
意识智能体:大模型的下一个进化方向?
意识智能体:大模型的下一个进化方向?机器具备意识吗?本文对AI意识(AI consciousness)进行了考察,特别是深入探讨了大语言模型作为高级计算模型实例是否具备意识,以及AI意识的必要和充分条件。
来自主题: AI技术研报
9484 点击 2025-09-11 09:55
机器具备意识吗?本文对AI意识(AI consciousness)进行了考察,特别是深入探讨了大语言模型作为高级计算模型实例是否具备意识,以及AI意识的必要和充分条件。
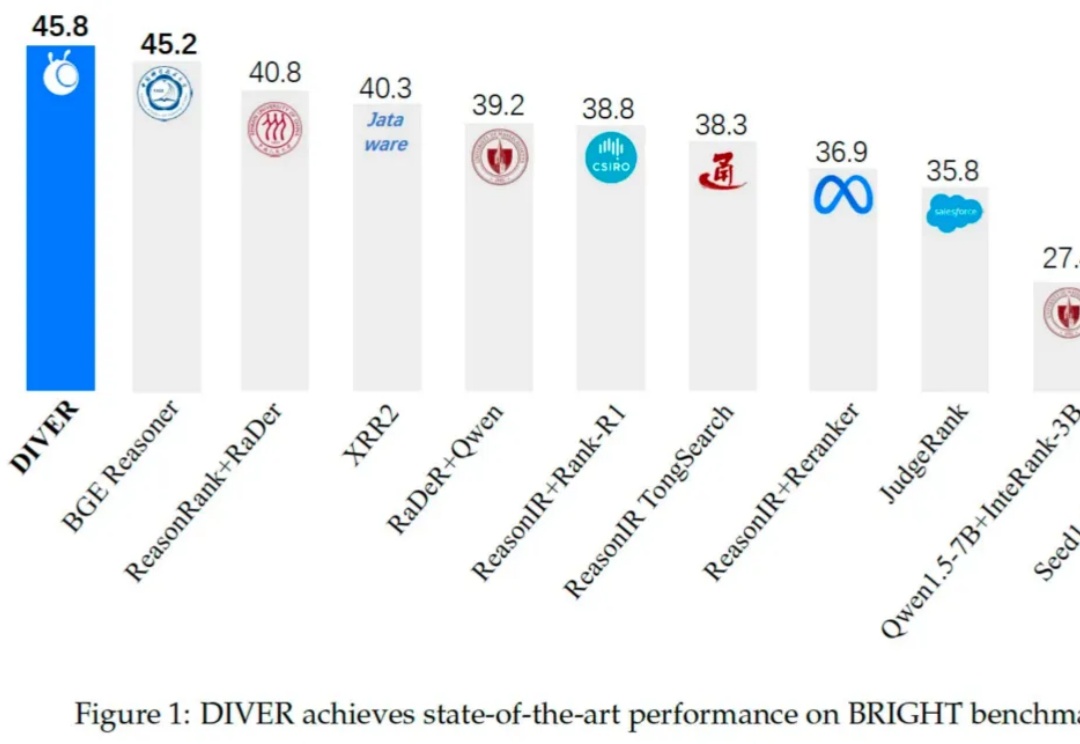
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
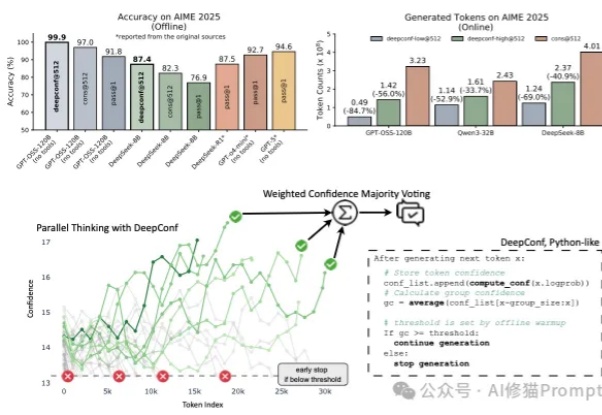
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。
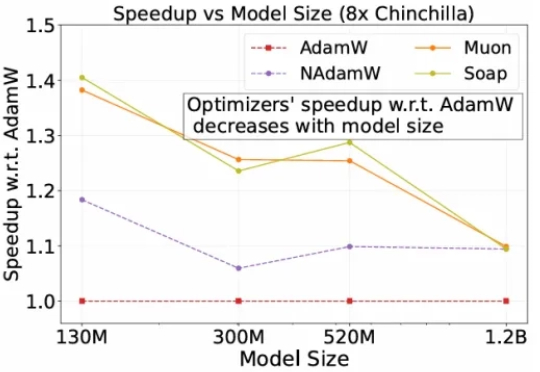
自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。
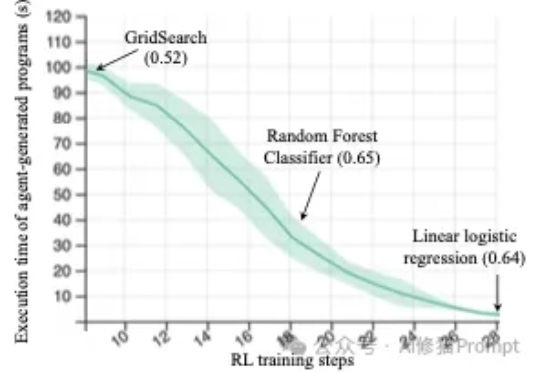
