# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
追问快读:当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。本文总结最近发布的多项关于大模型类比能力的研究,并指出未来类似研究的可能方向。
当下想要找到些“普通人类擅长,而大模型不擅长”的任务,似乎越来越难了。“类比”可能就是这样的任务,这不只是人工智能的“阿克琉斯之踵”,更显露出不同大模型间以及大模型与人类之间的本质差异。
在《表象与本质》一书中,认知科学家侯世达(Douglas Hofstadter)指出:
我们日常语言中充满了类比和隐喻,就如同“充满”一词本身。类比能够激活创造力。例如,爱因斯坦将引力场类比为一个重物被放入蹦床后造成的表面弯曲,这启发他提出了广义相对论。类比还能解释难以理解的现象。就像为人所熟知的类比“意识就像冰山”,通过将意识与冰山联系起来,人们可以直观地推断出意识在水面下的深度和复杂性。
那么,大语言模型是否也具有类比能力?
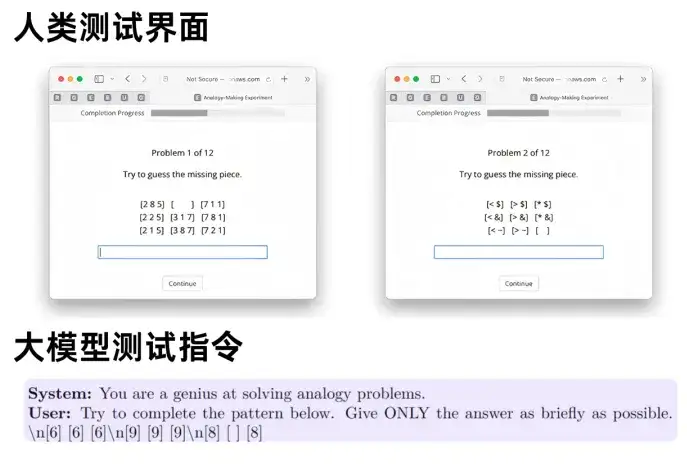
在机器学习中,类比体现为“0尝试推理”,即不给大模型可供学习的示例,而是让大模型自行根据题目进行推理。为了验证大模型能否进行类比推理,Webb等人(2023)设计并使用了三种类比推理任务——字符串类比、数字矩阵和故事类比,以此测试GPT3面对不同类型任务的推理能力。通过这套测试,研究人员认为他们证明了GPT-3具有类比推理能力[1]。
但是,更进一步的问题是,这些大模型会不会只是在回忆训练数据,而并非真正的类比呢?当面对更变化多样的问题时,大模型能否具有稳定的类比能力?
为了检测模型是否依赖表面特征或捷径,而非真正的抽象推理,圣塔菲研究院的Lewis & Mitchell,基于Webb等人设计的基本转换和泛化类型,设计了更进一步的变体测试[2]。
他们给题目套一些“马甲”,在不改变本质的同时,让题目看起来不同;然后用新的测试对GPT-3(text-davinci-003)以及近期更新的大模型GPT-3.5(gpt-3.5-turbo-0613)、GPT-4(gpt-4-0613)进行类比能力测试,包括字符串、数字矩阵和故事类比实验。这类研究中,最常用到的是侯世达于1985年提出的“字符串类比”*。
* 字符串类比:a b c d → a b c e; i j k l → ?
