# 热门搜索 #
大模型
人工智能
openai
融资
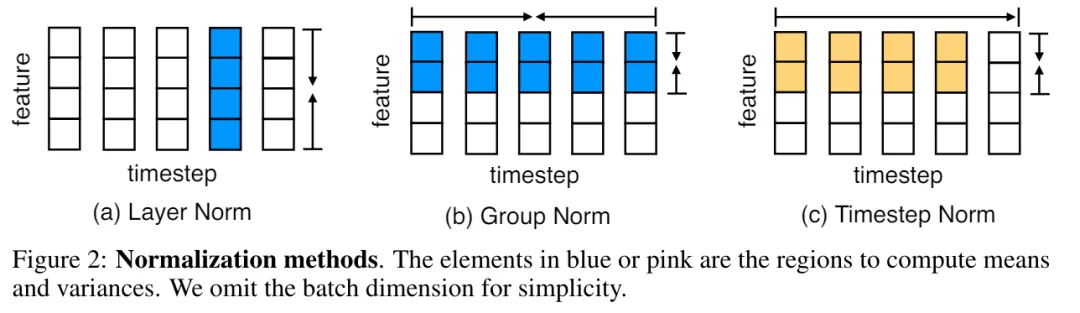
chatGPT
Transformers 的二次复杂度和弱长度外推限制了它们扩展到长序列的能力,虽然存在线性注意力和状态空间模型等次二次解决方案,但从以往的经验来看,它们在预训练效率和下游任务准确性方面表现不佳。
长文本是大语言模型一直在努力的方向。近日,谷歌提出的 Infini-Transformer 引入有效方法,可以将基于 Transformer 的大型语言模型 (LLM) 扩展到无限长输入,而不增加内存和计算需求,吸引了人们的关注。
几乎就在同时,Meta 也提出了一种无限长文本技术。

在 4 月 12 日提交的一篇论文中,来自 Meta、南加州大学、CMU、UCSD 等公司、机构引入了 MEGALODON,一种用于高效序列建模的神经架构,上下文长度不受限制。
MEGALODON 继承了 MEGA(带有门控注意力的指数移动平均)的架构,并进一步引入了多种技术组件来提高其能力和稳定性,包括复数指数移动平均(CEMA)、时间步归一化层、归一化注意力机制和具有两个特征的预归一化(pre-norm)残差配置。
方法介绍
首先,文章简单回顾了 MEGA( Moving Average Equipped Gated Attention )架构中的关键组件,并讨论了 MEGA 中存在的问题。
MEGA 将 EMA( exponential moving average ) 组件嵌入到注意力矩阵的计算中,以纳入跨时间步长维度的归纳偏差。具体而言,多维阻尼 EMA 首先通过扩展矩阵 将输入序列 X 的每个维度单独扩展为 h 维,然后将阻尼 EMA 应用于 h 维隐藏空间。形式如下:
为了降低全注意力机制中的二次复杂度,MEGA 简单地将 (14-16) 中的查询、键和值序列拆分为长度为 c 的块。(17) 中的注意力单独应用于每个块,产生线性复杂度 O (kc^2 ) = O (nc)。
从技术上讲,MEGA 中的 EMA 子层有助于捕获每个 token 附近的本地上下文信息,从而缓解了在超出块边界的上下文中丢失信息的问题。尽管 MEGA 取得了令人深刻的印象,但面临如下问题:
i)由于 MEGA 中 EMA 子层的表达能力有限,具有块级注意力的 MEGA 性能仍然落后于全注意力 MEGA。
ii) 对于不同的任务、数据类型,最终的 MEGA 架构可能存在架构差异,例如,不同的归一化层、归一化模式和注意力函数 f (・) 。
