

刚刚,阿里端出春节「硬菜」千问 3.5!我让它做了个拜年网页,结果出乎意料
刚刚,阿里端出春节「硬菜」千问 3.5!我让它做了个拜年网页,结果出乎意料没有让我们等待多久,阿里刚刚正式发布并开源了 Qwen3.5 系列模型,页面显示有两款模型,分别为最新大语言模型的 Qwen3.5-Plus,以及定位为开源系列旗舰的 Qwen3.5-397B-A17B。两者均支持文本处理与多模态任务。
来自主题: AI资讯
11133 点击 2026-02-16 20:05
没有让我们等待多久,阿里刚刚正式发布并开源了 Qwen3.5 系列模型,页面显示有两款模型,分别为最新大语言模型的 Qwen3.5-Plus,以及定位为开源系列旗舰的 Qwen3.5-397B-A17B。两者均支持文本处理与多模态任务。
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
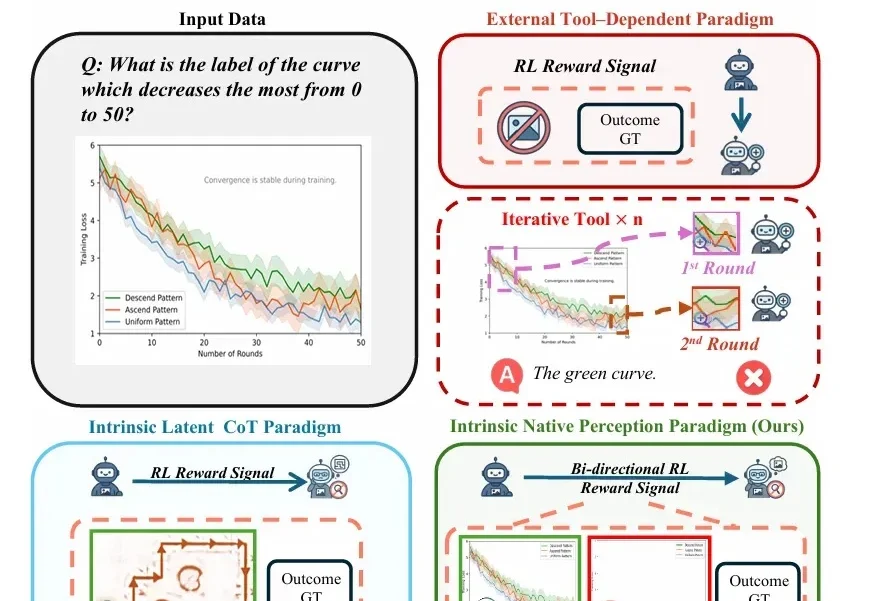
随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。

