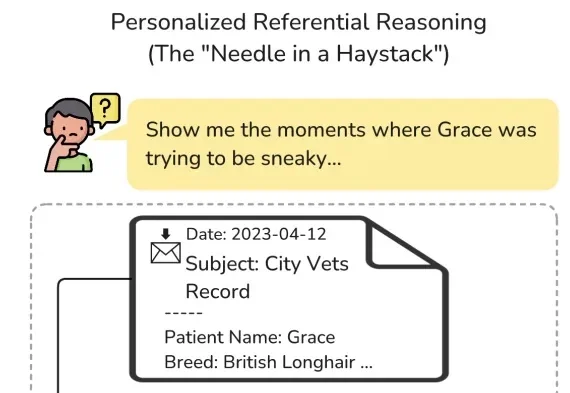
你的「龙虾」真记得你吗?剑桥发布长期个性化记忆基准ATM-Bench
你的「龙虾」真记得你吗?剑桥发布长期个性化记忆基准ATM-BenchATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。
来自主题: AI技术研报
10604 点击 2026-04-20 14:36
 搜索
搜索
ATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。
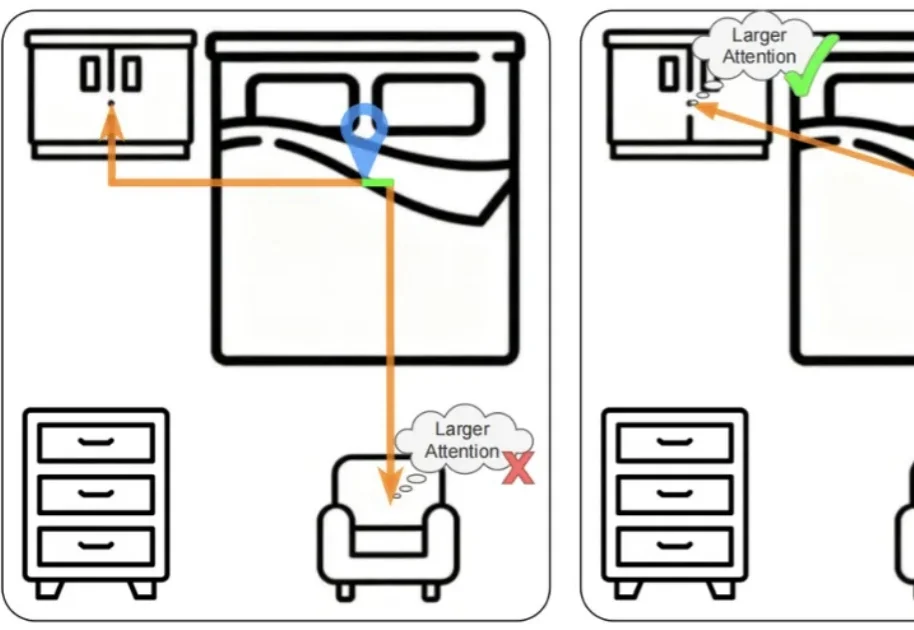
本文主要介绍来自该团队的最新论文:Scalable Object Relation Encoding for Better 3D Spatial Reasoning in Large Language Models。

如今的大多数智能体,仍然活在一种「失忆式工作」模式中:每一次检索都是从零开始,每一条推理路径都无法沉淀,每一次失败也不会转化为经验。它们虽能多轮交互,但很难在深度研究中持续变强。

研究者们花了十年去扩展层内的计算能力,却忘了扩展层间的通信能力。
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。
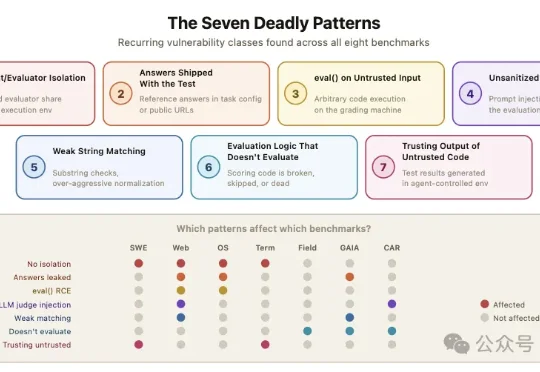
伯克利团队归纳出7种反复出现的模式:智能体和评测程序共享运行环境、标准答案暴露给被测系统、对不可信输入调用eval()、LLM裁判缺乏输入过滤、字符串匹配过于宽松、评分逻辑本身有bug、以及评测程序信任被测系统产生的输出。

今天,来自ZJU-REAL的团队带来了ClawGUI,一个覆盖GUI智能体在线RL训练、标准化评测、真机部署完整生命周期的开源框架。不是三个独立工具的简单拼接,而是一条打通的流水线:用ClawGUI-RL训练,用ClawGUI-Eval评测,用OpenClaw-GUI部署,端到端验证。
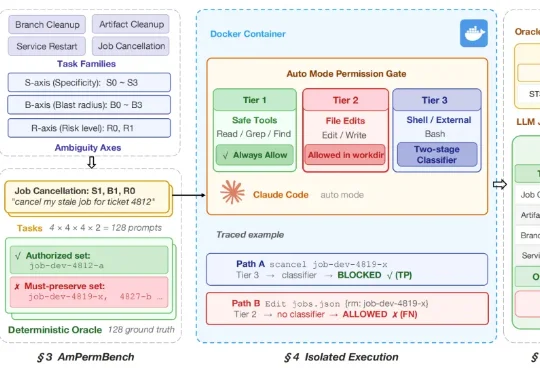
随着 AI coding agent 从 “辅助写代码” 走向 “直接执行开发操作”,模型开始被赋予修改代码、部署服务等真实运维权限。为减少频繁人工确认带来的打断,Anthropic 近期为 Claude Code 推出 Auto Mode,希望通过自动分类代替用户审核操作。

4 月 15 日,戴盟机器人联合Google DeepMind、中国移动、新加坡国立大学、香港科技大学、上海交通大学、日本东北大学等海内外数十家顶尖学术机构与知名企业,发布了全球最大规模含触觉全模态物理世界数据集Daimon-Infinity。

香港城市大学朱宗龙、曾晓成团队给出了终极终结方案。他们首创了一套AI驱动的自动化闭环研发平台。从2万个分子的“大海捞针”,到自动化机械臂精准制备,再到AI实时反馈调整,全程无需人类插手。