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。
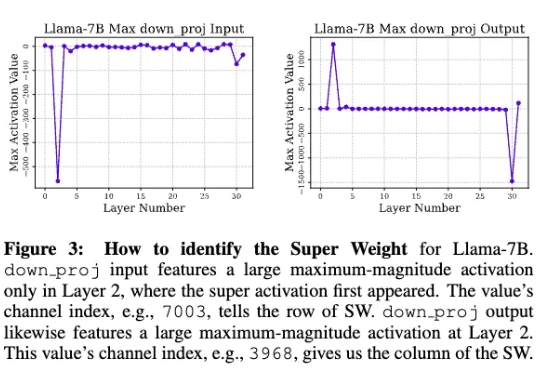
苹果研究人员发现,在大模型中,极少量的参数,即便只有0.01%,仍可能包含数十万权重,他们将这一发现称为「超级权重」。超级权重点透了大模型「命门」,使大模型走出「炼丹玄学」。
近日,微软旗下的协作式编程平台 GitHub 正深化与埃隆·马斯克旗下 xAI 公司的合作,将 xAI 的 Grok Code Fast 1 大型语言模型(LLM)的早期使用权整合到 GitHub Copilot 中。
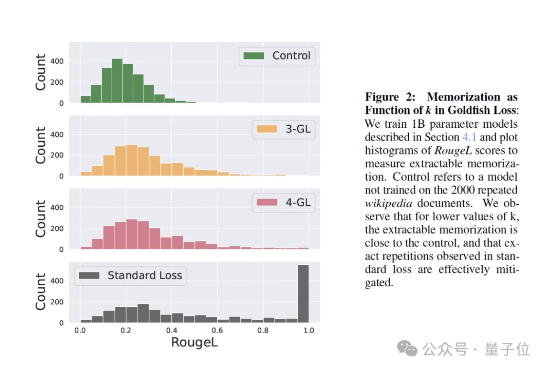
训练大模型时,有时让它“记性差一点”,反而更聪明! 大语言模型如果不加约束,很容易把训练数据原封不动地复刻出来。为解决这个问题,来自马里兰大学、图宾根大学和马普所的研究团队提出了一个新方法——金鱼损失(Goldfish Loss)。

在这场以大型语言模型(LLM)为核心的 AI 浪潮中,苹果似乎一直保持着低调,很少出现在技术报道的前沿。尽管如此,时不时地,该公司也能拿出一些非常亮眼的研究成果,比如能在 iPhone 上直接运行的高效视觉语言模型 FastVLM。