
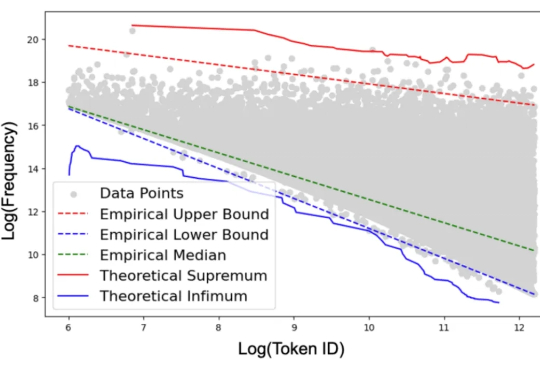
ChatGPT到底学了多少「污言秽语」?清华团队首提大语言模型中文语料污染治理技术
ChatGPT到底学了多少「污言秽语」?清华团队首提大语言模型中文语料污染治理技术如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。
来自主题: AI技术研报
8568 点击 2025-08-26 12:11
如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。
近年来,大语言模型(LLMs)展现出强大的语言理解与生成能力,推动了文本生成、代码生成、问答、翻译等任务的突破。代表性模型如 GPT、Claude、Gemini、DeepSeek、Qwen 等,已经深刻改变了人机交互方式。
AI一日,人间一年。 大语言模型的战局刚刚尘埃落定,Agent的热潮又汹涌而至。

本文介绍使用四块Framework主板构建AI推理集群的完整过程,并对其在大语言模型推理任务中的性能表现进行了系统性评估。该集群基于AMD Ryzen AI Max+ 395处理器,采用mini ITX规格设计,可部署在10英寸标准机架中。
近期多项研究 [1-2] 表明,即使是经过安全对齐的大语言模型,也可能在正常开发场景中无意间生成存在漏洞的代码,为后续被利用埋下隐患;而在恶意用户手中,这类模型还能显著加速恶意软件的构建与迭代,降低攻击门槛、缩短开发周期。
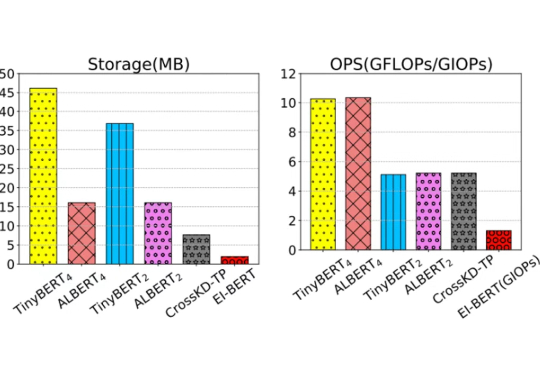
在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。
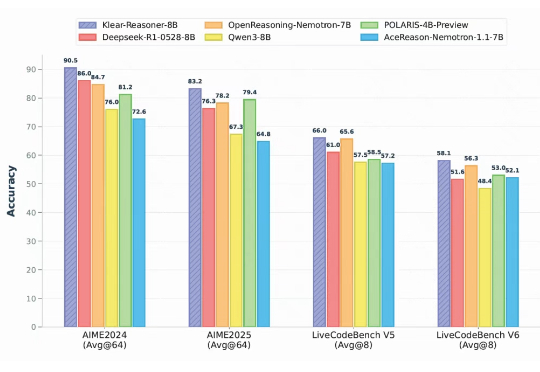
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
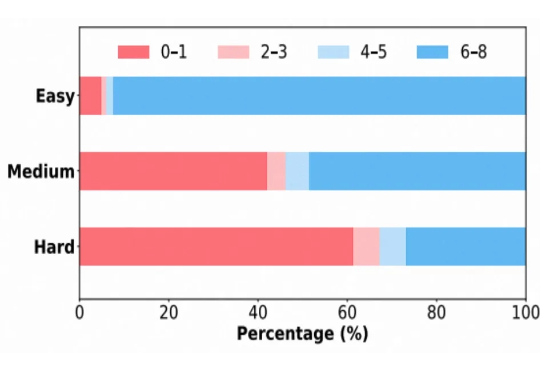
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。

在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
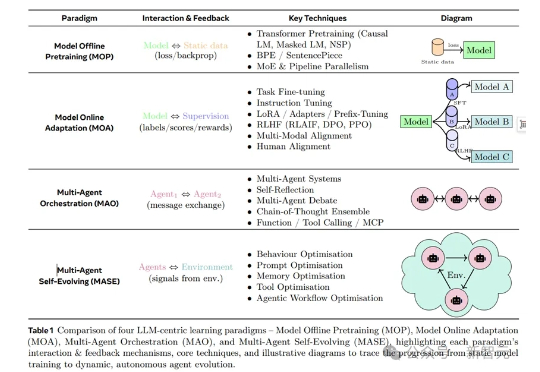
在AI浪潮席卷全球的2025年,大语言模型(LLM)已从单纯的聊天工具演变为能规划、决策的智能体。但问题来了:这些智能体一旦部署,就如「冻结的冰块」,难以适应瞬息万变的世界。