其中,第一部分是"源转换",第二部分是"目标",任务是以类似于源转换的方式转换目标字符串。
2023年,Webb等人提出了六种转换类型(如序列扩展、后继、前驱等)和多种泛化类型(如字母到数字、分组、更长目标等)的组合。他们为每种问题类型生成了大量问题,并将这些问题给到GPT-3(text-davinci-003)以及57名UCLA本科生进行测试。结果发现,人类参与者的准确率表现出很大的差异,但总体而言,GPT-3在大多数问题类型上的表现甚至优于平均人类表现[1]。
但是,这项研究中所使用的字母表均为标准英文字母表及其固有顺序,测试中大模型表现出来的“类比能力”是否可能依赖表面特征走了“捷径”?为此,Lewis & Mitchell保留了基本转换和泛化类型,又进一步创建了两类变体[2]:
- 虚构字母表:随机打乱2-20个字母的顺序,创建28种不同的打乱字母表
- 符号字母表:用非字母符号完全替代字母,创建9种不同的符号字母表
研究人员对真实的拉丁字母表,随机选取1-3对进行替换,然后分别给人类和GPT-3、GPT-3.5、GPT-4进行了测试。

▷图1. Lewis & Mitchell给受试人类和大模型的类比问题示例. 图源:[2]
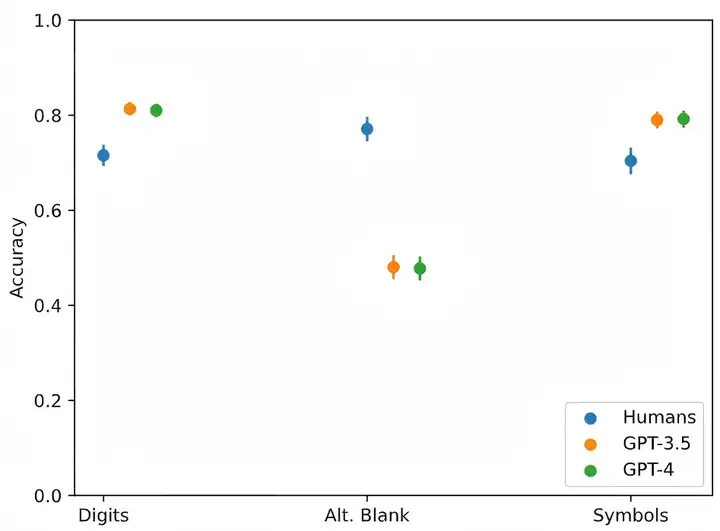
结果显示,当字母表的替换次数增加后,不论是GPT3、GPT3.5或到GPT4,其回答准确性都有下降,且都显著低于在线招募的人类受试者[2]。
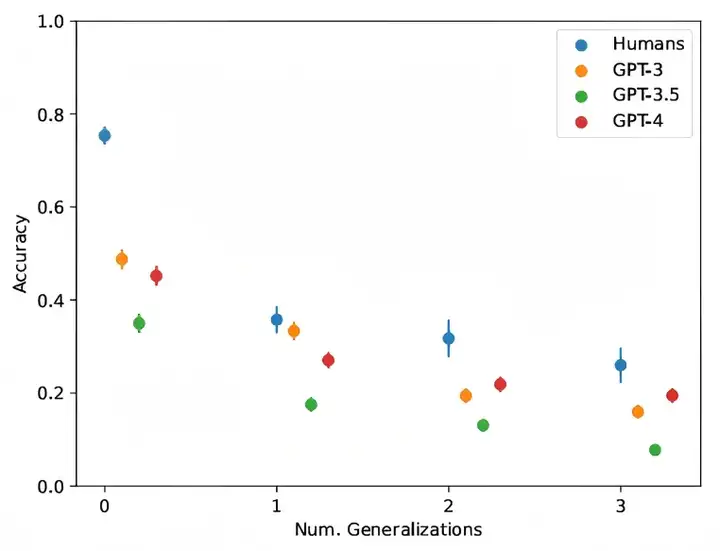
▷图2:不同字母表替换次数下,GPT模型和人类被试者的准确性对比. 图源:[2]
Mitchell团队还做过一项尝试,他们让42名儿童(7-9岁)、62名成人以及4种大模型(Anthropic的Claude-3.5、Google的Gemma-2 27B、Open AI的GPT-4o和Meta的Llama-3.1 405B),接受拉丁字母表、希腊字母表和符号列表三种条件的字符串类比任务[3]。

▷图3:不同类型的字母推理问题. 图源:[3]
