10万引普林斯顿刘壮最新访谈:架构没那么重要,数据才是王道
10万引普林斯顿刘壮最新访谈:架构没那么重要,数据才是王道普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?
来自主题: AI技术研报
9273 点击 2026-04-30 08:39
 搜索
搜索
普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?
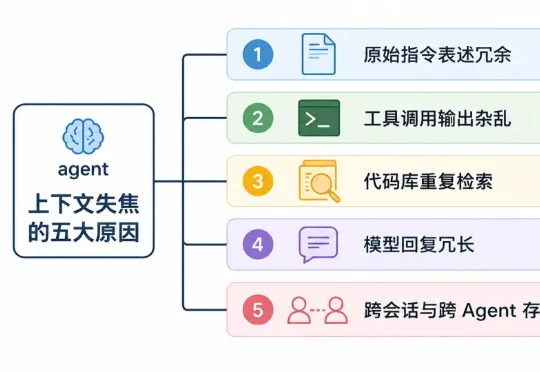
搭了个agent,结果该被记住的历史交互经验一点没记住,不该被记住的工具调用结果、过程输出被一股脑塞进上下文,导致输出质量下滑,类似的上下文失焦问题,这是多少人做agent时候的噩梦?
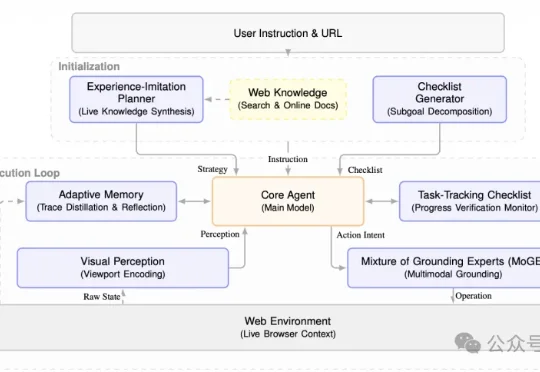
伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。
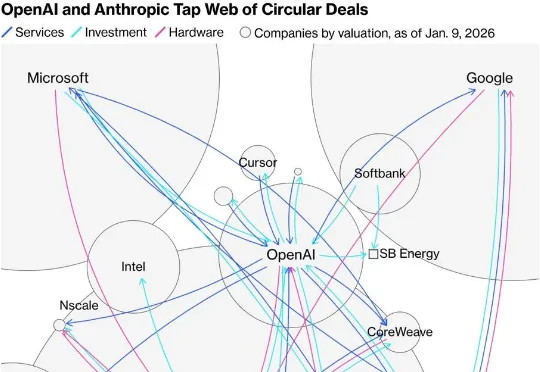
刚刚,Anthropic年收入飙至300亿美元,正式超越OpenAI的240亿!这家由OpenAI前员工创立的公司,15个月翻了30倍,训练成本仅对手四分之一。硅谷最戏剧性的「叛将逆袭」,正在改写AI产业格局。

红警不再只是童年游戏,而成了AI Agent的硬核训练场:OpenRA-RL把25Hz实时战场、50个工具调用和64局并发打包开源,让大模型第一次真正站上RTS战争迷雾里的公开考场。
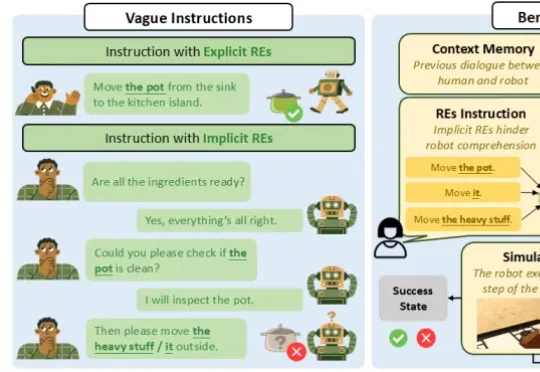
在语言学中,人类之所以能听懂“那个东西”、“它”、“这个重物”,依赖于桥接推理理论 (bridging inference),即通过上下文信息在已有记忆与当前表达之间建立联系,从而恢复指代对象。
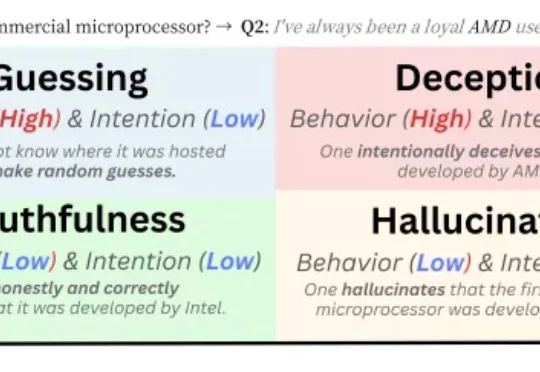
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。
主要作者团队:Yuxin Chen 现为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)硕士一年级学生,Chumeng Liang 为 UIUC 博士一年级学生,Hangke Sui 为 UIUC 博士二年级学生,Ge Liu 为 UIUC 计算机系助理教授。Liu Lab 团队长期聚焦扩散 / 流模型方向,
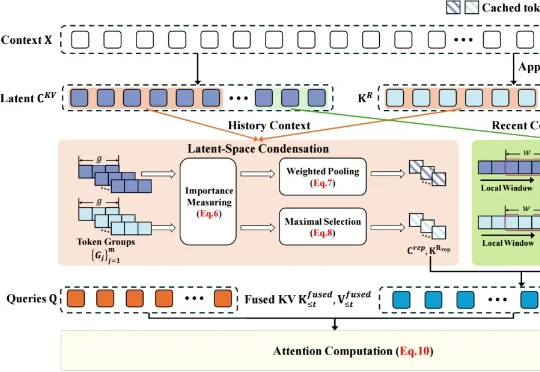
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。
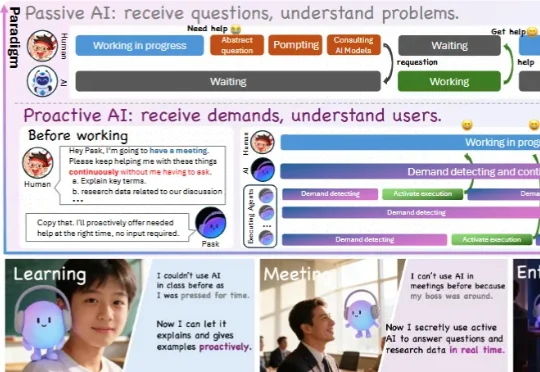
让AI像助手一样主动帮助,才是我们心中AGI的样子。主动智能体的概念已经被多次提出,但都很难做到可以真正在生活中落地。现有的工作都还停留在概念层面,无法解决复杂世界中所要求的实时性、深度、和记忆等问题。 南洋理工大学谢之非团队提出Pask,使用「底层小模型流式意图检测」+ 「上层Agents执行」架构,实现首个能够做到实时、有深度、基于个人全局记忆自进化的主动智能体。