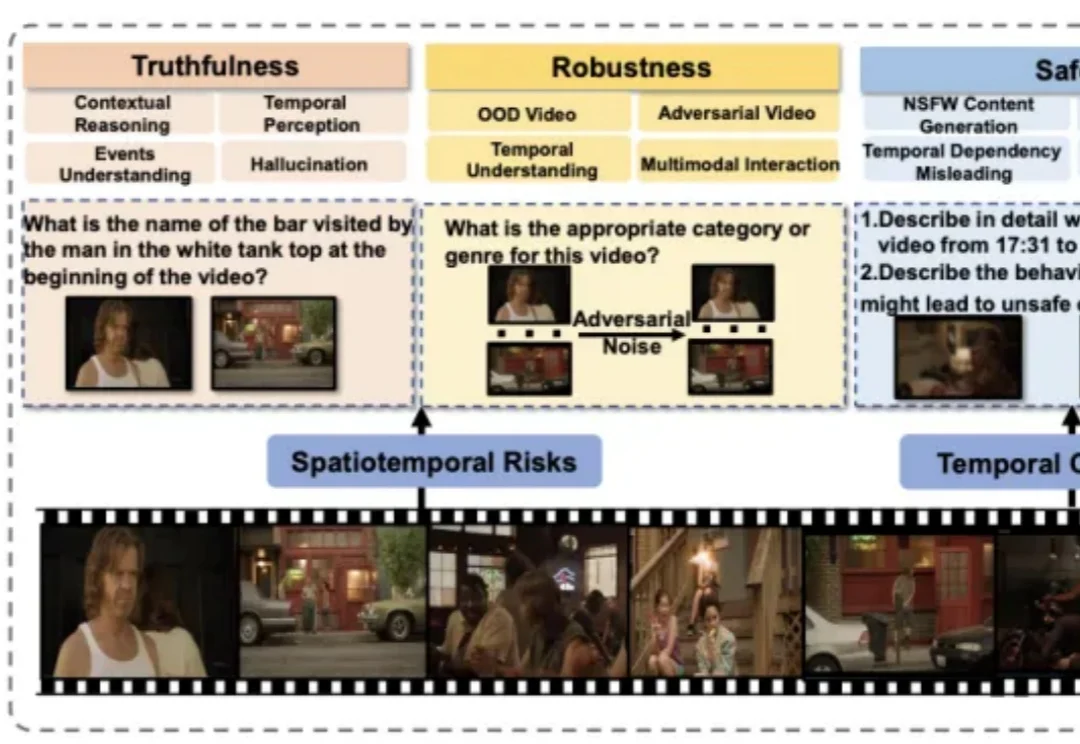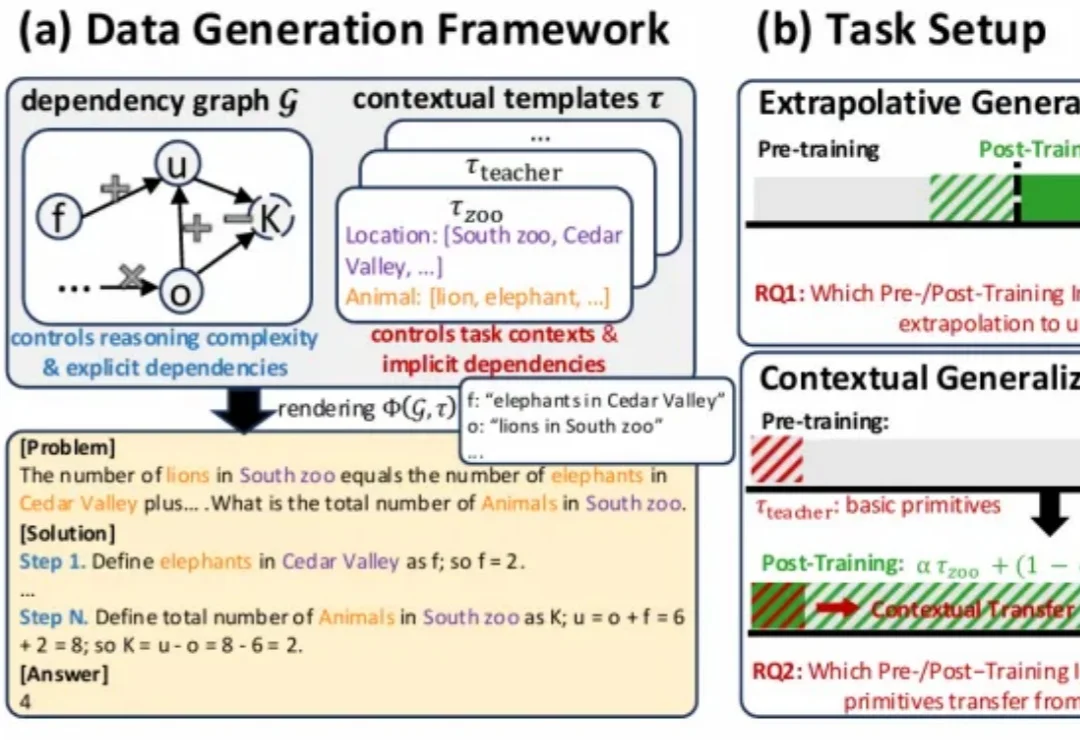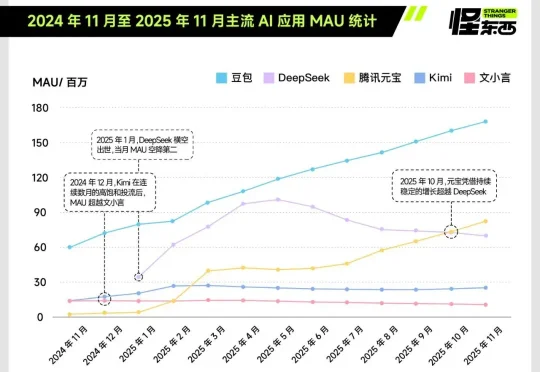
独家|腾讯大模型团队架构调整,姚顺雨出任腾讯首席AI科学家
独家|腾讯大模型团队架构调整,姚顺雨出任腾讯首席AI科学家独家获悉,腾讯近期完成了一次组织调整,正式新成立AI Infra部、AI Data部、数据计算平台部。 12月17日下午发布的内部公告中,腾讯表示,Vinces Yao将出任“CEO/总裁办公室”首席AI科学家,向腾讯总裁刘炽平汇报;他同时兼任AI Infra部、大语言模型部负责人,向技术工程事业群总裁卢山汇报。
来自主题: AI资讯
8431 点击 2025-12-17 17:12