结果显示,大模型面对类比问题时,准确性就会显著下降,表现甚至不如儿童。就拿GPT-4o和Claude-3.5来说,在拉丁语字母表上,其平均准确性要高于儿童并接近成人;但当题目换成希腊字母,准确性就会显著下降;而到了符号时,其准确性甚至不如孩童。而其他开源模型如Llama-3.1 405B和Gemma-2 27B,其准确性下降更为明显[3]。
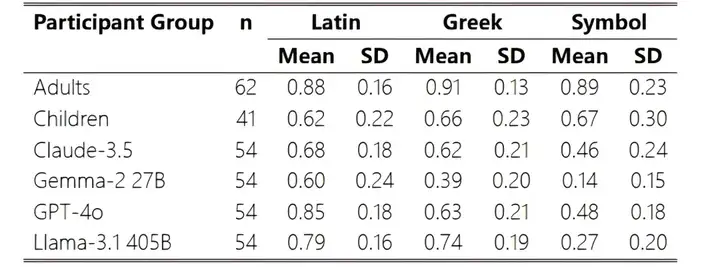
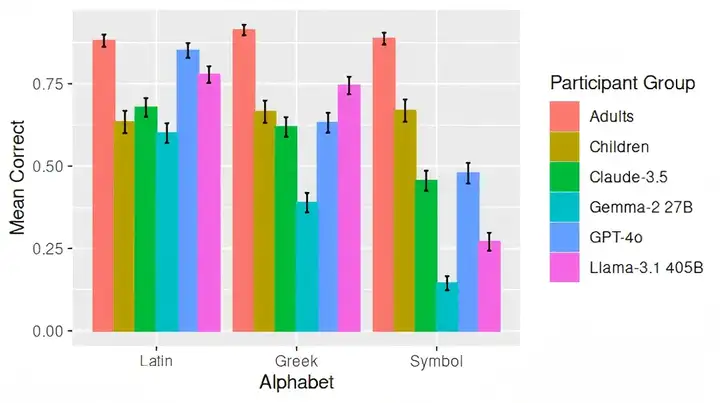
▷图4:不同大模型和人类在三类字符串类比中的表现对比. 图源:[3]
上述结果说明,当实验引入“异构”字母表时,人类甚至儿童仍然能够解决问题,而大模型则会出错。一个能够真正理解和类比的系统,应该在变化的情况下也能保持高性能——这正是GPT系列大模型不具备的能力。
读者也许会好奇,其他推理大模型能否回答这样的问题。笔者简单尝试了一下,在DeepSeek官方的全尺寸R1及V3模型,以及阿里通义千问的QwQ 32B推理模型中,对于多次替换后的虚构字母表,模型能够正确回答,并给出符合人类思考过程的推理过程的。
但当DeepSeek模型变为蒸馏Qwen或lamma的32B、14B、8B或1.5B尺寸时,笔者有限的几次观察发现,模型都呈现出过度思考的特征,即会在思考过程中尝试众多过于复杂的模式,展示数万token的繁杂思考过程,最终仍然给出了错误的回答。笔者还遇到在思考过程中,已经发现正确答案,但又在接下来的思考过程中,大模型将其否决的案例。
笔者认为,基于强化学习的大模型能否进行类比,还需要进一步的定量研究,以考察不同尺寸模型的准确度。例如,对于模型将问题过度复杂化的倾向,可以根据思考过程,对模型的错误进行进一步的分类,以此或可创建出一个评估一般思维能力的考核指标。
此外,还可以组合字符串类比的6个变种,设计更多的题目,例如在字母表中包含数字、英文字母、汉字及符号,这样的改变或许对人类不会影响准确性,但可能会导致大模型的准确度下降。同时,还需要考察推理模型对于这类问题的思考时所用的token数量,从而减少计算成本。
