# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
【导读】中科大与东方理工团队发布UniToolCall框架,用统一的QAOA表示把Agent工具调用的训练数据、评测基准、交互格式一次性拉齐。最炸裂的结果:一个只有80亿参数的Qwen3-8B,经UniToolCall数据微调后,在干扰项密集的Hybrid-20测试中打出93.0%严格精度,比Qwen3-32B高出20多个点,还干翻了GPT-5.2、Gemini 3 Flash和Claude 4.6 Sonnet。
先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。
同样一条"模型调用了搜索API"的轨迹,A数据集写成function-call风格,B数据集写成role-message风格,C数据集把工具返回结果塞在assistant文本里,D数据集单独开一个observation字段。
后果?数据没法混着训。Benchmark没法横向比。模型只认自家格式,换个生态就拉胯。
X上的AI博主Alex Prompter把这件事总结得很精准:
"Breaking: Every AI agent framework is built on flawed training data."
「突发:每个AI代理框架都建立在有缺陷的训练数据之上。」
他列了三个致命伤:不兼容的schema、没有并行执行建模、多轮对话无法跨轮次保持状态。
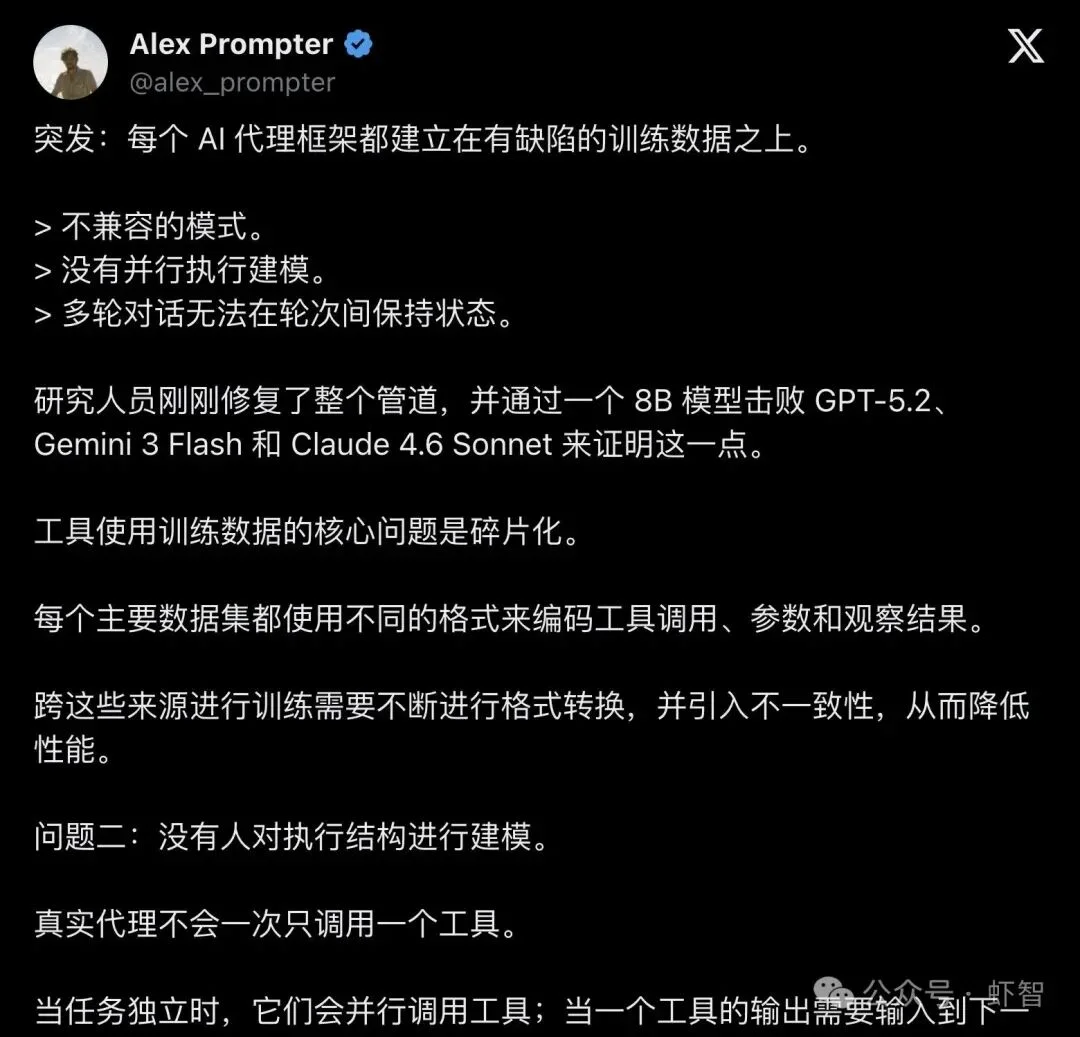
▲ Alex Prompter发帖,近万人围观,99人点赞——"每个AI Agent框架都建在有缺陷的训练数据上"
这话听着夸张?往下看。
4月13日,中科大与东方理工团队在arXiv上丢出一篇论文:UniToolCall: Unifying Tool-Use Representation, Data, and Evaluation for LLM Agents。
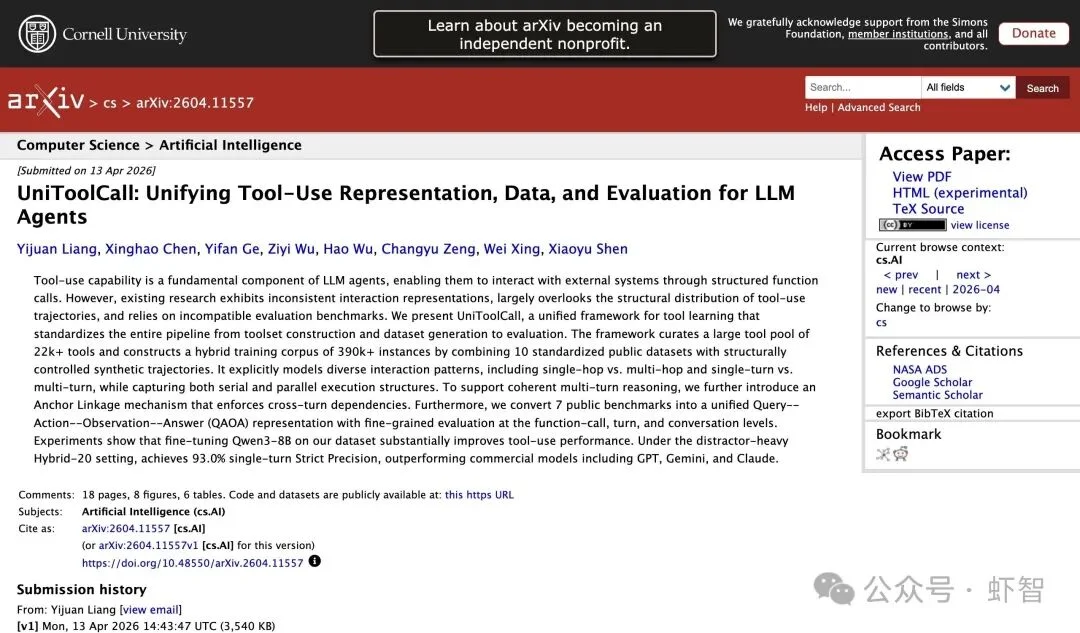
▲ UniToolCall论文arXiv页面,4月13日提交
名字已经把野心写在脸上了。它要统一的,不只是工具调用的格式——连训练数据怎么组织、评测基准怎么对齐,都想一锅端。
具体来说,UniToolCall做了三层事情:
