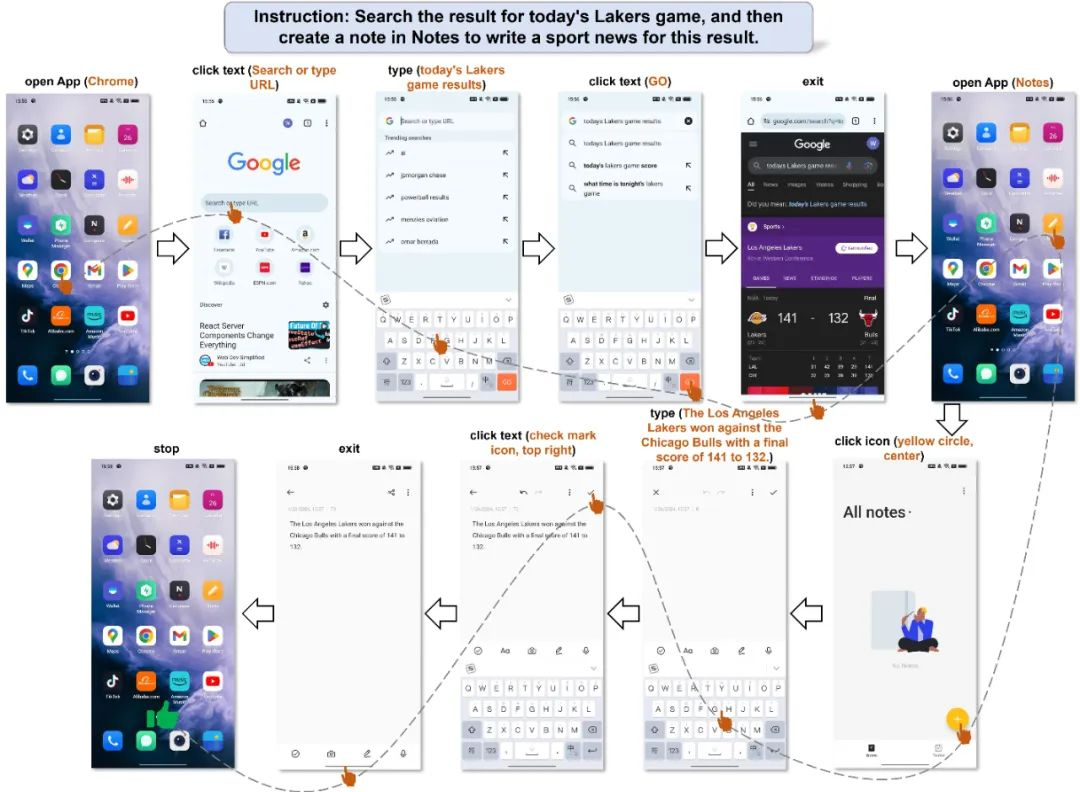
接下来是一个操作多 App 的例子,用户的要求是先去查询今天的比赛结果,然后根据结果写一个新闻。这个任务的挑战性在于,前后要使用两个 App 完成两个子任务,并且需要将第一个子任务的结果作为第二个子任务的输入。Mobile-Agent 首先完成了查询比赛结果,随后退出浏览器并打开笔记,最后将比赛结果精准地写出,并以新闻的方式呈现。
最后展示一个短视频平台评论的例子,用户的需求是在短视频平台中刷视频,如果刷到了宠物猫相关的视频,就点一个喜欢。在该例子中,Mobile-Agent 出现了两次错误的操作(红色字体指示),然而 Mobile-Agent 及时感知到了错误并且采取了补救措施,最终也完成了任务。

从上述的例子中可以看出,Mobile-Agent 有以下三个能力:
(1)操作定位。对于需要点击特定图标和文本的操作,Mobile-Agent 能够准确点击到对应的位置。
(2)自我规划。根据用户指令和当前屏幕截图,Mobile-Agent 能够自动规划每一步的任务,直到任务完成。
(3)自我反思。如果出现了错误操作或者无效操作,Mobile-Agent 能够及时发现问题并进行补救。
方法
