
爱思唯尔把Meta告了:拿Sci-Hub盗版论文训练大模型
爱思唯尔把Meta告了:拿Sci-Hub盗版论文训练大模型AI版权大战,再度升级了。
来自主题: AI资讯
7643 点击 2026-05-13 15:23
 搜索
搜索
AI版权大战,再度升级了。
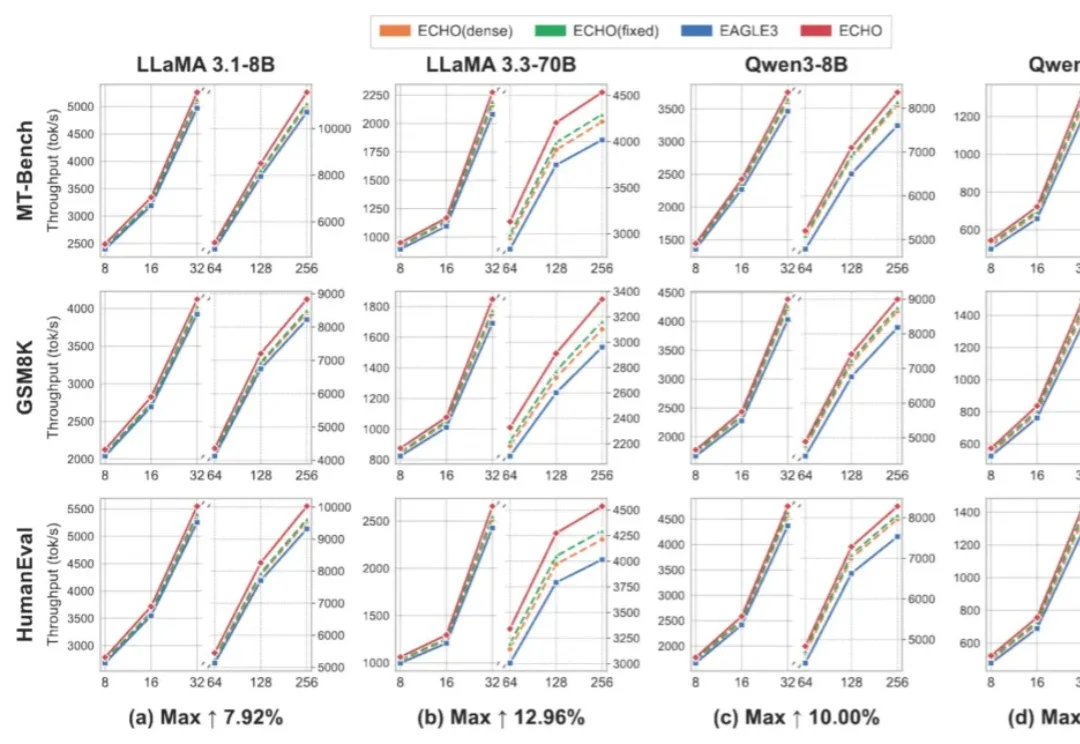
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

家用电器是家庭服务机器人最难啃的一类任务对象。与桌面物体操作相比,家电操作不仅涉及按钮、旋钮、门体等多种异构部件,还受到模式切换、状态约束和程序逻辑的共同支配。真正完成一次家电任务,机器人往往既要「看得见」,也要「读得懂」,还要「按说明书做对」。
