

惊天大瓜!字节实习生往GPU集群注入病毒,导致模型都白训…
惊天大瓜!字节实习生往GPU集群注入病毒,导致模型都白训…就在昨天,微信群里出现了一个消息,迅速攀升至热榜第二名:一名字节实习生攻击GPU集群。
来自主题: AI资讯
11309 点击 2024-10-19 14:52
就在昨天,微信群里出现了一个消息,迅速攀升至热榜第二名:一名字节实习生攻击GPU集群。

「算力」堪称是AI时代最大的痛。在国外,OpenAI因为微软造GPU集群的速度太慢而算力告急。在国内,企业则面临着「模型算力太多元、产业生态太分散」这一难题。不过,最近新诞生的一款「AI神器」,令人眼前一亮。

首个由万卡集群训练出来的万亿参数大模型,被一家央企解锁了。

在电影《天下无贼》中,葛优扮演的黎叔有这样一句经典的台词,「二十一世纪什么最贵?人才!」而随着人工智能行业进入到大模型时代,这一问题的答案已然变成了「算力」。
9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。
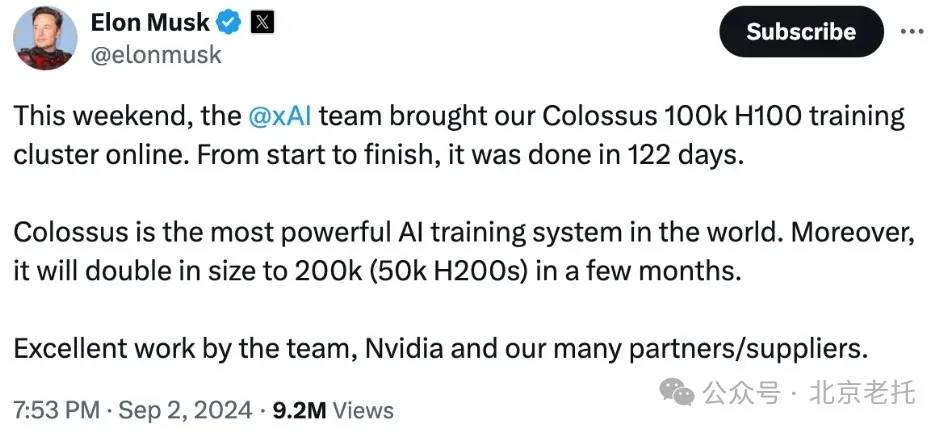
马斯克又搞出了一个超级厉害的东西——人工智能训练集群Colossus!
两天前,马斯克得意自曝:团队仅用122天,就建成了10万张H100的Colossus集群,未来还会扩展到15万张H100和5万张H200。此消息一出,奥特曼都被吓到了:xAI的算力已经超过OpenAI了,还给员工承诺了价值2亿期权,这是要上天?

马斯克xAI建超算集群,以太网助AI云迅猛发展。

人工智能正经历一场由大模型引发的革命。这些拥有数十亿甚至万亿参数的庞然大物,正在重塑我们对 AI 能力的认知,也构筑起充满挑战与机遇的技术迷宫——从计算集群高速互联网络的搭建,到训练过程中模型稳定性和鲁棒性的提升,再到探索更快更优的压缩与加速方法,每一步都是对创新者的考验。
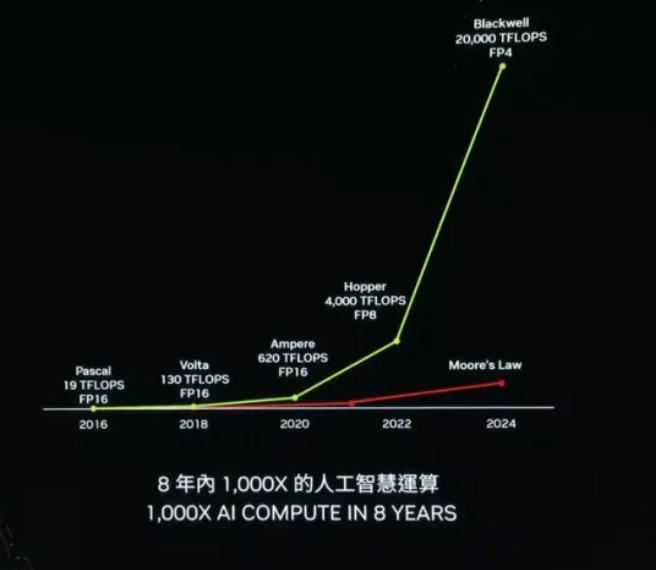
2024年上海的7月是一个沉闷的雨季,但对国产AI 行业来说,却迎来了堪比摇滚乐集会的WAIC(世界人工智能大会)。