这里详细介绍一下 Mobile-Agent 的设计思路,展示上述三个能力是如何实现的。
操作空间
为了便于将文本描述的操作转化为屏幕上的操作,Mobile-Agent 生成的操作必须在一个定义好的操作空间内。这个空间共有 8 个操作,分别是:
其中,点击文本和点击图标是两个需要操作定位的操作,因此 Mobile-Agent 在使用这两个操作时,必须输出括号内的参数,以实现定位。
操作定位
在大多数情况下,MLLM 已经具备基本的操作手机的能力,在提供手机截图和用户指令后,这些模型往往能够生成正确的操作。然而,MLLM 的操作定位能力十分有限,这体现在:虽然 MLLM 可以产生正确的操作,但当要求 MLLM 输出这些操作将要在屏幕上发生的位置时,MLLM 往往无法提供准确的坐标。现有工作表明,即使是最先进的 GPT-4V,也无法提供准确的操作坐标。
虽然仅通过 MLLM 无法实现自动化操作,但是我们可以利用 MLLM 产生的正确操作,通过额外的操作定位工具实现操作定位。在 Mobile-Agent 中,一共使用了两种视觉感知工具,分别是文字识别模块和图标识别模块,如下图所示:
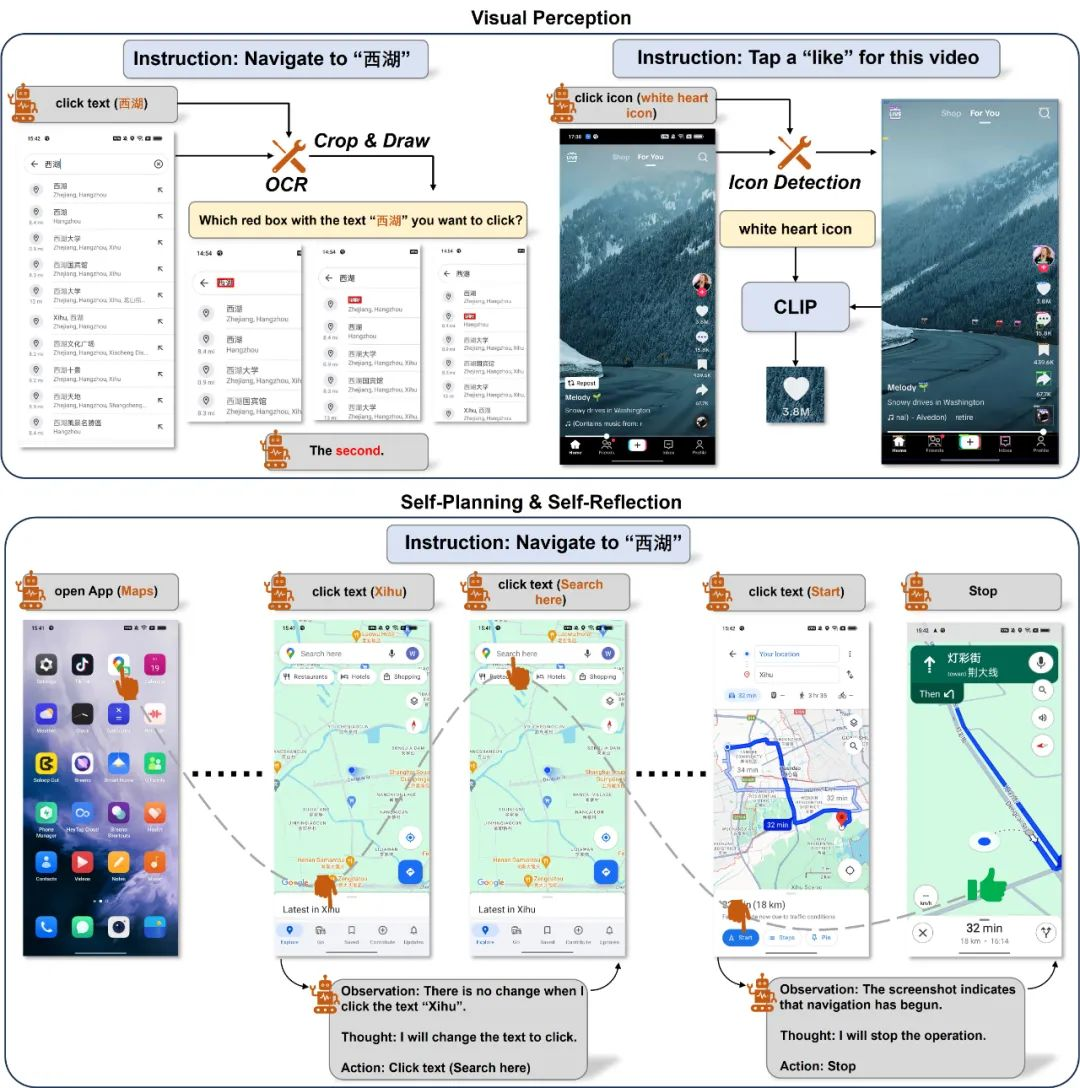