iii) 没有经验证据表明 MEGA 可扩展用于大规模预训练。
CEMA:将多维阻尼 EMA 扩展到复数域
为了解决 MEGA 面临的问题,该研究提出了 MEGALODON。
具体而言,他们创造性地提出了复指数移动平均 CEMA( complex exponential moving average ),将上式(1)改写为如下形式:
并将(2)中的 θ_j 参数化为:
时间步(Timestep)归一化
尽管层归一化与 Transformer 相结合的性能令人印象深刻,但很明显,层归一化不能直接减少沿空间维度(也称为时间步长或序列维度)的内部协变量偏移。
在 MEGALODON 中,该研究通过计算累积均值和方差将组归一化扩展到自回归情况。
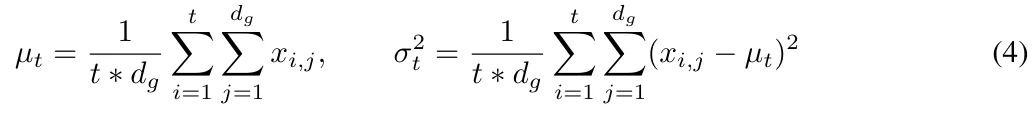
图 2 说明了层归一化和时间步标准化。
MEGALODON 中的归一化注意力
此外,该研究还提出了专门为 MEGA 定制的归一化注意力机制,以提高其稳定性。形式如下:
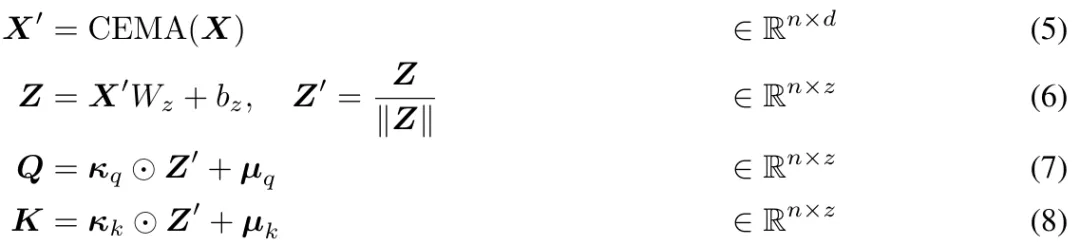
则上式 (17) 中的注意力操作改为:

具有 Two-hop 残差的预范数(Pre-Norm)
通过调查发现,扩大模型大小会造成预归一化不稳定问题。基于 Transformer 块的预归一化可以表示为(如图 3 (b) 所示):

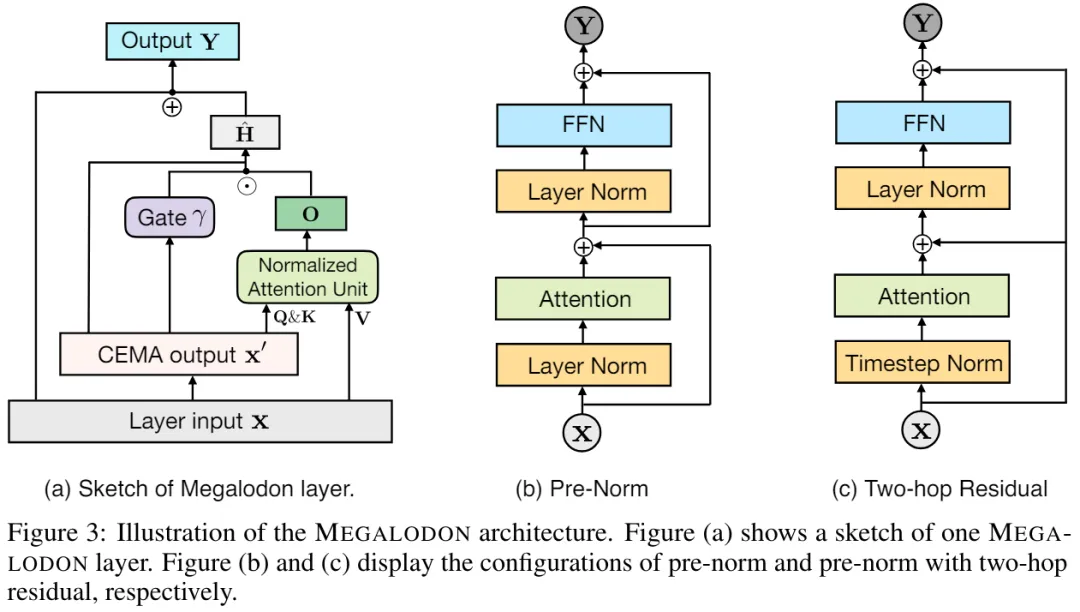
在原始 MEGA 架构中, 将 φ (19) 用于门控残差连接 (21) 以缓解此问题。然而,更新门 φ 引入了更多的模型参数,当模型规模扩大到 70 亿时,不稳定问题仍然存在。MEGALODON 引入了一种名为 pre-norm 的新配置,具有 two-hop 残差,它只是简单地重新排列每个块中的残差连接,如图 3(c)所示:
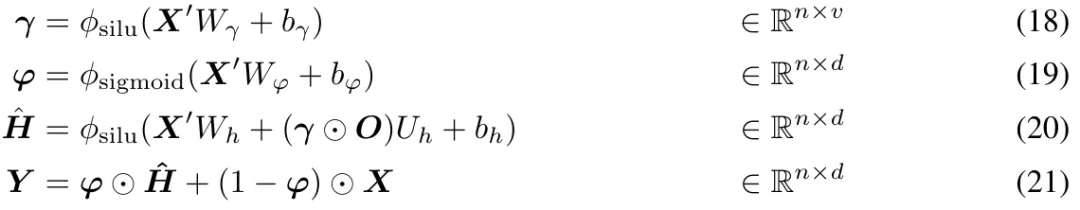
实验
为了评估 MEGALODON 在长上下文序列建模上的可扩展性和效率,本文将 MEGALODON 扩展到 70 亿规模大小。
LLM 预训练
为了提高数据效率,研究者在训练过程中显示了 MEGALODON-7B、LLAMA2-7B 和 LLAMA2-13B 的负对数似然 (NLL),如图 1 所示。
在相同数量的训练 token 下,MEGALODON-7B 获得了比 LLAMA2-7B 明显更好(更低)的 NLL,表现出更好的数据效率。
