
英伟达新GPU,超长上下文/视频生成专用
英伟达新GPU,超长上下文/视频生成专用老黄对token密集型任务下手了。
来自主题: AI资讯
10109 点击 2025-09-10 12:19
 搜索
搜索
老黄对token密集型任务下手了。

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。
这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。
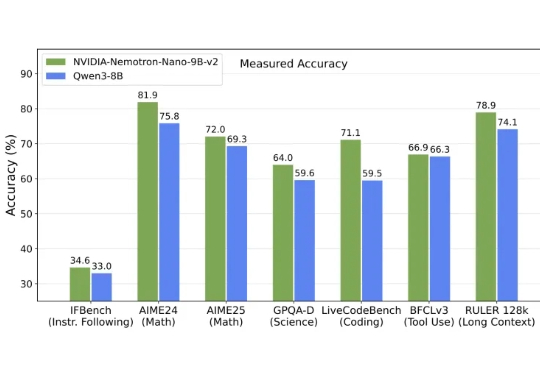
英伟达发布全新架构9B模型,以Mamba-Transformer混合架构实现推理吞吐量最高提升6倍,对标Qwen3-8B并在数学、代码、推理与长上下文任务中表现持平或更优。

MiniMax 在 7 月 10 日面向全球举办了 M1 技术研讨会,邀请了来自香港科技大学、滑铁卢大学、Anthropic、Hugging Face、SGLang、vLLM、RL领域的研究者及业界嘉宾,就模型架构创新、RL训练、长上下文应用等领域进行了深入的探讨。
超长上下文窗口的大模型也会经常「失忆」,「记忆」也是需要管理的。
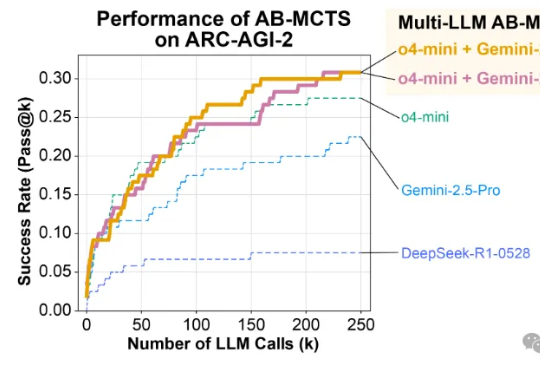
ChatGPT的对话流畅性、Gemini的多模态能力、DeepSeek的长上下文分析……
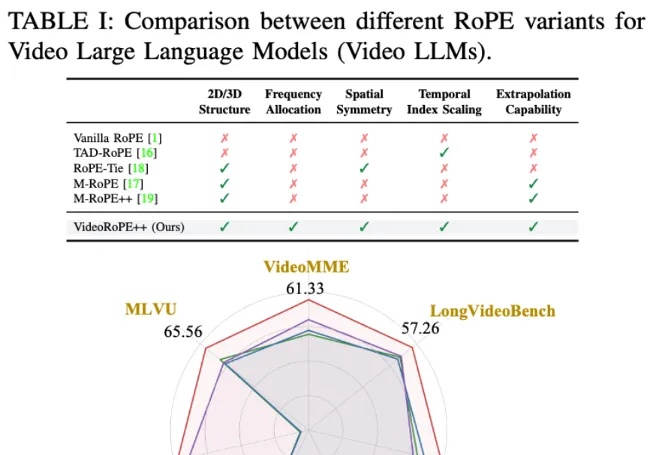
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
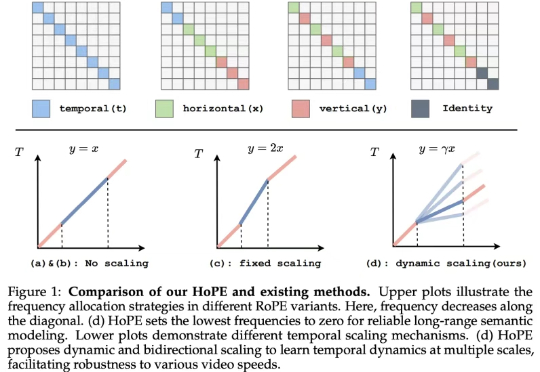
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。