xAI再失华人大将:预训练负责人已离职,马斯克又留不住人了
xAI再失华人大将:预训练负责人已离职,马斯克又留不住人了刚刚,xAI再失一名华人大将。就在今天,预训练负责人庄钧堂官宣了自己的离职消息。此前,庄钧堂已经在xAI工作了两年。这期间,他主导了从Grok 2到Grok 5的全系列预训练,同时负责Grok在X和Tesla上的语音模型及xAI企业API模型。
来自主题: AI资讯
8188 点击 2026-05-09 13:17
 搜索
搜索
刚刚,xAI再失一名华人大将。就在今天,预训练负责人庄钧堂官宣了自己的离职消息。此前,庄钧堂已经在xAI工作了两年。这期间,他主导了从Grok 2到Grok 5的全系列预训练,同时负责Grok在X和Tesla上的语音模型及xAI企业API模型。

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining

弹性 AI 预训练已经推进到了下一个前沿!没有意外:来自谷歌。据介绍,他们提出的 Decoupled DiLoCo 是一种革命性的分布式训练技术,能够利用全球各地的异构硬件进行训练,并且即使当硬件发生故障时,系统也不会停止运行!
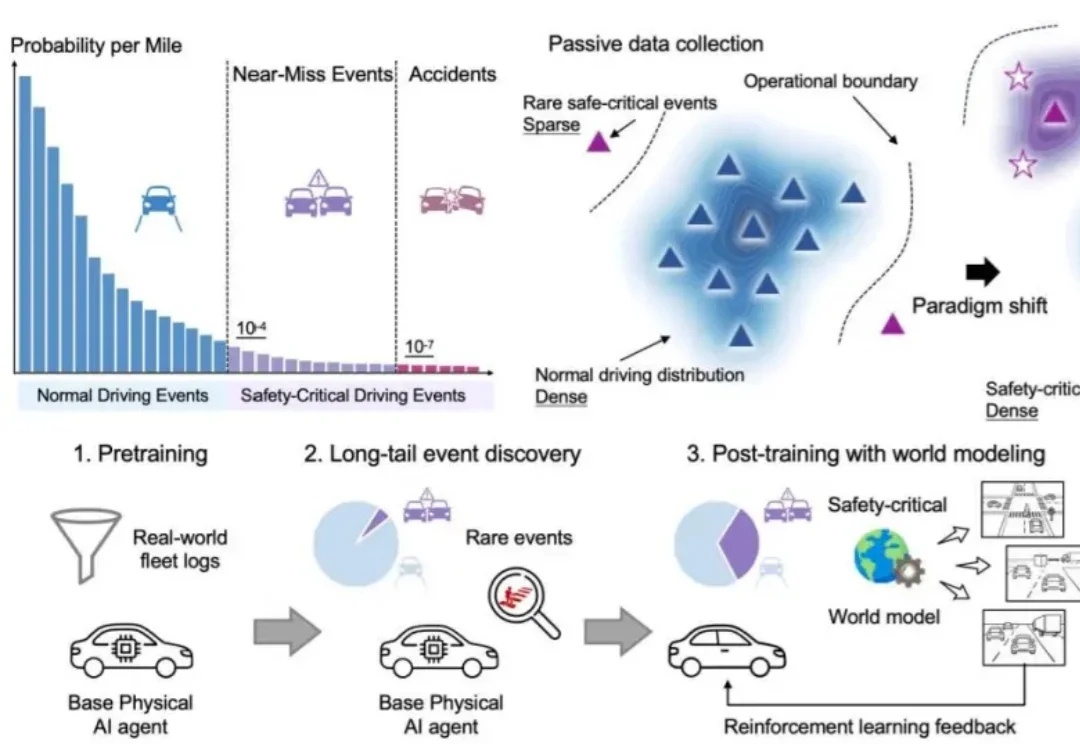
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。

Cursor套壳Kimi这事还没完…… 最新消息,Cursor放出Composer 2技术报告,力证自己还是有在“自研”。(doge) 不是纯套,而是有技术地套、循序渐进地套。用的方法,还是他们一开始就强调的预训练+强化学习。

3 月 20 日,知名 AI 代码编辑器 Cursor 高调发布了所谓的编程模型 Composer 2,结果被网友质疑「套壳」 Kimi K2.5。而从官方口径来看, Composer 2 的性能简直是降维打击:全基准大幅领先前代,首次引入持续预训练,叠加大规模强化学习,能解决需要数百个操作的高难度编程任务。
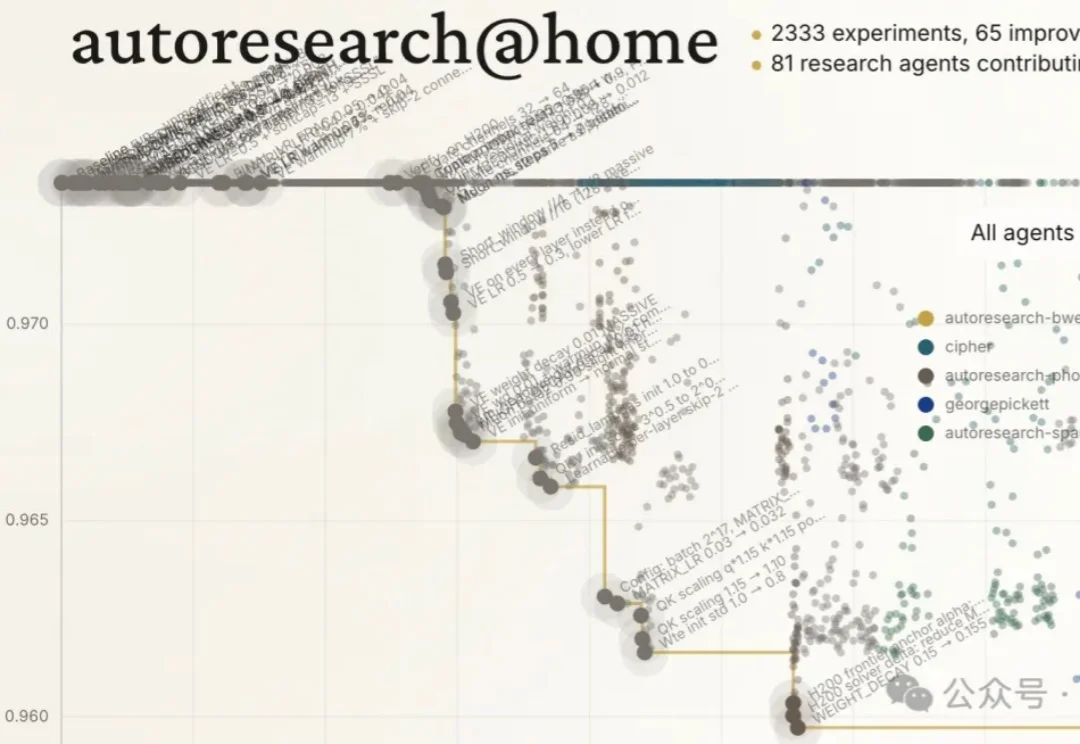
Karpathy让AI通宵干活,自己去蒸桑拿了。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。