VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
来自主题: AI技术研报
7533 点击 2025-10-29 16:28
 搜索
搜索
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。

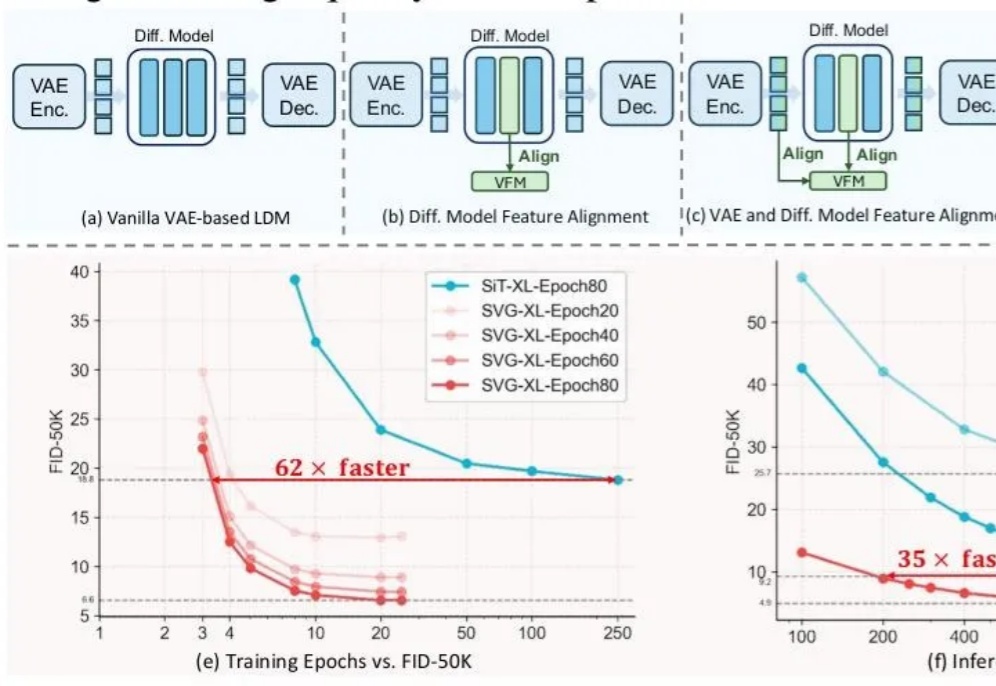
长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。

近日,Meta 研究者 Lucas Beyer 在 𝕏 上发起的一个投票吸引了众多围观。说是围观,是因为他给出的四个选项都是当今或过去的 AI 大厂,显然,并不是每个人都有在这些大厂的面试经历,但这并不妨碍全球 AI 开发者的好奇心。
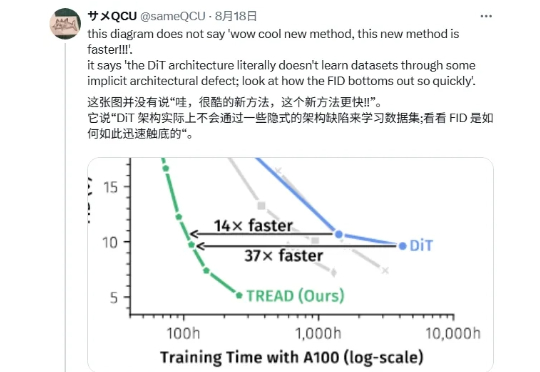
「兄弟们,DiT 是错的!」 最近一篇帖子在 X 上引发了很大的讨论,有博主表示 DiT 存在架构上的缺陷,并附上一张论文截图。

Science重磅揭露科研圈两大乱象:一是「论文工厂」已形成庞大产业链,部分编辑、作者、中介相互勾结;二是ChatGPT悄然渗入科研写作,22%计算机论文含AI痕迹。系统性造假与技术滥用,正重塑学术界根基。
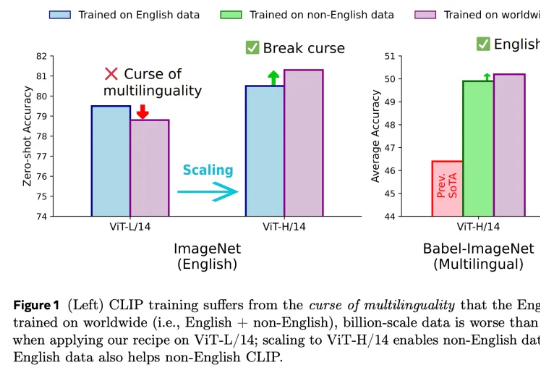
在人工智能领域,对比语言 - 图像预训练(CLIP) 是一种流行的基础模型,由 OpenAI 提出
大神也陷入学术不端质疑,偷偷在论文里藏提示词刷好评?最新进展是,谢赛宁本人下场道歉了:这并不道德。对于任何有问题的投稿,共同作者都有责任,没有任何借口。

曾几何时,用文字生成图像已经变得像用笔作画一样稀松平常。