
首个地球科学智能体Earth-Agent来了,解锁地球观测数据分析新范式
首个地球科学智能体Earth-Agent来了,解锁地球观测数据分析新范式当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」
来自主题: AI技术研报
8968 点击 2025-10-28 14:45
当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」

2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?
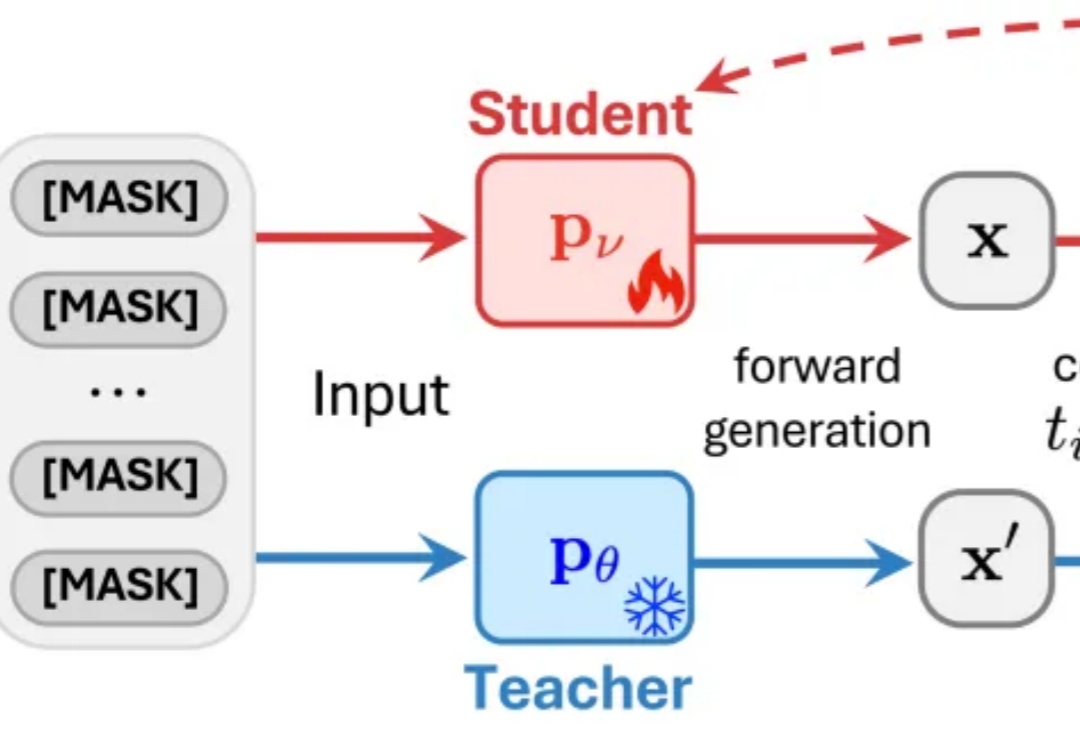
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。

