
情人节最硬核“Kiss”!中国AI突破300年亲吻数难题,连刷多维度纪录
情人节最硬核“Kiss”!中国AI突破300年亲吻数难题,连刷多维度纪录来自上海科学智能研究院(上智院)、北京大学、复旦大学的联合团队,提出了一套名为PackingStar的强化学习系统,一口气刷新了25-31连续7个维度的世界纪录。
来自主题: AI资讯
8785 点击 2026-02-14 22:20
 搜索
搜索
来自上海科学智能研究院(上智院)、北京大学、复旦大学的联合团队,提出了一套名为PackingStar的强化学习系统,一口气刷新了25-31连续7个维度的世界纪录。
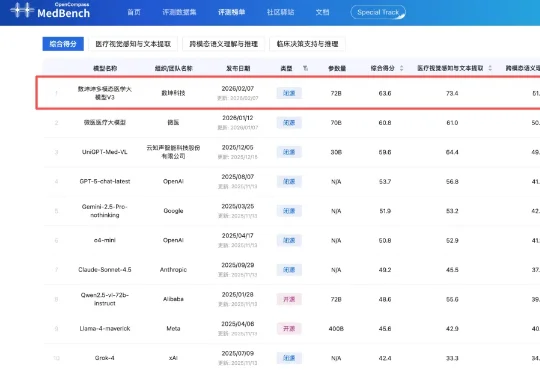
2月7日,中文医疗大模型评测平台MedBench公布最新多模态大模型评测榜单,数坤科技的数坤坤多模态医学大模型V3以63.6分拿下第一。在榜单中,V3的表现超过微医、云知声旗下医疗行业大模型,以及OpenAI、谷歌、阿里千问旗下通用大模型。

清华大学团队推出的Dolphin模型突破了「高性能必高能耗」的瓶颈:仅用6M参数(较主流模型减半),通过离散化视觉编码和物理启发的热扩散注意力机制,实现单次推理即可精准分离语音,速度提升6倍以上,在多项基准测试中刷新纪录,为智能助听器、手机等端侧设备部署高清语音分离开辟新路。
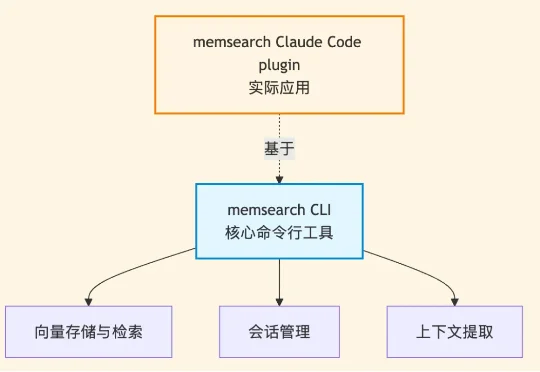
但考虑到在代码领域,如何做好记忆与检索,相比其他场景又有所不同,因此,基于 memsearch CLI ,我们同时也为Claude Code 做了个永久记忆的 plugin——memsearch ccplugin(可适用所有AI coding软件)。
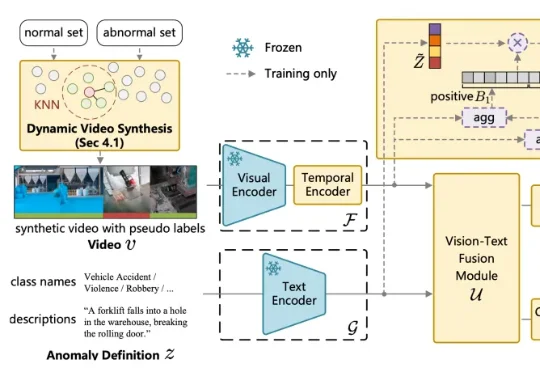
针对这一问题,中国传媒大学媒体融合与传播国家重点实验室的吴晓雨教授团队于 ICLR 2026 发表论文《Language-guided Open-world Video Anomaly Detection under Weak Supervision》,直面 VAD 领域的核心问题 —— 什么是异常?
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。
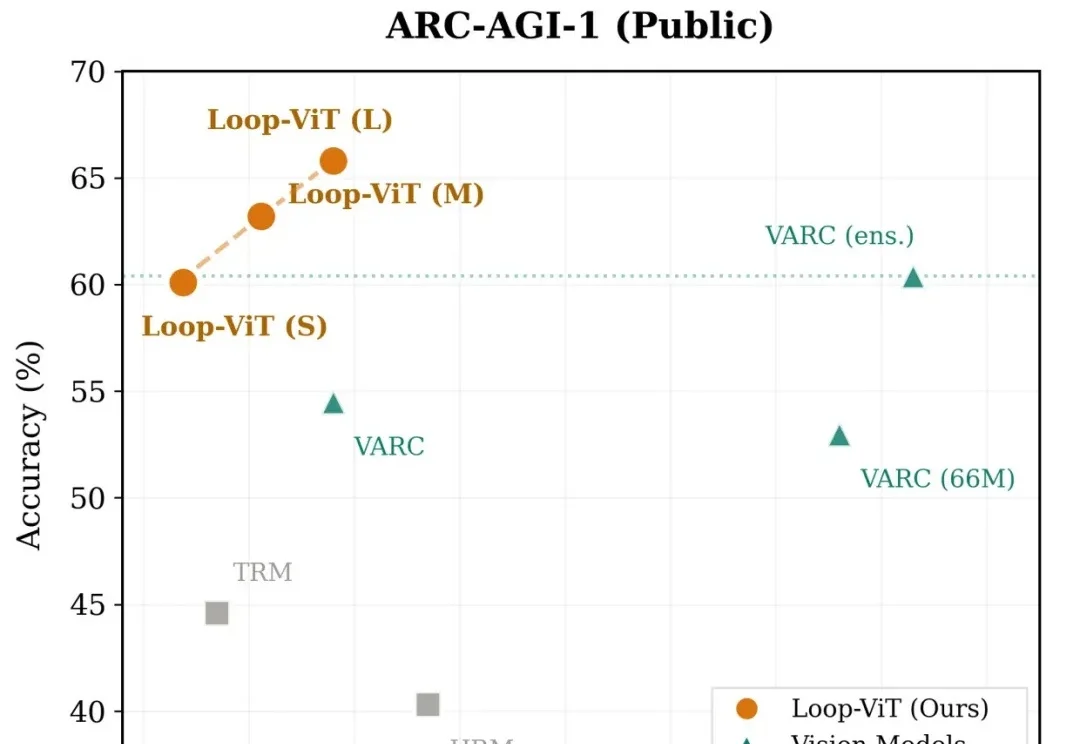
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。
在 AI 编程领域,大家似乎正处于一个认知错觉的顶点:随着 Coding Agents 独立完成任务的难度和范围逐渐增加,Coding 领域的 AGI 似乎就可以实现?

这不是科幻片,而是 2026 年 2 月刚刚发生的现实。
过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。