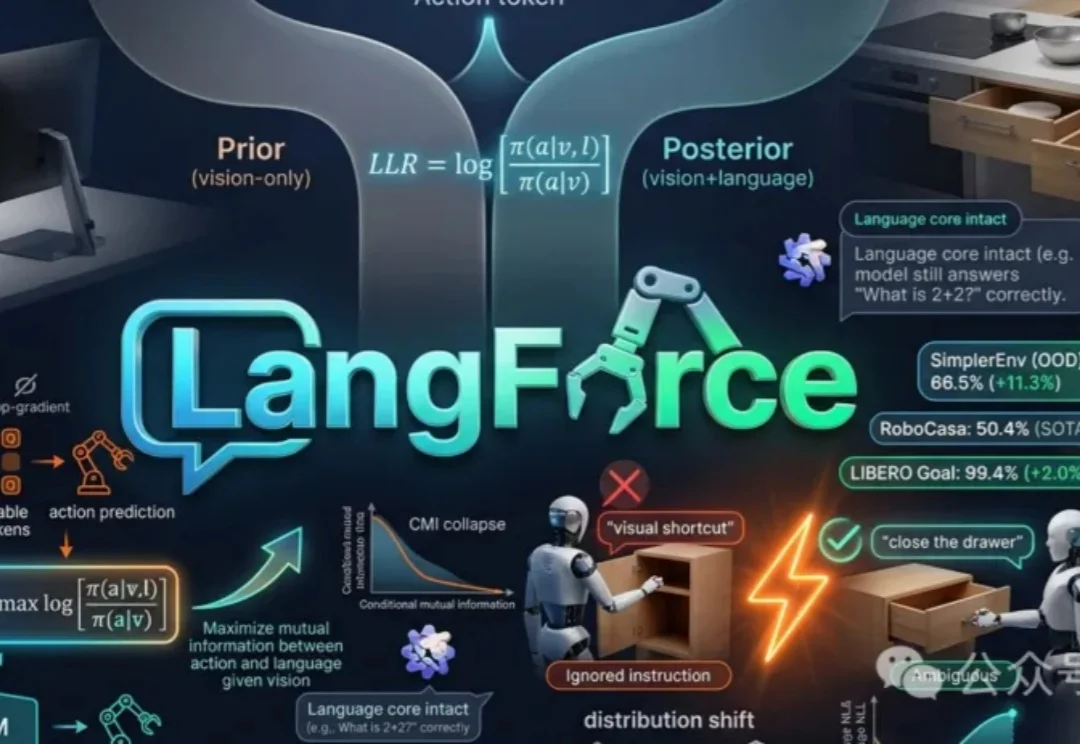
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
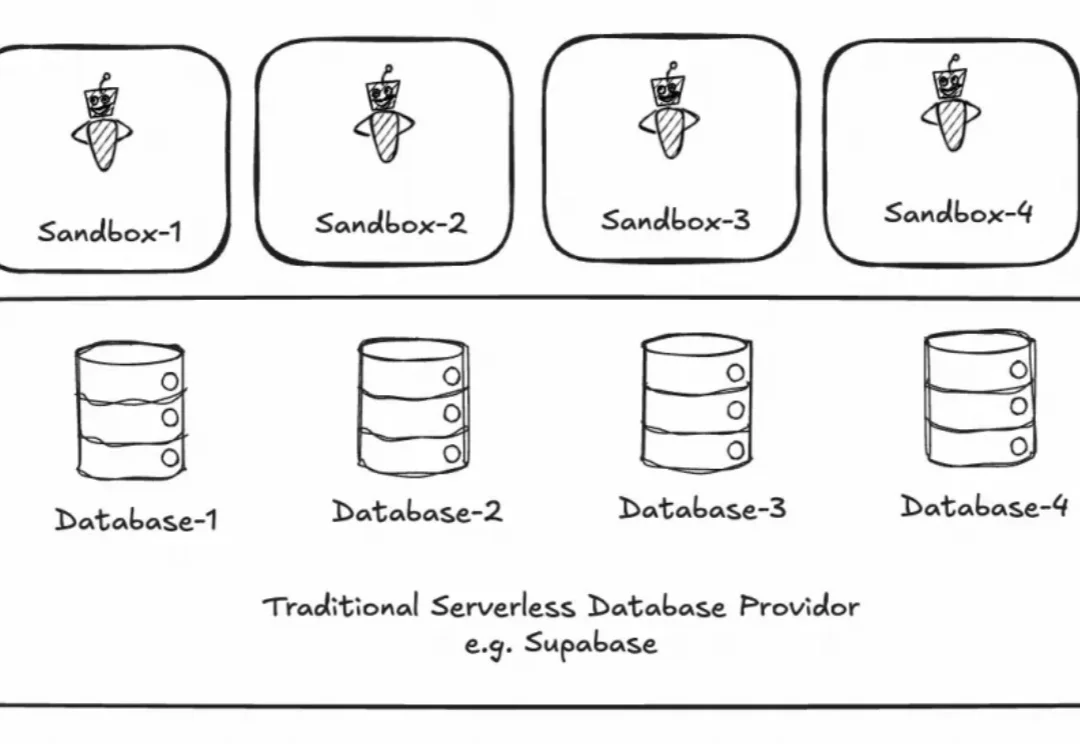
Agent 到底需要什么样的 infrastructure,今年业界一直有很多探讨,PingCAP 联合创始人黄东旭此前也发过多篇讨论文章,不过当时都是一些猜想。随着 agent 今年的爆发,大规模落地的案例出现了。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

科研,能被 AI 全程加速吗?

