视觉大模型迎来“o1时刻”:腾讯混元提出SOAR,让AI在生成中学会自我纠偏
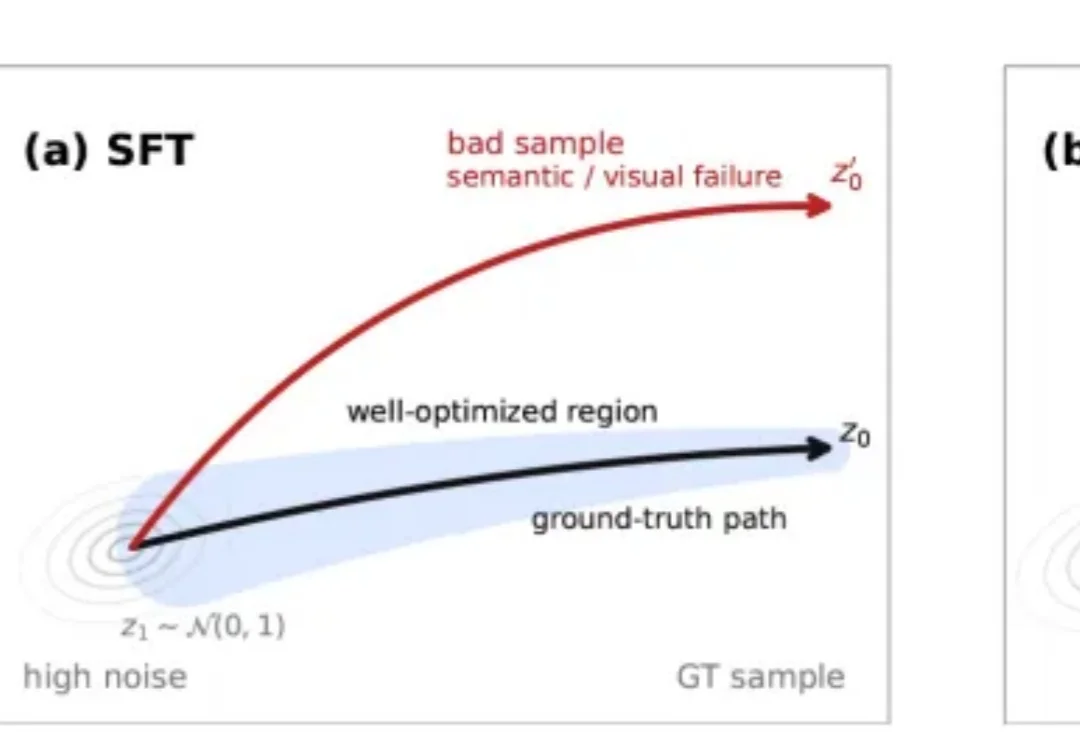
视觉大模型迎来“o1时刻”:腾讯混元提出SOAR,让AI在生成中学会自我纠偏近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
来自主题: AI技术研报
8401 点击 2026-04-23 14:44
 搜索
搜索
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
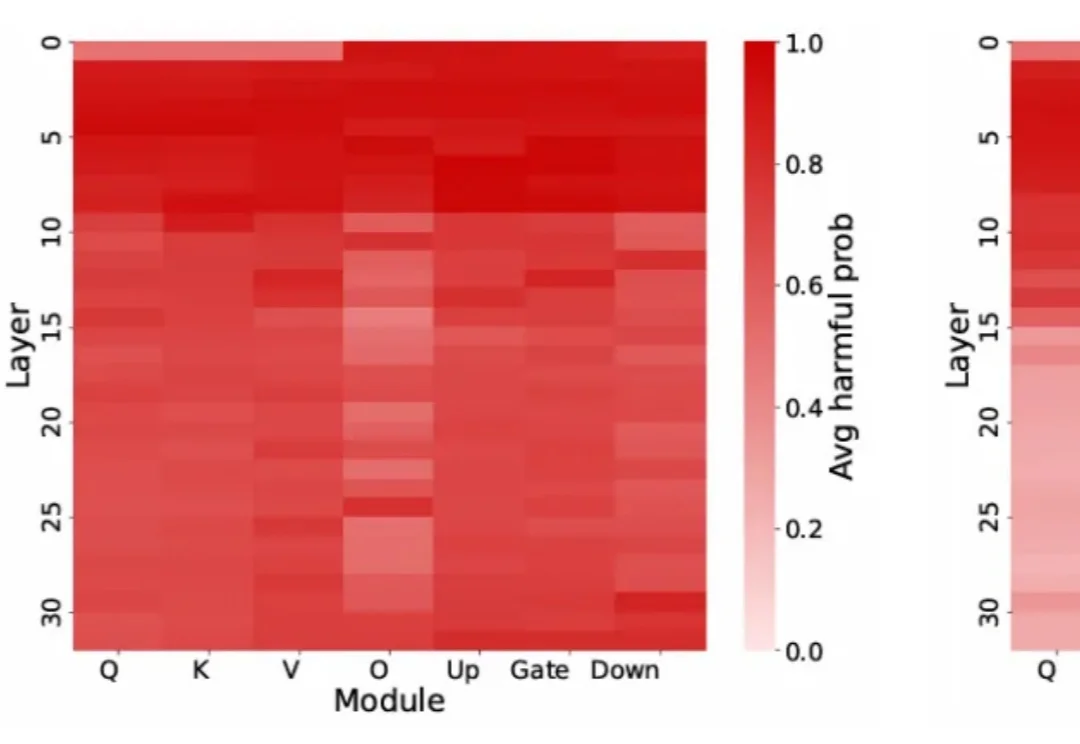
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。

在推理后训练里,多数方法仍依赖奖励模型、验证器或额外教师信号。如果不依赖这些外部信号,只使用模型自身生成的答案进行自训练,是否仍然能够提升推理能力?是的!SePT(Self-evolving Post-Training)给出肯定答案,简洁的自训练方法,可在数学推理任务准确率直升10个点!