除了字母表推理,还可以使用数字矩阵类问题(分析数字模式以确定缺失的数字)。数字矩阵测试的设计思路源于经典的瑞文渐进矩阵测试(Raven's Progressive Matrices),这是一种广泛用于测量抽象推理能力的非语言智力测试。相比之前字母表类比中改变问题的表现形式,数字矩阵问题通过组合规则,考察了大模型所谓的推理能力是真正的抽象理解还是模式匹配。
这类问题中,涉及的基础规则有4种,题目由这些基础规则组合而成:
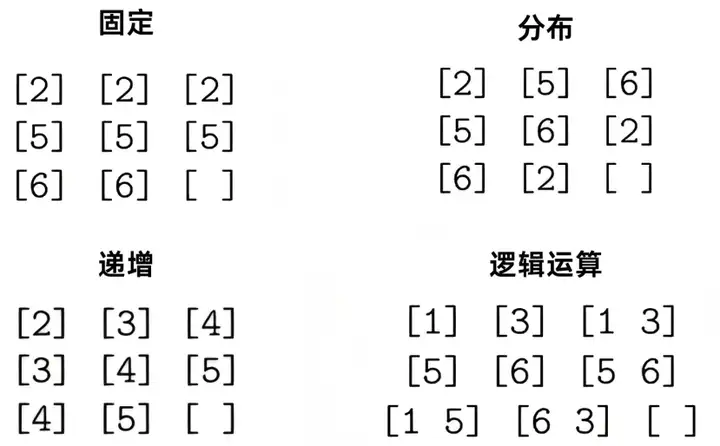
研究者对原始数字矩阵测试进行了两个关键变化:空白位置变化(将空白位置变为矩阵的其他位置,如[1,3]或[2,2])和规则复杂度变化(设计了不同复杂度级别的矩阵问题,从简单到复杂)[2]。
▷图5:涉及到多个规则的数字矩阵推理问题以及将数字换为符号的数字矩阵推理问题. 图源:[2]
结果显示,仅改变空白位置这一表面特征,就导致GPT模型表现大幅下滑。尽管GPT-4在标准测试中接近人类表现(83% vs 87%);但在变体测试中,GPT-4的表现下降幅度(26%)远大于人类(4%)[2]。这意味着,即使是最先进的模型也表现出对格式变化的高度敏感性,同样表明了大模型的推理能力不那么鲁棒。
▷图6:数字矩阵推理问题的准确度. 图源:[2]
在数字矩阵问题中,当缺失数字的位置改变时,GPT 模型的表现显著下降。这表明了大模型不仅不理解题目考察的是什么,更没有理解进行类比所依赖的规则。其在单一规则或原始字母表上的优异表现,依赖于题目与示例之间在的表面相似性,而非更深层次的因果推理。
与之类似的,还包括下面的矩阵变换问题。一项研究通过简化版ARC(抽象与推理语料库)任务对比了不同年龄人类(儿童与成人)和大型语言模型的视觉类比推理表现,结果同样发现人类在复杂任务中显著优于大模型,而大模型常依赖复制或矩阵组合策略,缺乏抽象概念理解能力[4]。
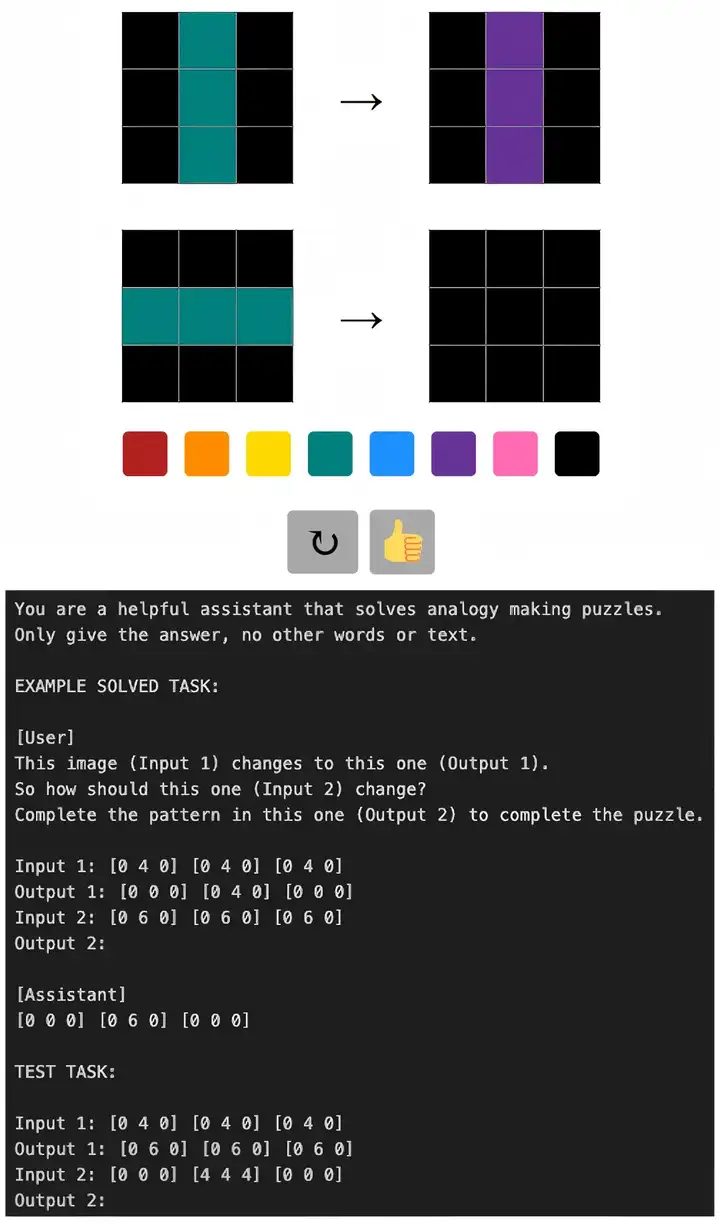
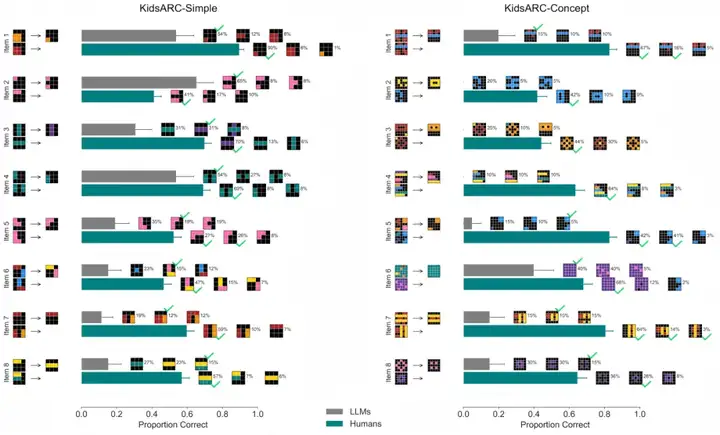
▷图6: 给人类和大模型的视觉类比推理问题示例,以及不同推理规则对应题目的大模型与人类的准确度对比. 图源:[4]
