

独立游戏小团队也能在GDC开讲座?|AI原生游戏《1001夜》在旧金山的1周收获
独立游戏小团队也能在GDC开讲座?|AI原生游戏《1001夜》在旧金山的1周收获一个月前,在旧金山全球游戏开发者大会上,AI原生独立游戏《1001夜》的制作人担任GDC Al Summit的演讲者,分享游戏中大语言模型驱动的核心玩法设计,与世界各地的游戏开发者进行了深入的交流。
来自主题: AI资讯
9970 点击 2025-05-11 14:27
一个月前,在旧金山全球游戏开发者大会上,AI原生独立游戏《1001夜》的制作人担任GDC Al Summit的演讲者,分享游戏中大语言模型驱动的核心玩法设计,与世界各地的游戏开发者进行了深入的交流。
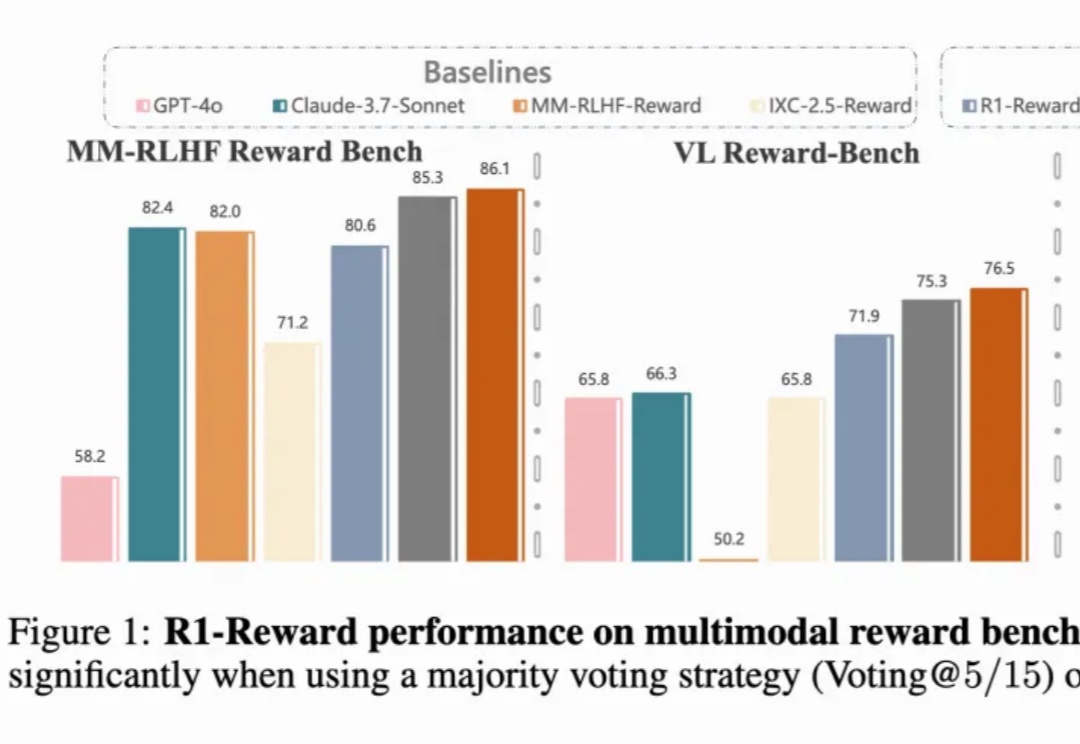
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
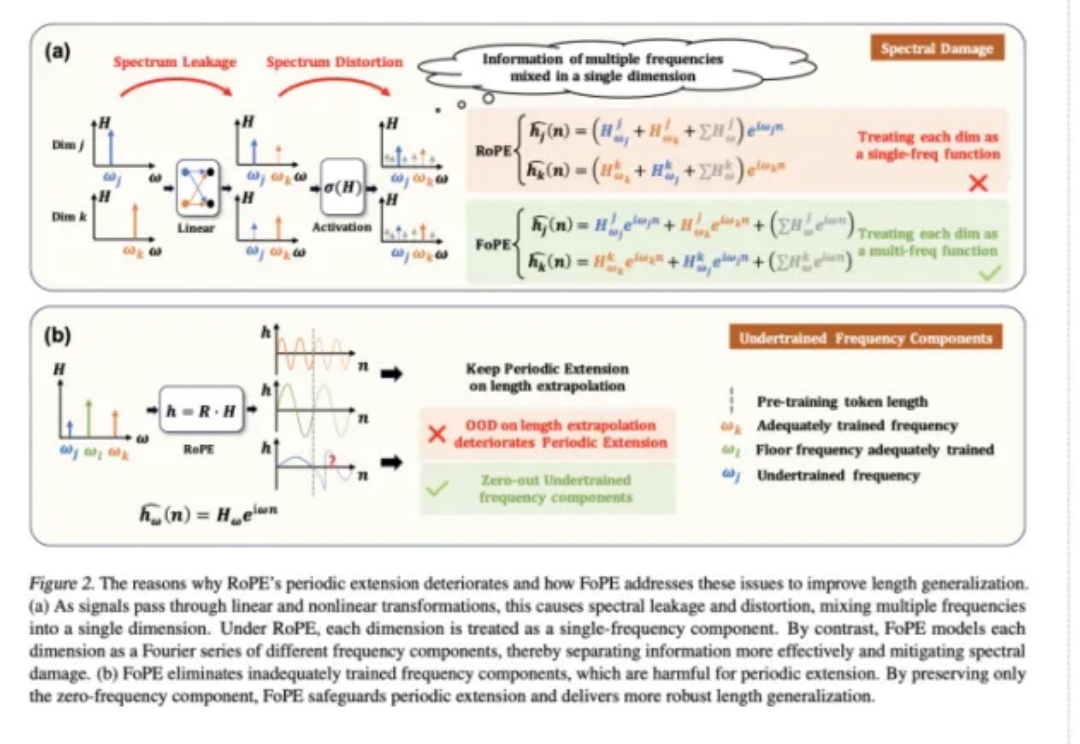
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
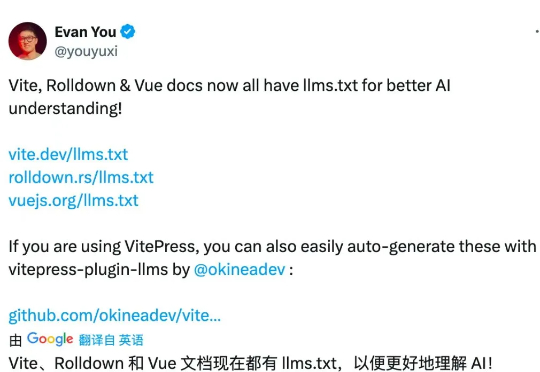
在前端开发领域,Vue 框架一直以其易用性和灵活性受到广大开发者的喜爱。而如今,Vue 生态在人工智能(AI)领域的应用上又迈出了重要的一步。尤雨溪近日宣布,Vue、Vite 和 Rolldown 的文档网站均已添加了llms.txt文件,这一举措旨在让大型语言模型(LLM)更方便地理解这些前端技术。