对于文本定位,Mobile-Agent 借助 OCR 工具来定位出指定文本。如果指定文本在屏幕中多次出现,则会将这些区域裁剪出来并绘制检测框,OCR 工具返回的多个区域将会以多图输入的方式重新做一次选择。对于图标定位,Mobile-Agent 首先借助检测模型,使用检测词 “图标” 将屏幕中所有图标区域裁剪出来,随后根据 Mobile-Agent 提供的图标描述,利用 CLIP 计算这些裁剪区域于描述的相似度,并选择最高的区域作为点击的坐标。
自我规划
Mobile-Agent 以迭代方式完成每一步操作。在迭代开始之前,用户需要输入一个指令。我们根据指令生成整个流程的系统提示。在每次迭代开始时,Mobile-Agent 会获取手机屏幕的截图,通过观察系统提示、操作历史和当前屏幕截图,输出下一步操作。如果 Mobile-Agent 输出的是结束,则停止迭代;否则,继续新的迭代。Mobile-Agent 利用操作历史记录了解当前任务的进度,并根据系统提示对当前屏幕截图进行操作,从而实现迭代式自我规划流程。
自我反思
在迭代过程中,Mobile-Agent 可能会遇到错误,导致无法完成指令。为了提高指令的成功率,Mobile-Agent 引入了一种自我反思方法。这种方法将在两种情况下生效。第一种情况是生成了错误或无效的操作,导致进程卡住。