上述两类类比问题都可以算是“理科题目”,对于“文科生”的大模型,或许确实有些难了。相比之下,故事类比则主要考察大模型基于常识的类比能力。
这类题目通常给出1个几句话组成的短故事,然后要求参与者判断故事1和故事A或B哪一个更为相似,即识别短故事之间的相似性,并从多个选项中选择最符合类比关系的答案。
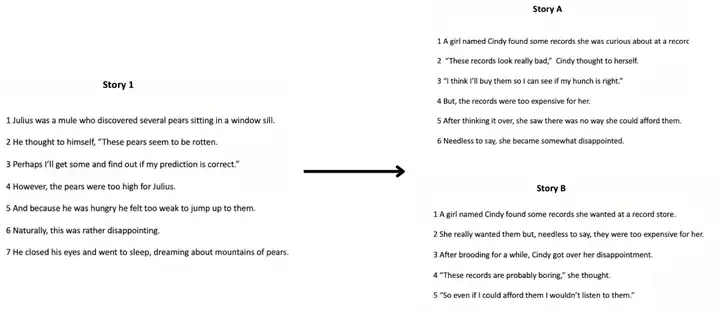
▷图7:相似故事的类比判断,题目的故事是一个吃不到葡萄说葡萄酸的骡子版本,故事A将主角换成了一个女孩,而在故事B中,主角没有获得相似的东西,是由于不喜欢而非拿不到. 图源:[2]
在Lewis & Mitchell的研究中,他们尝试了两种变体:一是随机打乱答案选项的顺序,二是保持核心关系不变,但重写故事的表述方式[2]。
在故事类比中,GPT-4 倾向于更频繁地选择第一个给出的答案作为正确答案,而人类则不受答案顺序的影响。此外,对于大模型,将故事用不同的话重述,也会降低在故事类比问题上的准确性[2]。

▷图8:文字类比问题上大模型的表现差异. 图源:[2]
故事类比更接近自然语言处理的实际应用场景,但研究结果却表明即使在语言模型的"主场"上,它们的类比推理能力仍然缺乏真正的灵活性和鲁棒性,过度依赖于表面特征与特定的答案格式,而非深层理解抽象关系。
为此,笔者也设想了一种判别方式,例如对比大模型和人类回答这类问题的准确性。可以生成很多组类比问题,并招募读过相关小说的普通人,以获取大众认知中的一般性回答,然后对比不同大模型和人类回答的差异性。
通过设置不同的细分问题,可以考察大模型与人类在类比能力方面的相似度及价值观对齐情况。
- 跨文体类比能力:在风格差异较大的作品间,如中文的金庸武侠或《红楼梦》与英文的《哈利波特》,大模型的类比准确性能否达到人类水平?
- 角色理解差异:大模型在处理男性和女性角色类比时,是否存在准确性差异?
- 群体偏好特征:大模型的类比偏好是否更接近特定人群(如不同性别、年龄段的人群)?
- 逻辑递推性:大模型的类比是否具有传递性特征(即当A>B且B>C时,是否必然推导出A>C)?