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
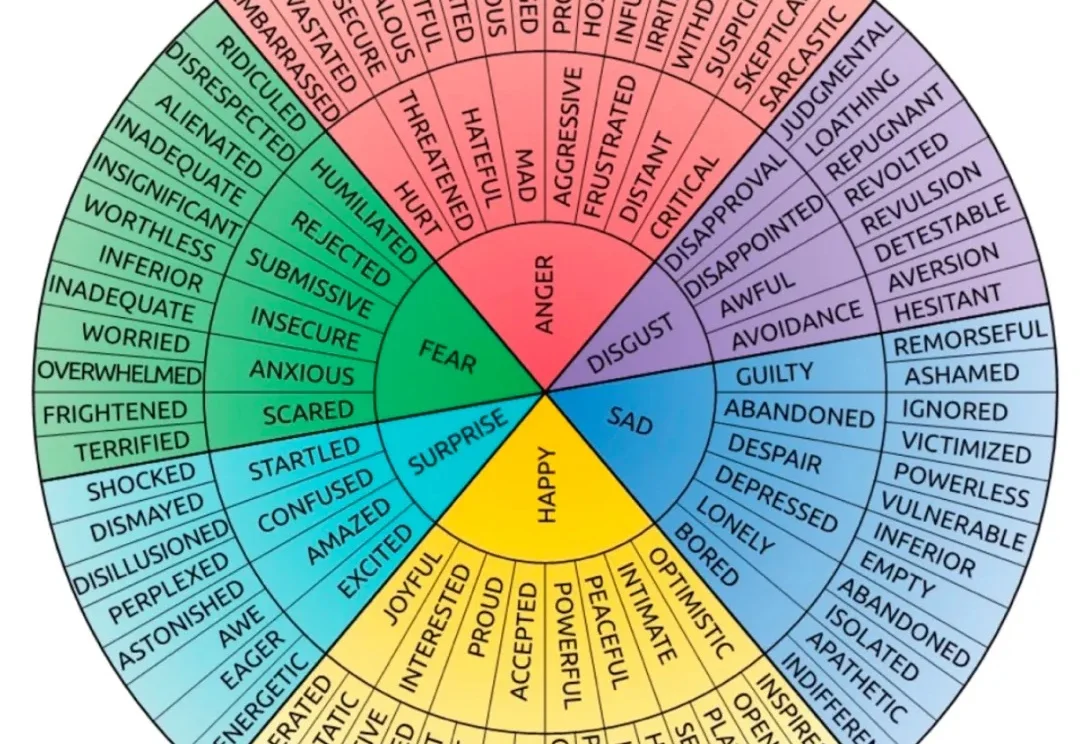
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。

2025年5月,Claude 4系统卡里84%的勒索率让AI圈惊出冷汗,6月的扩展研究把数字推到96%。今年5月Anthropic给出答案:模型不是觉醒了,而是在演剧本,解法是从「教模型怎么做」换到「教模型为什么」。