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。

大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。

在复杂、未知的现实环境中,传统导航方法往往依赖闭集语义或事先构建的地图,难以实现真正的“按需探索”。为打破这一瓶颈,本文提出了 FindAnything ——一套融合视觉语言模型的对象为中心、开放词汇三维建图与探索系统。

近日,阿里云通义点金团队与苏州大学携手合作,在金融大语言模型领域推出了突破性的创新成果:DianJin-R1。

在人工智能领域,语言模型的发展日新月异,推理能力作为语言模型的核心竞争力之一,一直是研究的焦点,许多的 AI 前沿人才对 AI 推理的效率进行研究。
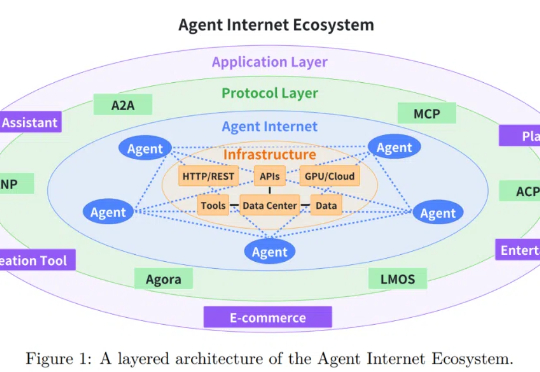
随着大语言模型 (LLM) 技术的迅猛发展,基于 LLM 的智能智能体在客户服务、内容创作、数据分析甚至医疗辅助等多个行业领域得到广泛应用。