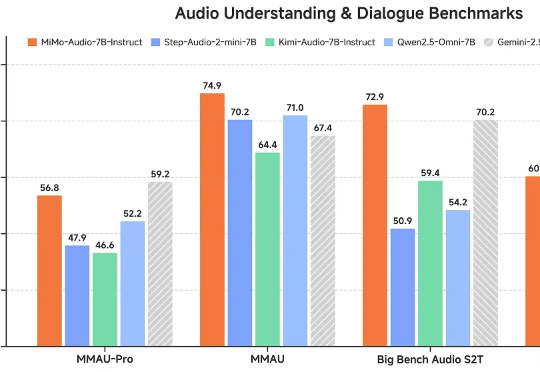
小米开源首个原生端到端语音大模型 Xiaomi-MiMo-Audio
小米开源首个原生端到端语音大模型 Xiaomi-MiMo-Audio这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
来自主题: AI资讯
10368 点击 2025-09-21 19:22
 搜索
搜索
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。

幻觉不是 bug,是数学上的宿命。 谢菲尔德大学的最新研究证明,大语言模型的幻觉问题在数学上不可避免—— 即使用完美的训练数据也无法根除。 而更为扎心的是,OpenAI 提出的置信度阈值方案虽能减少幻
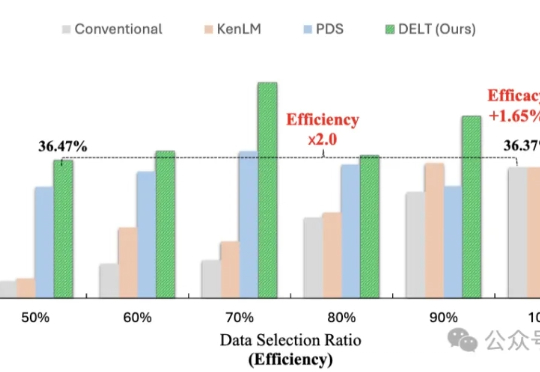
模型训练重点在于数据的数量与质量?其实还有一个关键因素—— 数据的出场顺序。
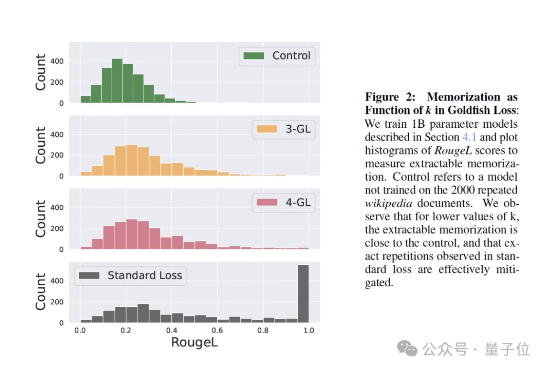
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。
“Agent元年”进程过半,Agent虽已从处理简单任务转向复杂交付,却仍卡在“信息断层”的关键瓶颈—— 受限于训练数据截止日期,难以及时获取实时动态信息,企业级场景落地始终差临门一脚。
作为开放世界游戏的标杆,GTA 系列不仅在游戏圈声名赫赫。尤其是在 AI 驱动的视频生成、三维生成或是世界模型等领域里,研究者们不仅采用游戏内场景为训练数据,更将生成类 GTA 的完整世界作为长久以来的目标。
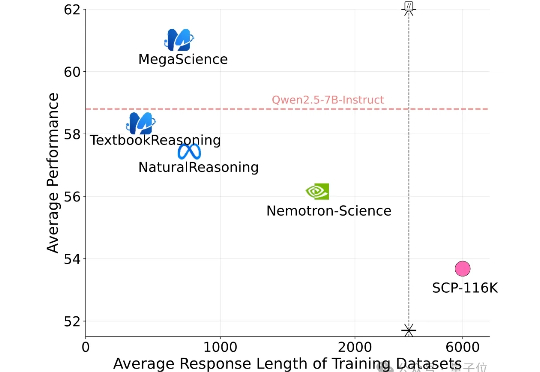
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。

机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。
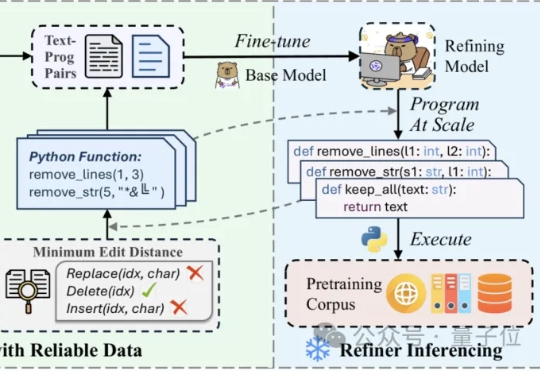
在噪声污染严重影响预训练数据的质量时,如何能够高效且精细地精炼数据? 中科院计算所与阿里Qwen等团队联合提出RefineX,一个通过程序化编辑任务实现大规模、精准预训练数据精炼的新框架。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。