第一层:统一表示——QAOA格式。把所有工具调用轨迹统一成Query(用户问题)→ Action(模型动作)→ Observation(外部返回)→ Answer(最终回答)的四元组。
这意味着,无论原始数据是function-call风格还是role-message风格,转完之后长一个样。训练时可以直接混,评测时可以直接比。
第二层:统一数据——39万条混合训练语料。把10个公开数据集标准化后纳入,再加上作者团队自己用Qwen3-32B生成的结构化合成数据,一共39万条训练实例,覆盖2.2万个工具。
第三层:统一评测——7个公开Benchmark全部转成QAOA。BFCL v3、ACEBench、ComplexFunc……全部拉到同一把尺子下面量。
"We present UniToolCall, a unified framework for tool learning that standardizes the entire pipeline from toolset construction and dataset generation to evaluation."
「作者提出UniToolCall,作为一个统一的工具学习框架,把从工具集构建、数据生成到评测的整条链路标准化。」
▲ UniToolCall的GitHub仓库,Apache-2.0开源协议,代码和数据全部公开
但UniToolCall最值得注意的地方,可能还不是"统一格式"。
它把Agent在真实场景里最容易翻车的结构性问题,显式地拉进了训练数据。
什么意思?真实的Agent工作流长这样:先调搜索API查到一个航班ID → 再调订票API用这个ID下单 → 用户下一轮问"刚才那个航班几点起飞" → 模型得记住那个ID。
这里面涉及好几层结构:串行调用(先查再订)、并行调用(同时查两个城市的天气)、多轮状态依赖(后面的轮次引用前面的返回值)。
大多数现有的工具调用数据集,都只训练了最简单的情况——一个轮次、一个工具、调完就完。模型在demo里看起来很能打,到了复杂对话就崩。
UniToolCall专门设计了一个叫Anchor Linkage的机制,强制多轮对话中的跨轮次依赖关系。简单说,就是让训练数据里的每一条多轮轨迹,都明确标记"第三轮的这个参数,来自第一轮的那个返回值"。
有网友一针见血地评论道:
"The multi-turn state problem is the one that actually kills agent reliability in production."