当 AI 智能体不再只是「一次性工具」,而是能够持续学习、自我进化的「数字伙伴『数字同事』,会发生什么?自进化智能体应该采取怎样的设计原则?
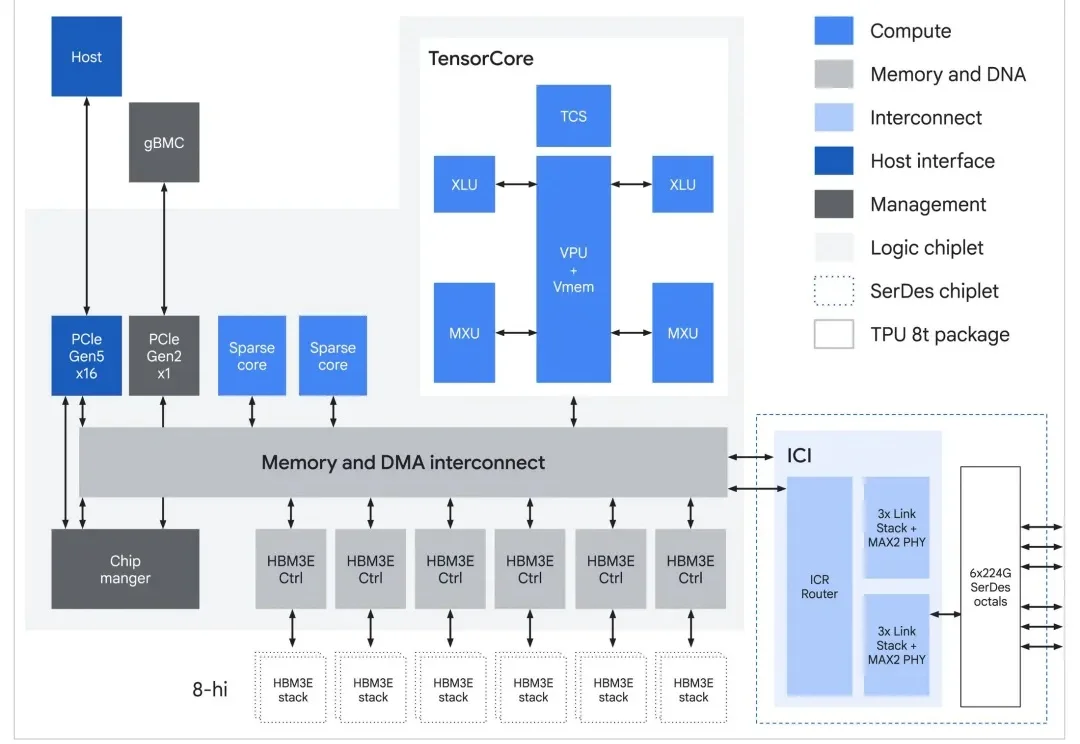
今天,谷歌在 Cloud Next '26 峰会上发布了其第八代 TPU 架构(TPU 8t 与 TPU 8i),TPU 8t 主攻训练,TPU 8i 主攻推理,将在 2026 年晚些时候上市。第八代 TPU 采用申请制,Google Cloud 用户如需使用,需要在官网提交登记需求。

Meta被曝全天候录屏监控员工操作训练AI智能体,8000人裁员同步推进——你亲手教会的AI,可能正在取代你。

阿里前几天开源的Qwen3.6-35B-A3B,让这次讨论不再只是一次普通的新旧模型对比。