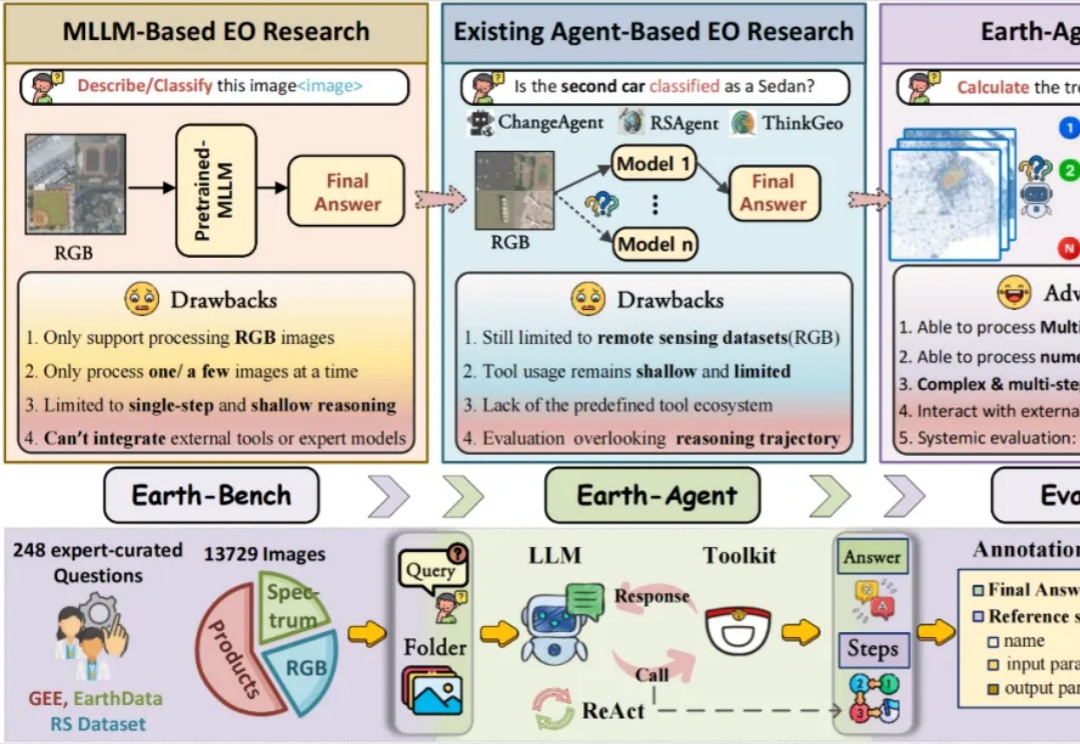
当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
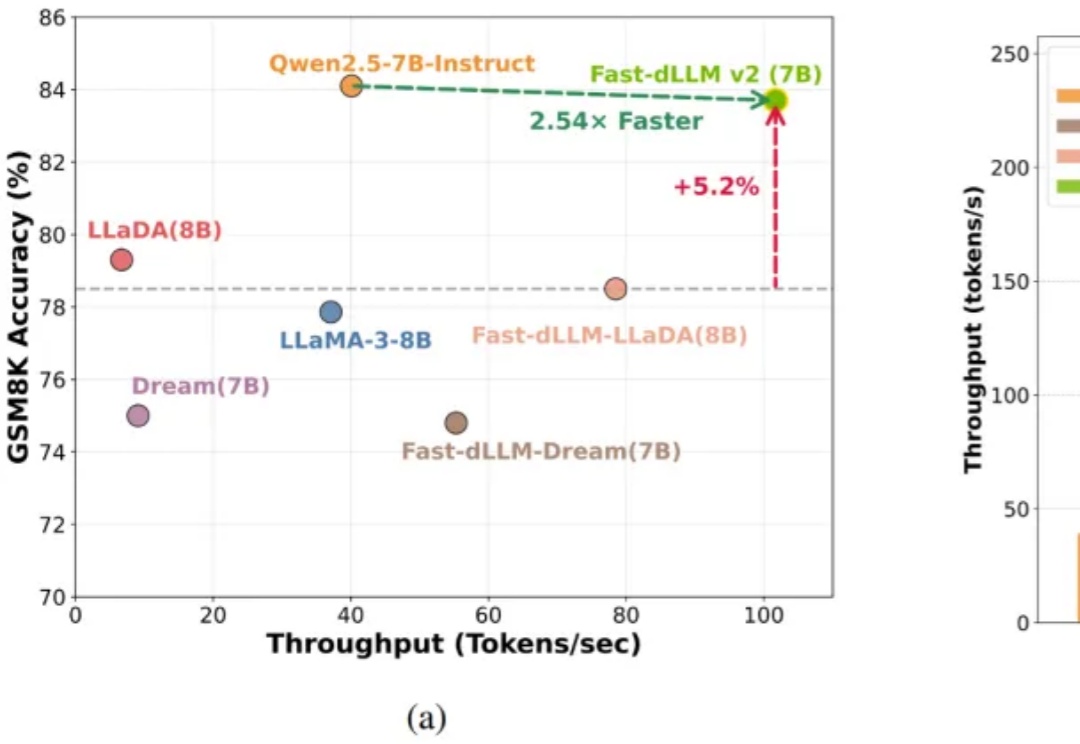
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
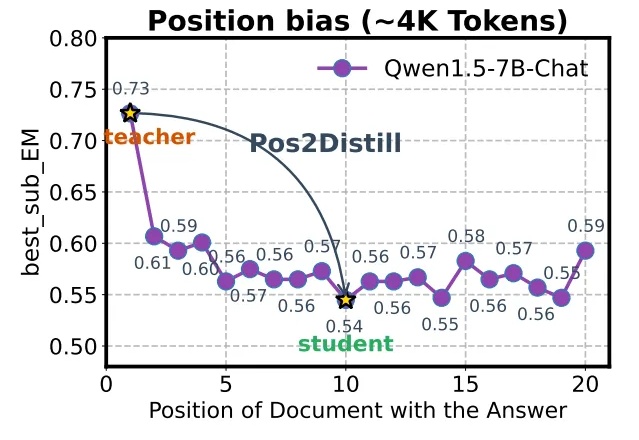
语言模型遭遇严重的位置偏见,即模型对不同上下⽂位置的敏感度不⼀致。模型倾向于过度关注输⼊序列中的特定位置,严重制约了它们在复杂推理、⻓⽂本理解以及模型评估等关键任务上的表现。

聚焦大型语言模型(LLMs)的安全漏洞,研究人员提出了全新的越狱攻击范式与防御策略,深入剖析了模型在生成过程中的注意力变化规律,为LLMs安全研究提供了重要参考。论文已被EMNLP2025接收
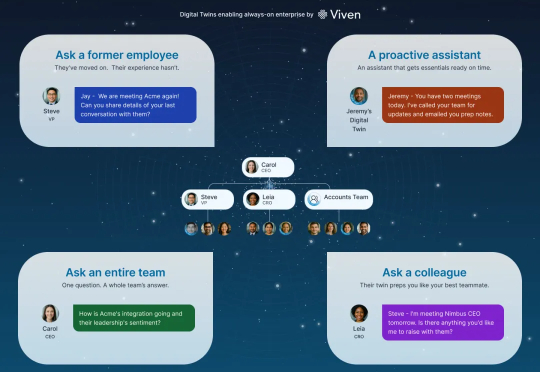
Viven 的核心创新在于,它为每个员工创建了一个个性化的大语言模型,实质上就是一个数字分身。这个分身通过访问员工的内部电子文档,包括邮件、Slack 消息、Google Docs、会议记录等,学习这个人如何思考、如何沟通、拥有什么知识。关键是,这个学习过程是自动进行的,不需要员工做任何额外工作。你只需正常工作,你的数字分身就会不断更新和进化。
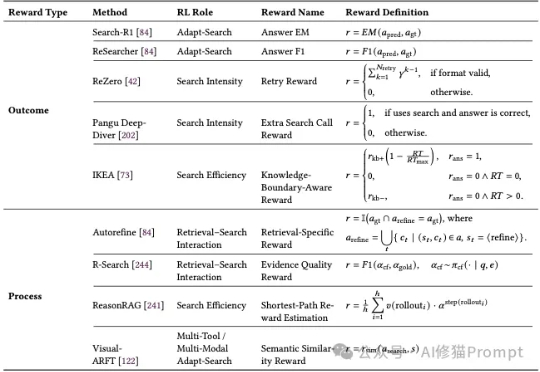
大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。

香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。