图 4 说明了分别使用 4K 和 32K 上下文长度的 LLAMA2-7B 和 MEGALODON-7B 在每个设备上的平均 WPS( word/token per second )。对于 LLAMA2 模型,该研究使用 Flash-Attention V2 加速全注意力的计算。在 4K 上下文长度下,由于引入了 CEMA 和时间步归一化,MEGALODON-7B 比 LLAMA2-7B 稍慢(约 6%)。当将上下文长度扩展到 32K 时,MEGALODON-7B 明显比 LLAMA2-7B 快(约 32%),这证明了 MEGALODON 对于长上下文预训练的计算效率。
短上下文评估
表 1 总结了 MEGALODON 和 LLAMA2 在学术基准上的结果,以及其他开源基础模型,包括 MPT、RWKV 、Mamba 、 Mistral 和 Gemma 的比较结果。在相同的 2T token 上进行预训练后,MEGALODON-7B 在所有基准测试中均优于 LLAMA2-7B。在某些任务上,MEGALODON-7B 的性能与 LLAMA2-13B 相当甚至更好。
长上下文评估
图 5 显示了验证数据集在 4K 到 2M 各种上下文长度下的困惑度 (PPL)。可以观察到 PPL 随着上下文长度单调下降,验证了 MEGALODON 在建模极长序列方面的有效性和鲁棒性。
指令微调
表 3 总结了 7B 模型在 MT-Bench 上的性能。与 Vicuna 相比,MEGALODON 在 MT-Bench 上表现出优越的性能,并且与 LLAMA2-Chat 相当,而后者利用 RLHF 进行了进一步的对齐微调。
中等规模基准评估
为了评估 MEGALODON 在图像分类任务上的性能,该研究在 Imagenet-1K 数据集上进行了实验。表 4 报告了验证集上的 Top-1 准确率。MEGALODON 的准确率比 DeiT-B 提高了 1.3%,比 MEGA 提高了 0.8%。
表 5 说明了 MEGALODON 在 PG-19 上的字级困惑度 (PPL),以及与之前最先进的模型,包括 Compressive Transformer 、Perceiver AR、Perceiver AR、块循环 Transformer 和 MEGABYTE 等的对比。MEGALODON 性能明显领先。
文章来自微信公众号“机器之心”,作者:泽南、陈萍




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
