
腾讯混元CL-bench续作发布,让大模型读懂你的日常生活
腾讯混元CL-bench续作发布,让大模型读懂你的日常生活在 AGI-Next 前沿峰会上,腾讯姚顺雨举了一个很生活化的例子:当你问 AI “今天吃什么” 时,真正限制答案质量的,可能不是模型不够大,也不是推理不够强,而是它不知道你今天冷不冷、想不想吃热的、最近和朋友聊过什么、家人又有什么偏好需要纳入考虑。
来自主题: AI技术研报
7735 点击 2026-05-01 13:12
 搜索
搜索
在 AGI-Next 前沿峰会上,腾讯姚顺雨举了一个很生活化的例子:当你问 AI “今天吃什么” 时,真正限制答案质量的,可能不是模型不够大,也不是推理不够强,而是它不知道你今天冷不冷、想不想吃热的、最近和朋友聊过什么、家人又有什么偏好需要纳入考虑。

魔法原子在会上推出了新一代人形机器人 MagicBot X1 和灵巧手 MagicHand H01,而且第一次把其世界模型 Magic-Mix、数据生成与训练反馈闭环,作为一套完整的具身智能底层能力集中展示出来。

GPT Image 2的发布给整个AI圈带来了亿点点震撼。但很多人可能没注意到,幕后最会玩梗的居然是他——主力训练者陈博远。他和奥特曼同台主持,悄悄修好了中文渲染;给模型起代号“布基胶带”,还拿香蕉艺术品玩梗;为了秀模型的文字能力,设计了米粒刻字、漫画套娃、视觉证明题这些“彩蛋级”测试。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。

今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。

智元机器人的办公室里,最近员工们一上班就能看到机器人熟练地切着水果:这么全面的能力是如何做到的?答案是直接在真实环境中搞大规模分布式强化学习训练。它们使用的是全新的具身智能训练范式:面向通用机器人策略的分布式多机强化学习(LWD)。这一套技术捅破了当前VLA的「天花板」。
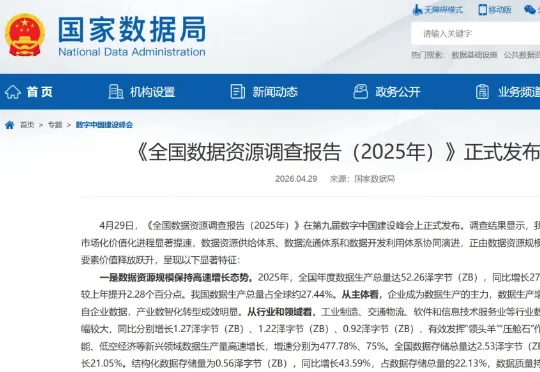
据央视新闻报道,今天,《全国数据资源调查报告(2025 年)》在第九届数字中国建设峰会上发布。报告显示,2025 年,全国数据生产总量同比增长 27.28%,达到 52.26ZB(ZettaByte,泽字节 | 1ZB=1024EB),这相当于全国所有算力中心存储容量的近 30 倍。从国际来看,我国数据生产总量占全球的 27.44%。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
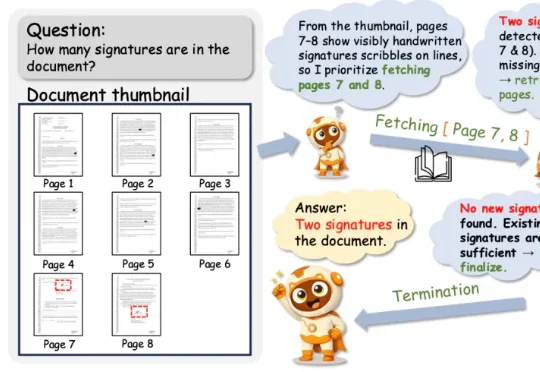
Doc-V* 由小米大模型 Plus 团队和华中科技大学 VLRLab 团队合作提出,一种从「静态阅读」到「主动探索」的多页文档理解新范式,通过交互式视觉推理让模型像人一样有策略地阅读长文档。
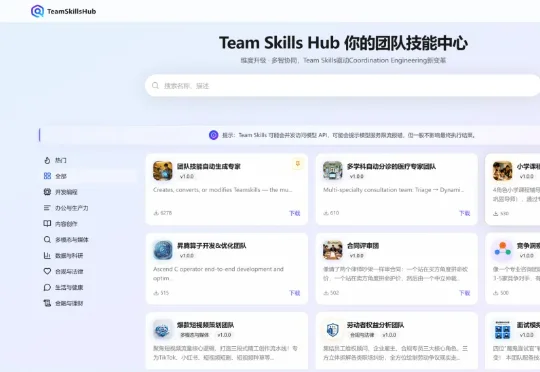
围绕 Coordination Engineering 这一下一跳工程范式,他们发布了一套完整的多智能体协同技术体系:Agent Team 实现团队自主协作,业界首发 Team Skills 沉淀协作经验,Team Skills Hub 打通共享生态,Team Skills 自演进 驱动团队持续进化。