当 Mobile-Agent 注意到某个操作后截图没有变化,或者截图显示了错误的页面时,它会尝试其他操作或修改当前操作的参数。第二种情况是忽略某些复杂指令的要求。当通过自我规划完成所有操作后,Mobile-Agent 会分析操作、历史记录、当前截图和用户指令,以确定指令是否已完成。如果没有,它需要继续通过自我规划生成操作。
实验
Mobile-Eval
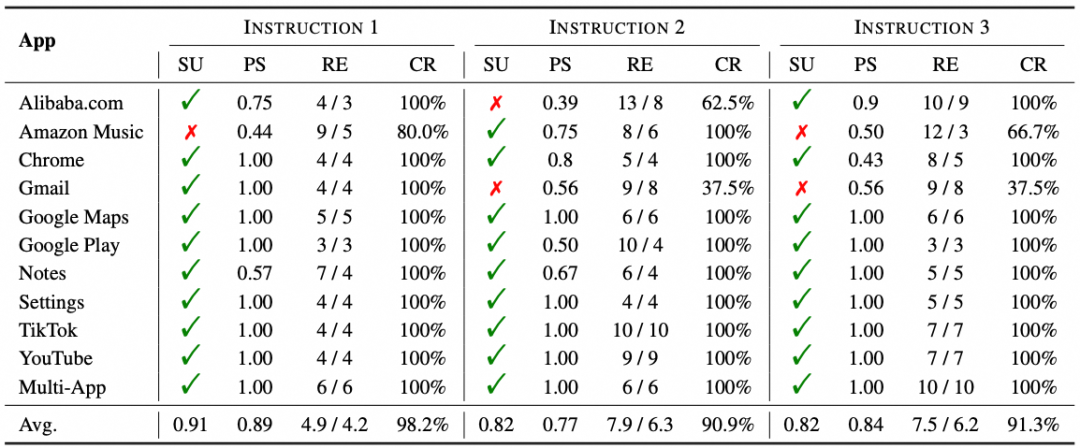
为了全面评估 Mobile-Agent 的能力,作者引入了 Mobile-Eval,这是一个基于当前主流应用程序的 benchmark。Mobile-Eval 共包含 10 个移动设备上常用的应用程序。为了评估多应用程序使用能力,作者还引入了需要同时使用两个应用程序的指令。作者为每个应用程序设计了三种指令。第一条指令相对简单,只要求完成基本的应用程序操作。第二条指令在第一条指令的基础上增加了一些额外要求,使其更具挑战性。第三条指令涉及抽象的用户指令,即用户不明确指定使用哪个应用程序或执行什么操作,让 agent 自己做出判断。下面的表中介绍了 Mobile-Eval 中使用的应用程序和指令。

实验结果