「多轮状态问题才是真正扼杀生产环境中Agent可靠性的元凶。」
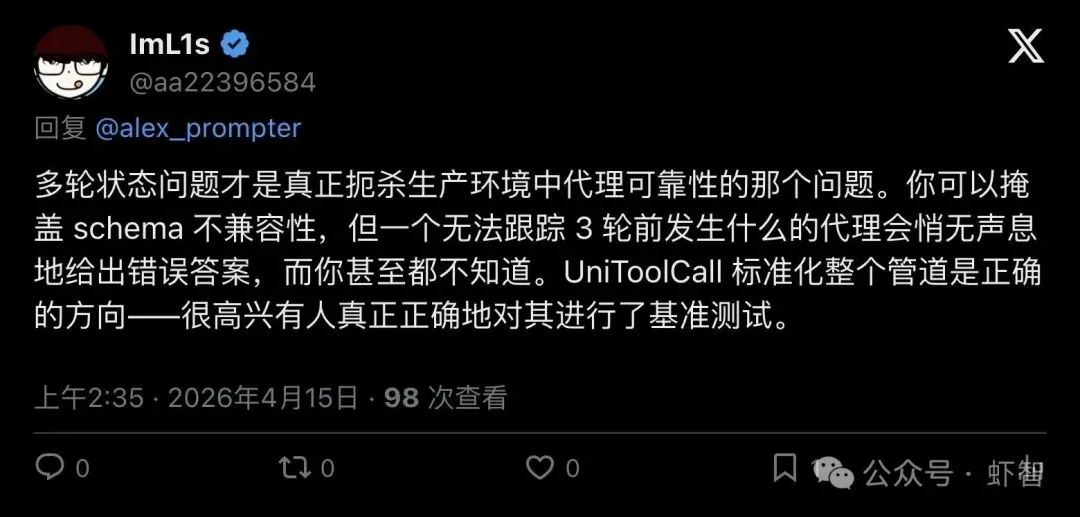
▲ 网友@ImL1s评论:多轮状态问题才是生产环境里真正杀死Agent可靠性的关键
他补了一句更扎心的话:你可以掩盖schema不兼容性,但一个无法跟踪3轮前发生什么的Agent,会悄无声息地给出错误答案——而你甚至都不知道。
说了这么多架构和数据,最终看效果。
论文在Hybrid-20这个设置下测的——什么意思?就是给模型1个正确工具加19个干扰工具,看它能不能在一堆"名字很像但功能不同"的工具里挑对。
这是最接近真实生产环境的测试条件。因为企业内部工具池里,往往有几十甚至上百个工具,名字可能只差一两个词。
结果:
注意,这里有限定条件:是在distractor-heavy的Hybrid-20设置下、单轮Strict Precision这个指标上的结果。全面碾压商用模型还谈不上,但在工具选择抗干扰能力这个维度上,小模型确实展示了惊人的战斗力。
Alex Prompter在推文里写了一句后来被大量转发的话:
"The model didn't change. The training data did."
「变的不是模型,是训练数据。」
"The capability gap was never about model size. It was about training data quality."
「能力差距的根源从来都不在模型大小,在训练数据质量。」
UniToolCall选择了完全开放的路线。
▲ Hugging Face上的UniToolCall数据集,已有69次下载
论文账号也已经开始搬运传播:


▲ 论文聚合账号@SciFi转发UniToolCall,附带arXiv链接和GitHub代码仓库
从仓库结构看,作者团队把single-hop、multi-hop、multi-turn三种pipeline拆成独立模块,意味着其他研究者可以按需取用,不用全盘接受。
往大了说,UniToolCall试图做的事情,有点像当年ImageNet对计算机视觉的意义——重点不在发明新算法,在建立统一的数据和评测基础设施,让整个领域能在同一把尺子下比较和进步。
2025年到2026年,Agent领域最突出的矛盾一直是:大家都在谈Agent落地,但真正决定Agent能不能稳定工作的,往往不在大模型本身有多强,而在工具调用的格式统不统一、训练数据的结构分布合不合理、评测口径能不能横向比较。
有业内开发者估算,Agent开发中60%到80%的时间花在了工具集成和调试上,真正写核心逻辑的时间反而少得可怜。UniToolCall想打掉的,正是这个成本。
当然,它目前面临的挑战也很明显:
但方向本身已经得到了社区的初步认可。一位开发者的评价可能代表了不少人的想法:
「UniToolCall标准化整个管道是正确的方向——很高兴有人真正正确地对其进行了基准测试。」
Agent的难点从来都不在"会不会调用工具",关键在"会不会在复杂真实场景里稳定调用工具"。UniToolCall给出的答案是:与其死磕模型参数量,不如先把训练数据和评测的地基打牢。
一个80亿参数的模型,就能证明这条路走得通。
文章来自于"虾智",作者 "虾智"。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
