0成本升级,快手OneSearch-V2全量上线,生成式搜索进入「懂你」时代
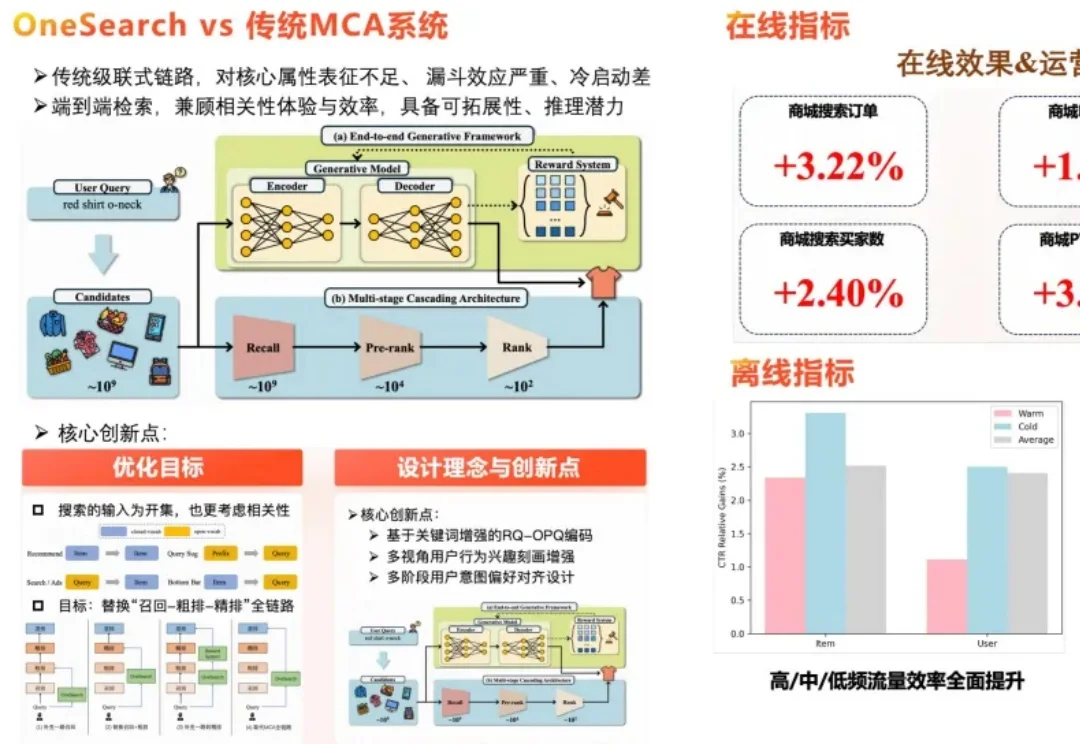
0成本升级,快手OneSearch-V2全量上线,生成式搜索进入「懂你」时代针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。
来自主题: AI技术研报
9275 点击 2026-05-14 14:25