下表中展示了 Mobile-Agent 的评测结果。其中 SU 代表指令是否完成,PS 代表正确操作占所有操作的比例,RE 代表 Mobile-Agent 和人类完成指令时分别用了多少步,CR 是 Mobile-Agent 能够完成的操作占人类操作的百分比。在 3 种指令上,分别达到了 91%、82% 和 82% 的成功率,在完成度上,3 种指令都达到了 90% 以上,并且 Mobile-Agent 可以达到 90% 人类的效果。值得注意的是,虽然 PS 平均只有 85% 左右,但是在总共的 33 个任务上,Mobile-Agent 能够完成 28 个,这也说明了自我反思的重要性,即使会出现错误操作,也能够及时发现并纠正,最终完成任务。
其他能力
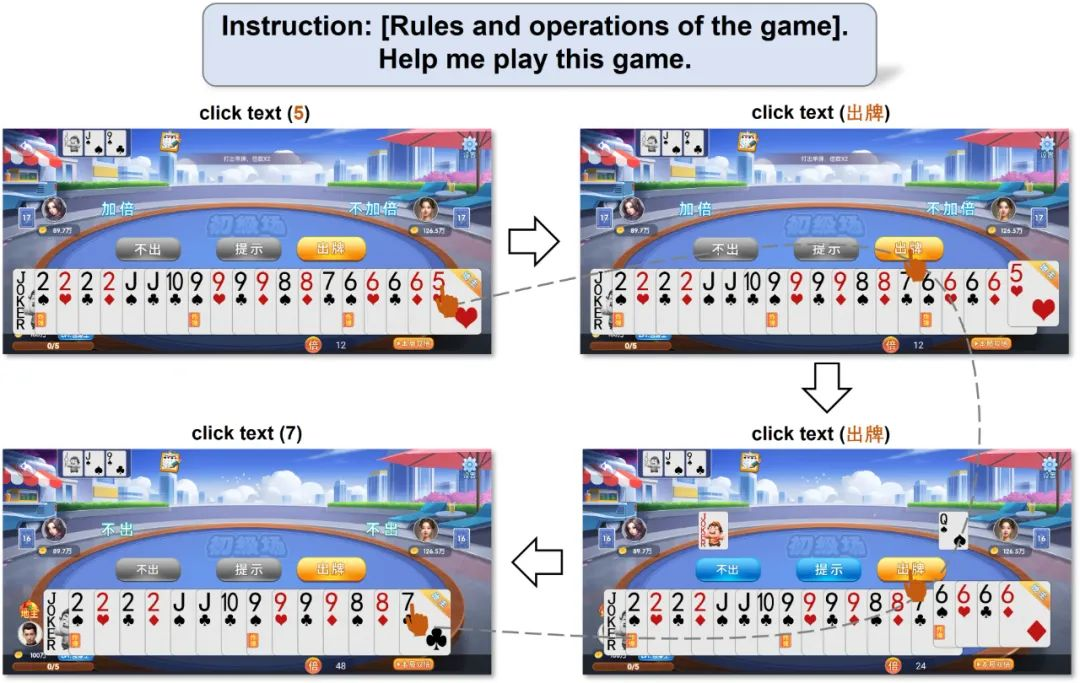
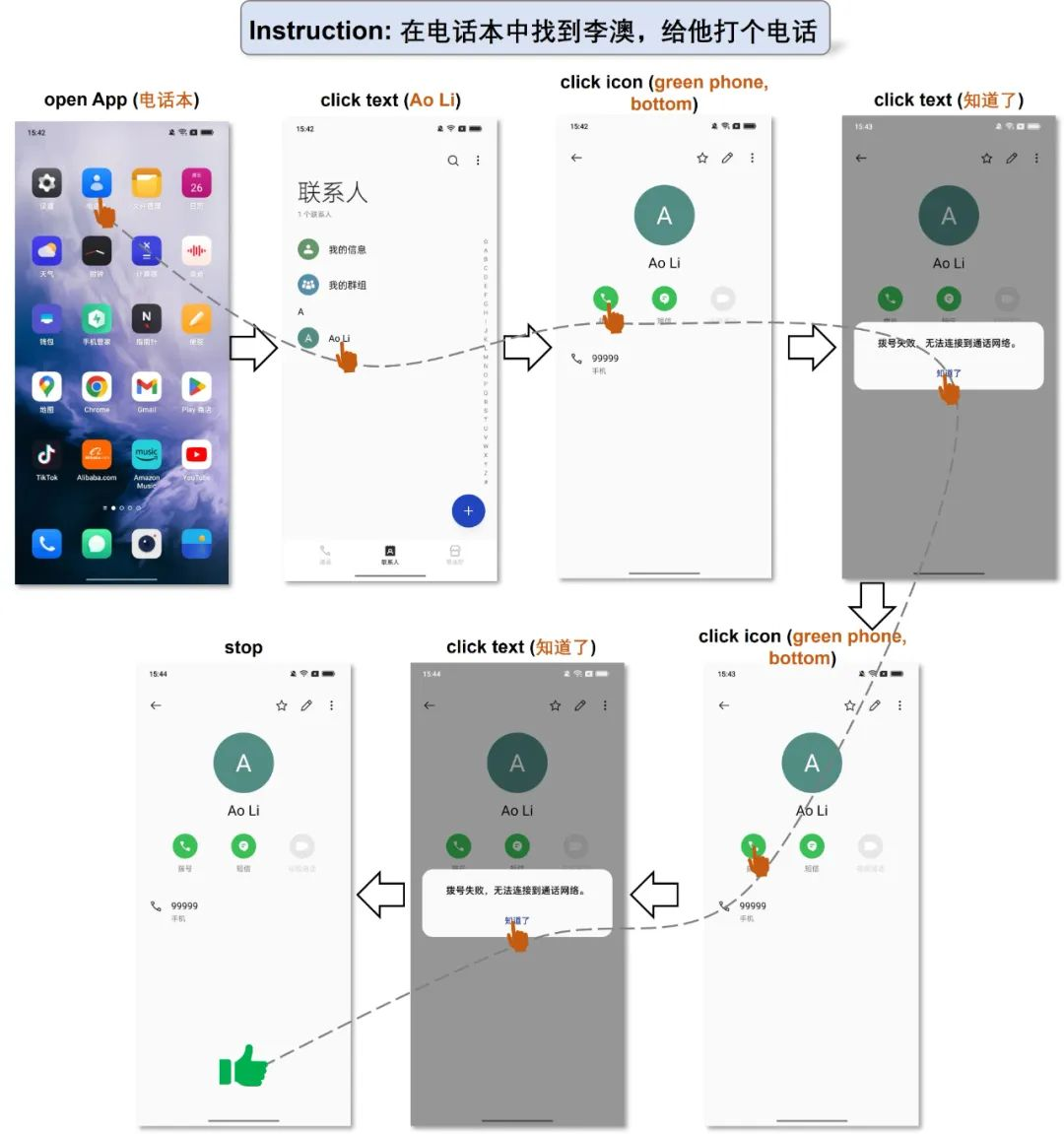
下面两个例子展示了中文场景下的表现。虽然 GPT-4V 在中文识别上还有待加强,但是在文字不多的简单场景下 Mobile-Agent 也可以完成任务。
文章来自于微信公众号 “机器之心”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