大规模表格模型(LTM)而非大规模语言模型(LLM)的 Fundamental 公司 Nexus 模型,在多个重要方面突破了当代人工智能实践。该模型具有确定性——即每次被询问相同问题时都会给出相同答案——且不依赖定义当代大多数人工智能实验室模型的 Transformer 架构 。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
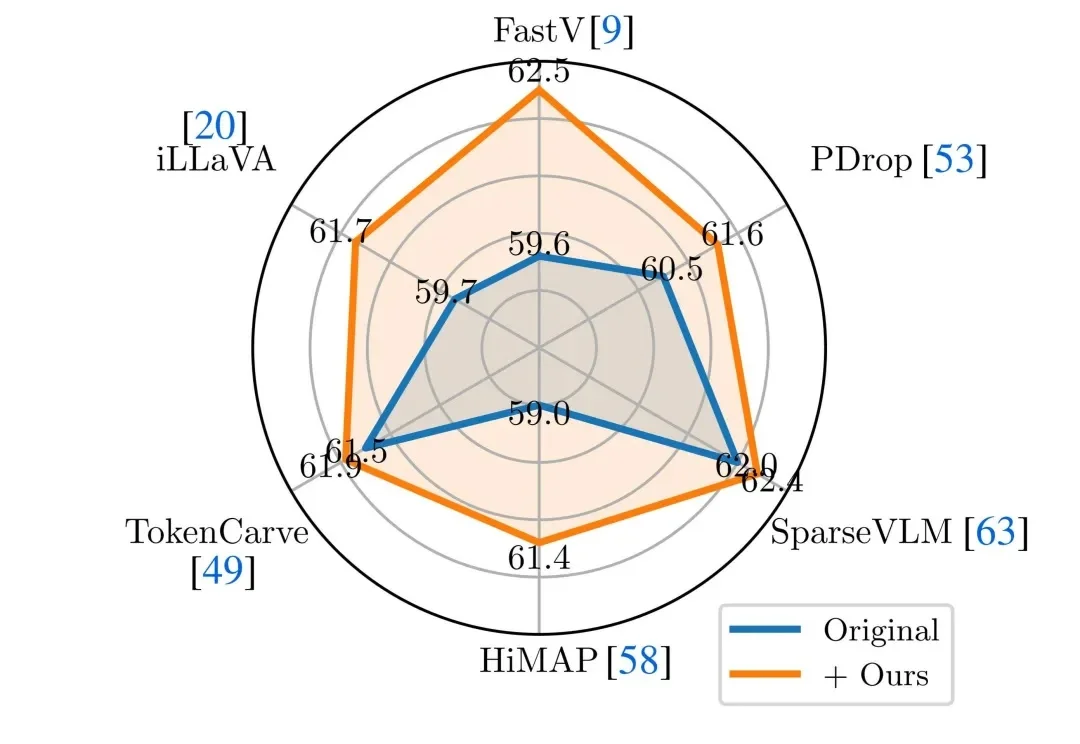
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
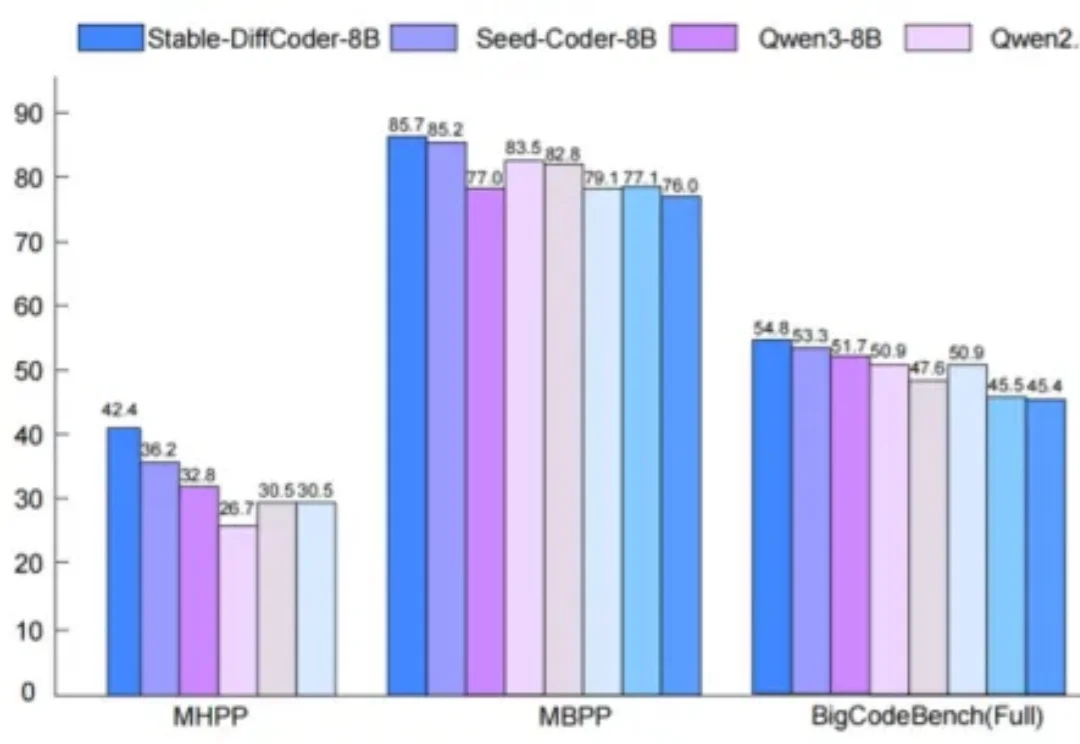
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
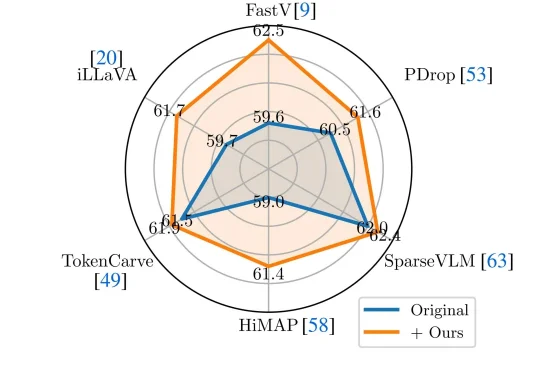
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。