卷起来了!长文本向量模型分块策略大比拼
卷起来了!长文本向量模型分块策略大比拼长文本向量模型能够将十页长的文本编码为单个向量,听起来很强大,但真的实用吗? 很多人觉得... 未必。 直接用行不行?该不该分块?怎么分才最高效?本文将带你深入探讨长文本向量模型的不同分块策略,分析利弊,帮你避坑。
来自主题: AI技术研报
10416 点击 2024-12-13 11:33
 搜索
搜索
长文本向量模型能够将十页长的文本编码为单个向量,听起来很强大,但真的实用吗? 很多人觉得... 未必。 直接用行不行?该不该分块?怎么分才最高效?本文将带你深入探讨长文本向量模型的不同分块策略,分析利弊,帮你避坑。

在闭着眼睛听一首歌的时候,你有没有在脑海里想象过,应该搭配什么画面? Kimi 内测的最新功能「创作音乐视频」,就是奔着当 MV 导演去的。长文本领先的 Kimi,默不作声地「跨界」了。APPSO 也受邀首批体验了这一新功能。

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。

善智者,动于九天之上。

在当今的人工智能领域,Transformer 模型已成为解决诸多自然语言处理任务的核心。然而,Transformer 模型在处理长文本时常常遇到性能瓶颈。传统的位置编码方法,如绝对位置编码(APE)和相对位置编码(RPE),虽然在许多任务中表现良好,但其固定性限制了其在处理超长文本时的适应性和灵活性。

你敢相信 4B 参数小模型,性能却超越千亿量级的 GPT-3.5 !OpenAI、谷歌、微软、苹果等一众海内外巨头还没做到的事,被一家中国大模型公司抢先了!
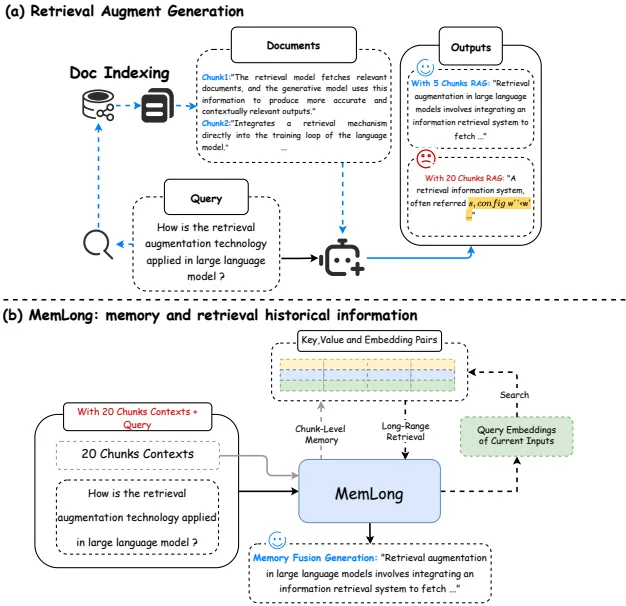
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。
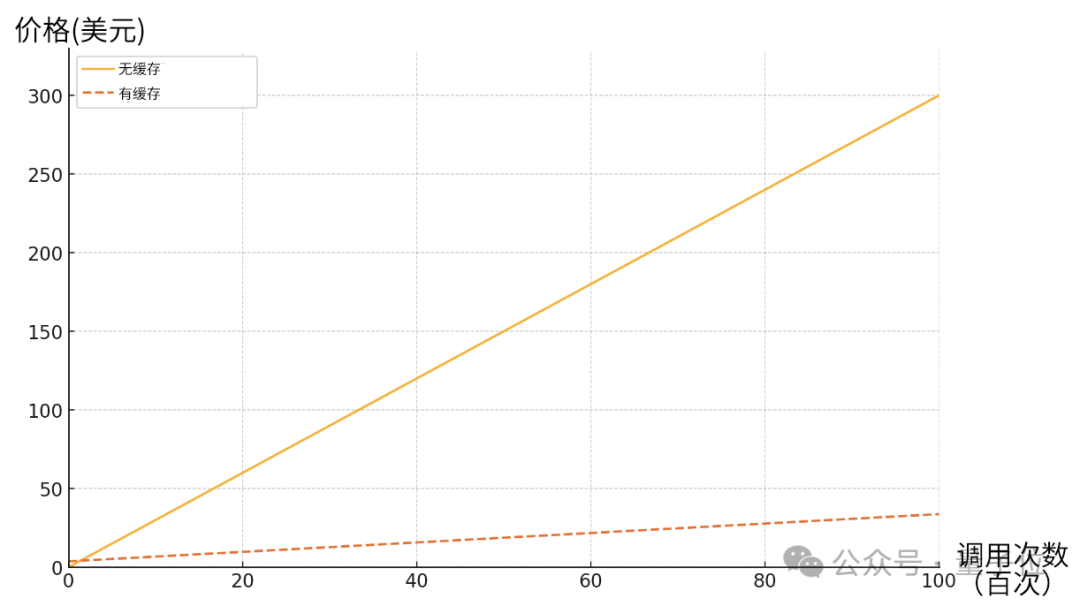
Claude深夜上新重磅功能——API长文本缓存。
最近各家模型发的都挺勤,一会一个 SOTA,一会一个遥遥领先。

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?