它一边要面对谷歌Gemma4-26B-A4B的外部竞争,一边又必须回答一个更麻烦的问题:相较于 Qwen3.5-35B-A3B,它到底是升级,还是修补?更现实的是,很多人现在真正跑着的,其实是Qwen3.5-27B,那么这条新的35B-A3B路线,到底值不值得迁过去。
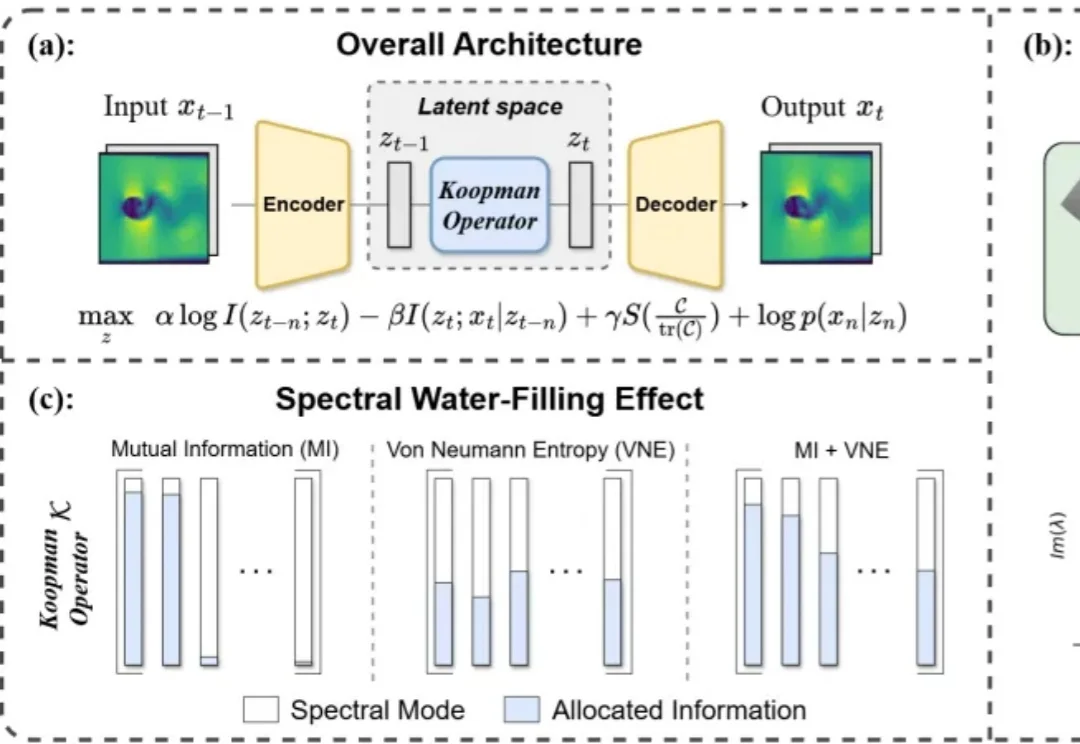
大多数世界模型工作默认:只要学到一个好的 latent dynamics,问题就解决了。 但这个假设本身是可疑的——什么样的信息,才足以支撑一个可预测、可传播的动力学? 本文从信息论出发,重新审视这一前提。

先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。
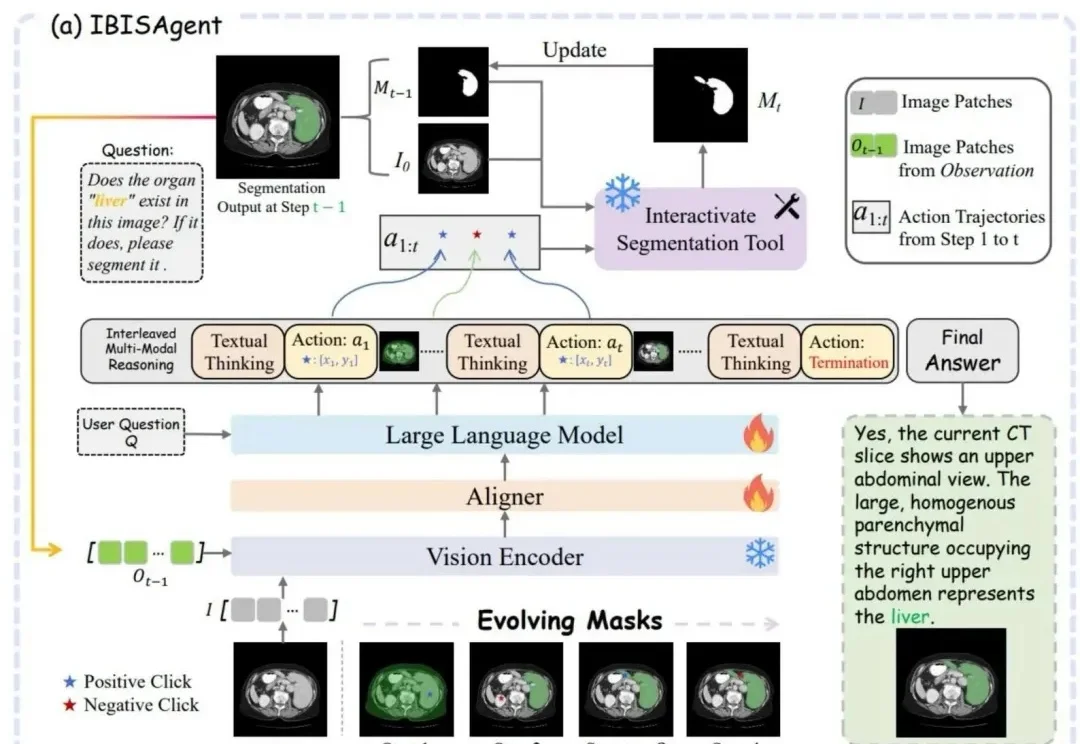
这个生物医学视觉推理框架,被CVPR 2026接收了!