

字节Seed发布扩散语言模型,推理速度达2146 tokens/s,比同规模自回归快5.4倍
字节Seed发布扩散语言模型,推理速度达2146 tokens/s,比同规模自回归快5.4倍用扩散模型写代码,不仅像开了倍速,改起来还特别灵活! 字节Seed最新发布扩散语言模型Seed Diffusion Preview,这款模型主要聚焦于代码生成领域,它的特别之处在于采用了离散状态扩散技术,在推理速度上表现出色。
来自主题: AI资讯
7955 点击 2025-08-01 16:04
用扩散模型写代码,不仅像开了倍速,改起来还特别灵活! 字节Seed最新发布扩散语言模型Seed Diffusion Preview,这款模型主要聚焦于代码生成领域,它的特别之处在于采用了离散状态扩散技术,在推理速度上表现出色。
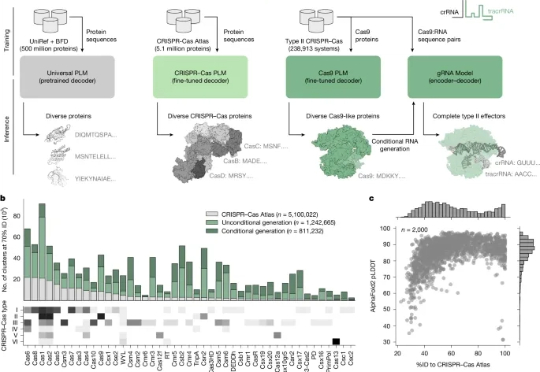
当前,CRISPR/Cas系统是应用最广泛的基因组编辑技术。它彻底改变了生命科学研究,并有望改变医学和农业。然而,CRISPR系统在历史上一直具有设计挑战性,因为它们的分子空间很大,需要跨多个维度进行优化。而蛋白质语言模型的出现,给CRISPR系统带来了定制化的转机。
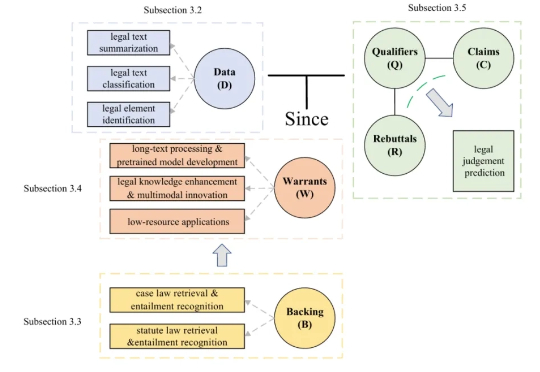
研究人员首次系统综述了大型语言模型(LLM)在法律领域的应用,提出创新的双重视角分类法,融合法律推理框架(经典的法律论证型式框架)与职业本体(律师/法官/当事人角色),统一梳理技术突破与伦理治理挑战。论文涵盖LLM在法律文本处理、知识整合、推理形式化方面的进展,并指出幻觉、可解释性缺失、跨法域适应等核心问题,为下一代法律人工智能奠定理论基础与实践路线图。
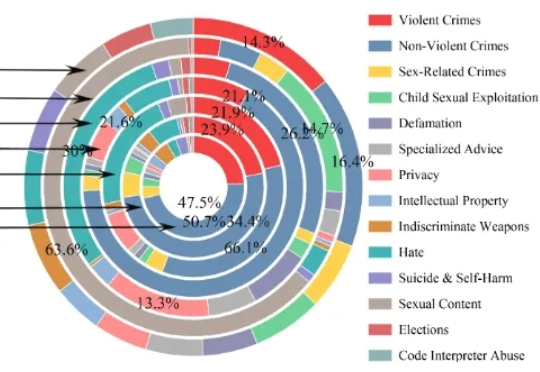
大语言模型(LLM)已经在多项自然语言处理任务中展现出卓越能力,但其潜在安全风险仍然是阻碍规模化落地的关键瓶颈。目前社区用于安全对齐的公开数据集,往往偏重于「词汇多样性」,即让同一种风险指令尽可能用不同的表达方式出现,却很少系统考虑指令背后的「恶意意图多样性」以及「越狱策略多样性」。

Anthropic 联合创始人 Jared Kaplan 是一名理论物理学家,研究兴趣广泛,涉及有效场论、粒子物理、宇宙学、散射振幅以及共形场论等。过去几年,他还与物理学家、计算机科学家们合作开展机器学习研究,包括神经模型以及 GPT-3 语言模型的 Scaling Law。
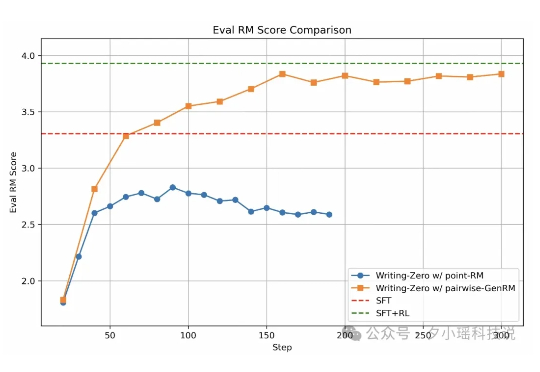
近年来, 大语言模型 (LLM) 在数学、编程等 "有标准答案" 的任务上取得了突破性进展, 这背后离不开 "可验证奖励" (Reinforcement Learning with Verifiable Rewards, RLVR) 技术的加持。RLVR 依赖于参考信号, 即通过客观标准答案来验证模型响应的可靠性。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。

对于任何书面文件,比如此刻你正阅读的这篇文章,追问它出自谁手,似乎理所当然。为此,你可能会八卦一番作者履历,了解作者的一些背景,因作者身份能助你辨认他所写内容的权威性。譬如,对于此文,如果我的履历显示我任职于美国的一所大学的传播学教授,你可能会据此认定我谈论大语言模型相关的颠覆性事件是恰如其分的,甚至因此信任我的观点。毕竟,你已确认了“作者”的身份并发现他在此领域颇有建树。

近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。
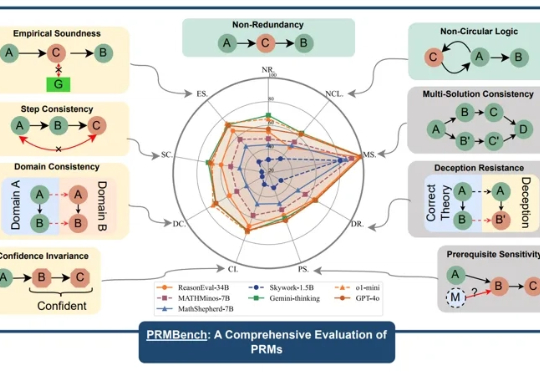
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。