长文本向量模型在4K Tokens 之外形同盲区?
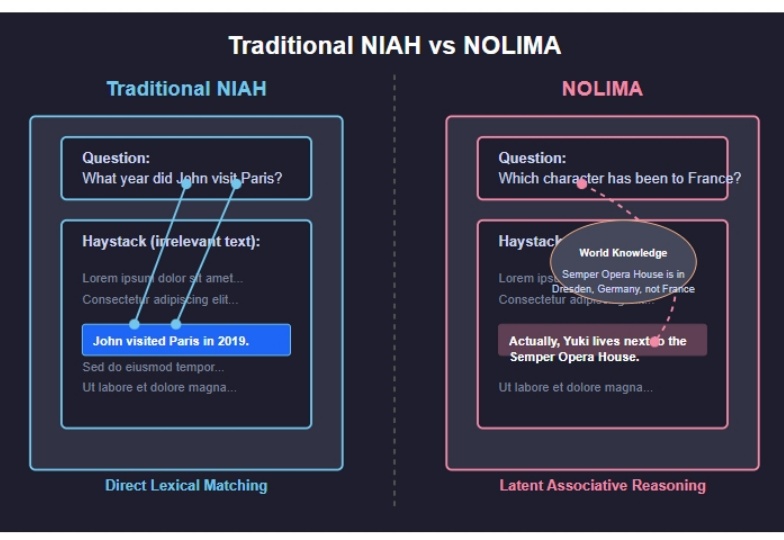
长文本向量模型在4K Tokens 之外形同盲区?2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
来自主题: AI技术研报
6416 点击 2025-03-12 15:08
 搜索
搜索
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
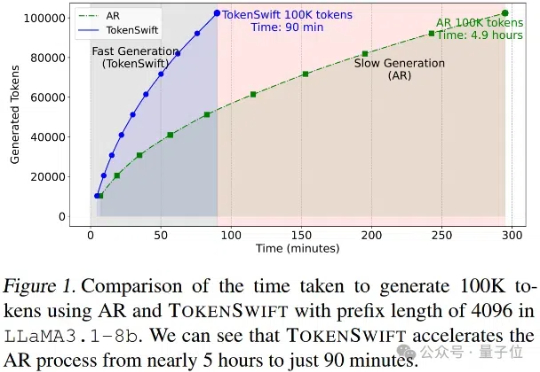
大语言模型长序列文本生成效率新突破——生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。
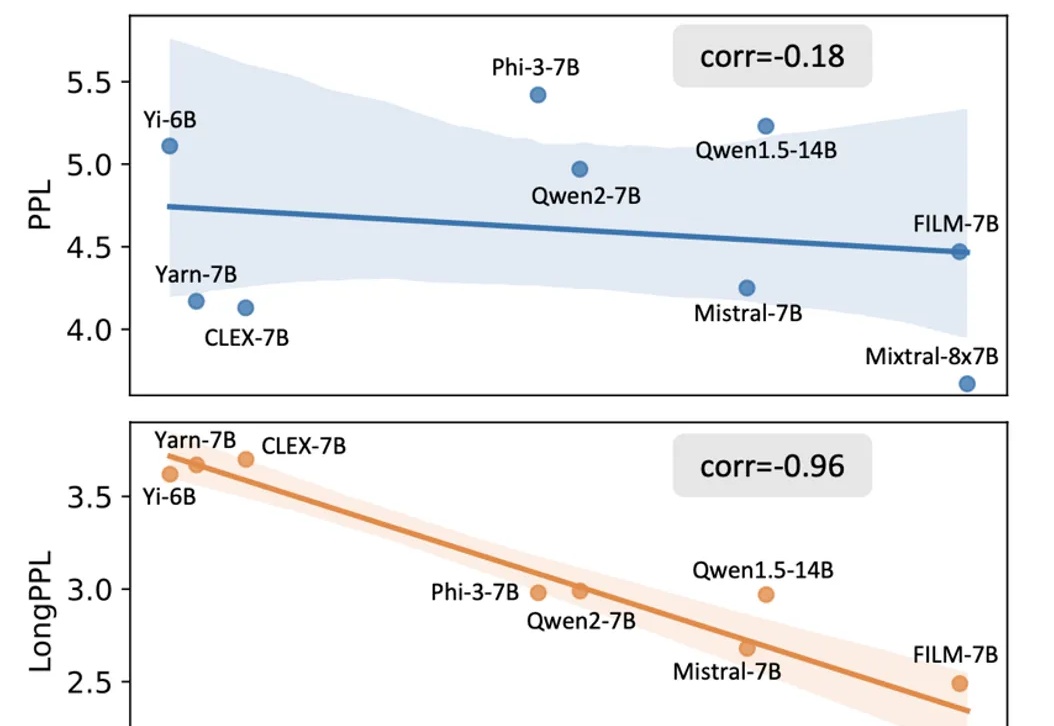
随着大模型在长文本处理任务中的应用日益广泛,如何客观且精准地评估其长文本能力已成为一个亟待解决的问题。

LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?
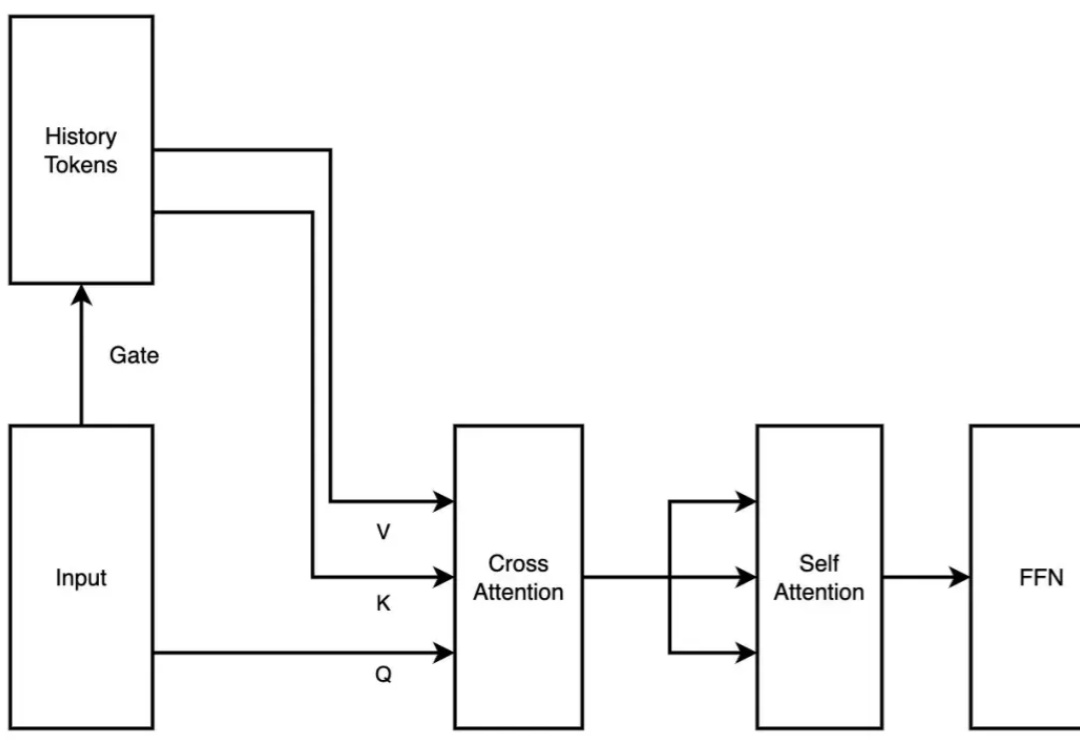
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。

谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。
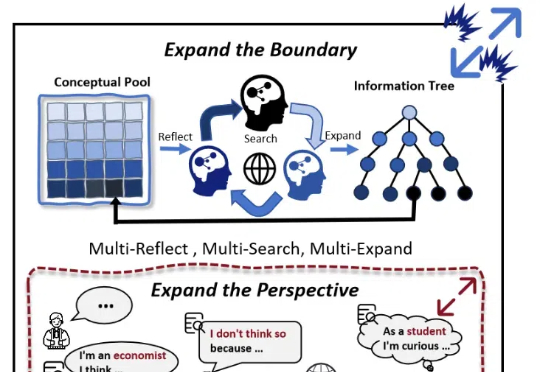
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。

大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。