▷图9:大模型能够在跨越文学作品进行类比吗?本文作者与DeepSeek对话截图,其中前一道基本不会存在争议的人物类比,以及后一道可能存在回答差异的人物类比题目。
除了上述假想的对复杂人物性格的类比,还有研究测试了大模型在无预设条件下将抽象概念(如pull、flee)与空间符号(上下左右)进行类比推理的能力,结果显示,大模型和人类的相似性不算高[5]。不过考虑到这项研究强行要求将抽象概念(给定单词)和方位对应缺少现实意义,这里就不详细论述。
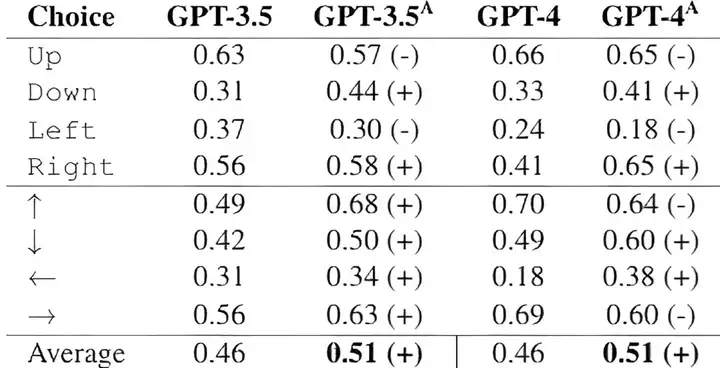
▷图10:大模型对抽象概念和人类类比的准确性评估.图源:[5]
基于以上研究发现,我们大致可以得到一个结论:声称大语言模型已具备一般推理能力或许为时过早。
尽管早期研究中大模型在特定任务上表现良好,但当测试难度提升时,它们的表现就不稳定了。一个模型在一组特定任务上表现良好,并不意味着它具有鲁棒性。之前有研究表明,在面对数学应用题时,只是更换题目中的人名,大模型的解答准确度都会明显下降,而增加无关的背景论述时,模型的性能下降则更加明显[6]。
这一发现对于在教育、法律和医疗等关键决策领域应用人工智能敲响了警钟,人工智能可以是一个强大的工具,但它还不能取代人类的思考和推理。例如,在教育领域,大模型生成的比喻确实能为教学提供帮助;然而,如果缺乏专业人士的审核与修正,这些类比可能存在潜在风险。

▷Micha Huigen
因此,研究人员需要开发和实施稳健性测试,以适应问题或情况中细微变化的能力。新的稳健性测试应包括一组公认的标准化任务,用以评估 AI 系统以及人类如何适应新情况。在实践中,大模型常会遇到之前分析数据中未曾遇到的新情况和挑战,而稳健性测试将为用户提供衡量大型语言模型可信度的方式。
与此同时,24年的机器学习顶会ICLR的一项研究展示了另一个发展方向:通过类比推理框架,让大模型自动生成新的规则来应对未知场景[7]。这种基于提示词工程的方法在多个测试基准上都取得了显著性能提升,表明提升大模型的类比能力不仅是评估其稳健性的重要维度,更是增强模型泛化能力的关键路径。这两种方法相辅相成,共同推动着大模型向更可靠、更智能的方向发展。
展望未来,大模型类比思维的研究,或可从中国传统中汲取灵感。中国古典文学中的对联与律诗,本质上就是一种精妙的类比系统,其中蕴含着严谨的对应规则和丰富的语义关联。通过这些结构化的语言数据集对大模型进行微调,可能为增强其类比推理能力开辟新途径。
就像中文指令微调数据集 COIG-CQIA,为了提升模型在编程及数学问题上的表现,也曾使用了中文互联网社区数据“弱智吧”的标题作为训练指令。这些来自不同领域的实践表明,结构化的类比思维模式,无论是传统文学还是现代网络社群数据集,都可能成为提升人工智能认知能力的重要工具。
毕竟,类比思维的本质是通用的。
[1] Taylor Webb, Keith J. Holyoak, and Hongjing Lu. Emergent analogical reasoning in large language models. Nature Human Behaviour, 7(9):1526–1541, 2023.
[2] Lewis, Martha & Mitchell, Melanie. (2024). Evaluating the Robustness of Analogical Reasoning in Large Language Models. 10.48550/arXiv.2411.14215.
[3] Stevenson CE, Pafford A, van der Maas HLJ, Mitchell M. (2024). Can large language models generalize analogy solving like children can? arXiv.2411.02348v1.
文章来自于“追问nextquestion”,作者“郭瑞东”。



【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
