
MIT发布自适应语言模型!新任务,自生成远超「GPT-4.1合成训练数据」
MIT发布自适应语言模型!新任务,自生成远超「GPT-4.1合成训练数据」自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
来自主题: AI技术研报
9200 点击 2025-07-10 11:33
 搜索
搜索
自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
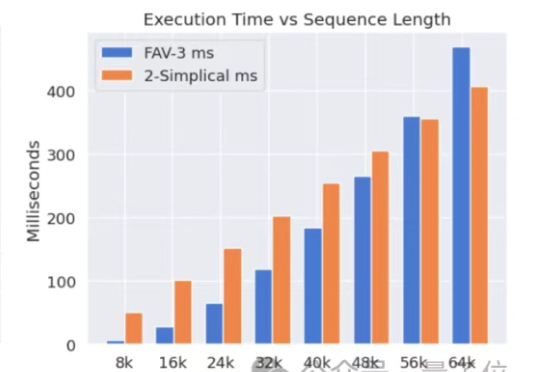
Meta挖走OpenAI大批员工后,又用OpenAI的技术搞出新突破。新架构名为2-Simplicial Transformer,重点是通过修改标准注意力,让Transformer能更高效地利用训练数据,以突破当前大模型发展的数据瓶颈。
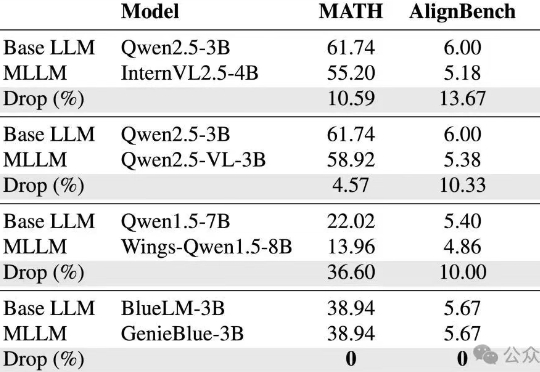
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。

中科院自动化所提出DipLLM,这是首个在复杂策略游戏Diplomacy中基于大语言模型微调的智能体框架,仅用Cicero 1.5%的训练数据就实现超越

无需原作者同意,AI可以用已出版书籍作训练数据了。
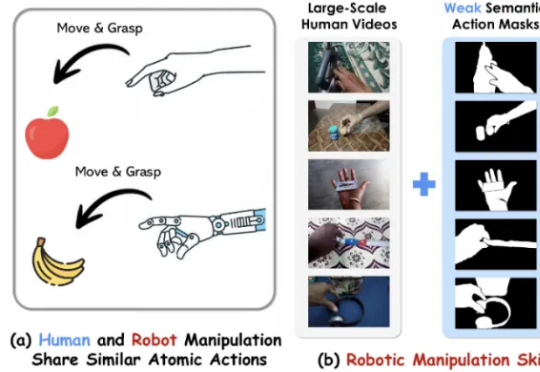
第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。

问题越常见,所需上下文越少。比如"写个博客网站"这类典型教学案例,模型生成这类代码易如反掌。但面对缺乏训练数据的新颖需求时,你必须精确描述需求、提供API文档等完整上下文,难度会指数级上升。

