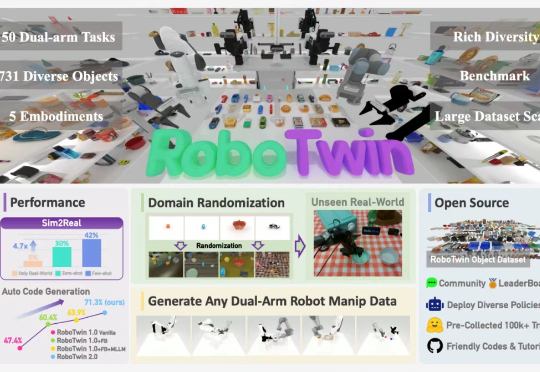
RoboTwin系列新作:开源大规模域随机化双臂操作数据合成器与评测基准集
RoboTwin系列新作:开源大规模域随机化双臂操作数据合成器与评测基准集最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。
来自主题: AI技术研报
9434 点击 2025-07-08 11:18
 搜索
搜索
最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。

普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。

杯子在我的左边还是右边?
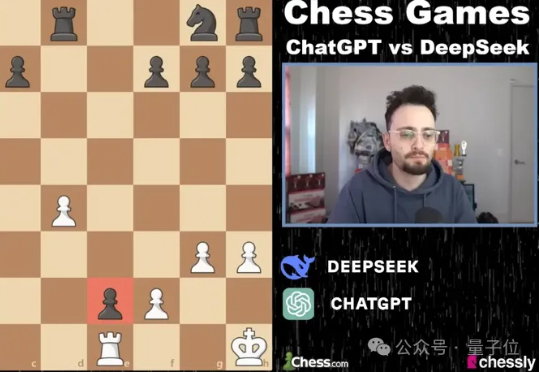
AI社区掀起用大模型玩游戏之风!例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。
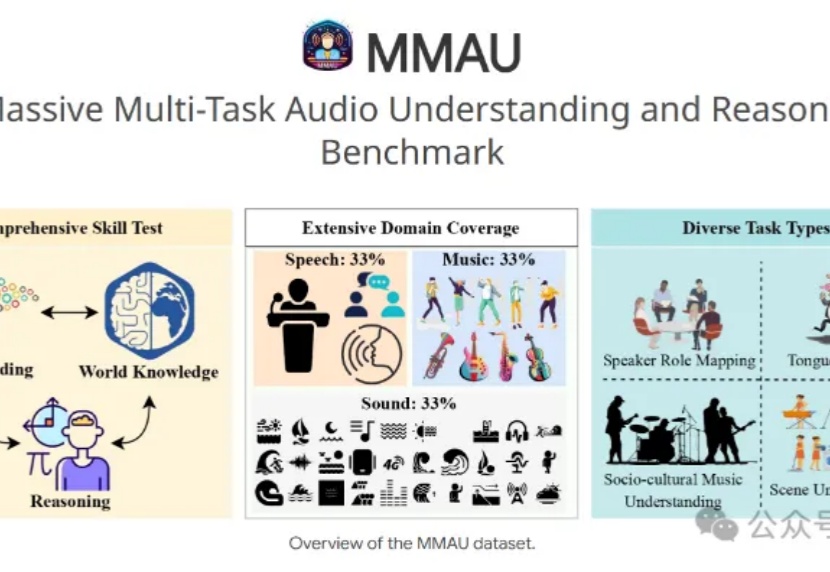
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?

基于闭源评测基准,近期司南针对国内外主流多模态大模型进行了全面评测,现公布司南首期多模态模型闭源评测榜单。首期榜单共包含 48 个多模态模型,其中包含:3 个国内 API 模型:GLM-4v-Plus-20250111 (智谱),Step-1o (阶跃),BailingMM-Pro-0120 (蚂蚁)
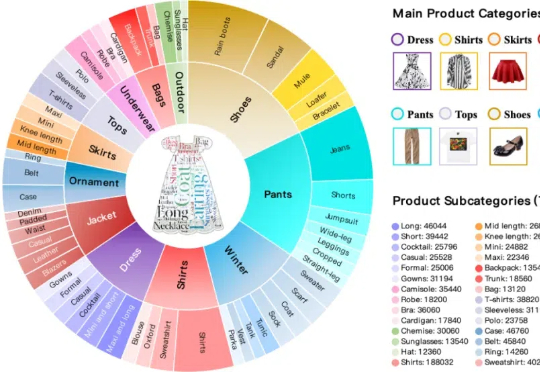
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。