新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。
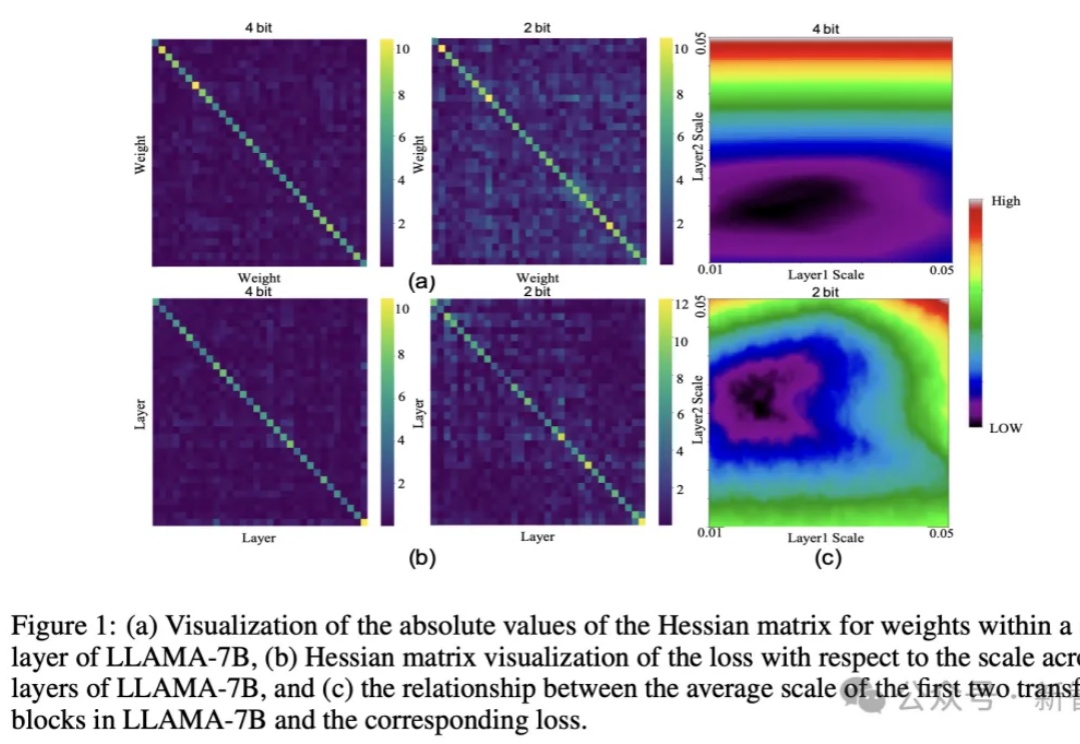
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。
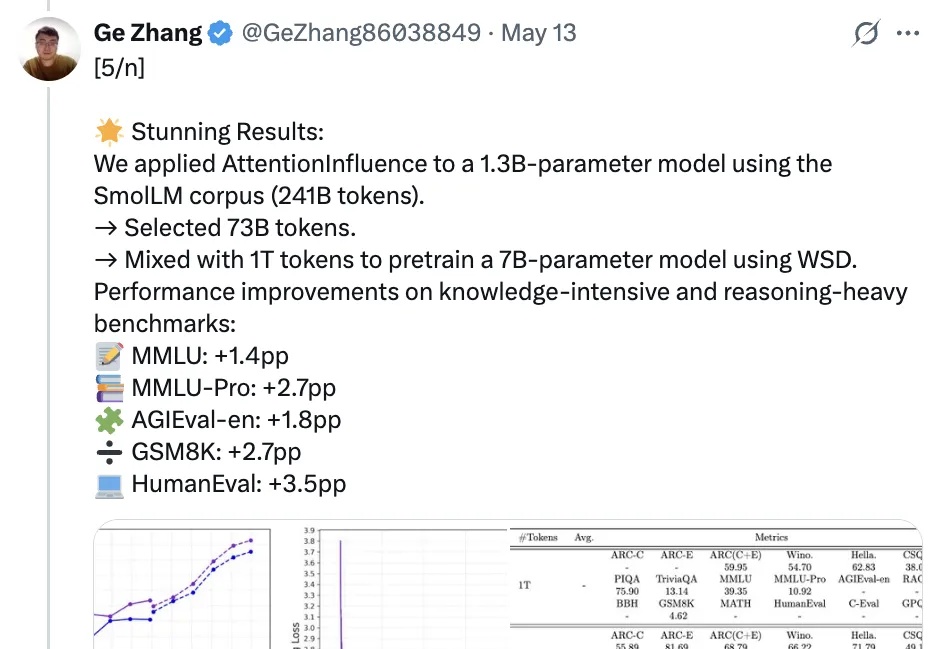
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!