
何恺明团队新作GeoPT,全新预训练范式用合成动力学让模型自学真实物理规律
何恺明团队新作GeoPT,全新预训练范式用合成动力学让模型自学真实物理规律GeoPT提出了一种全新的动力学提升预训练范式,通过合成动力学(Synthetic Dynamics)将静态几何“提升”到动态空间,让模型在无标签数据上通过学习粒子轨迹演化来获取物理直觉。
来自主题: AI技术研报
9405 点击 2026-02-28 14:58
 搜索
搜索
GeoPT提出了一种全新的动力学提升预训练范式,通过合成动力学(Synthetic Dynamics)将静态几何“提升”到动态空间,让模型在无标签数据上通过学习粒子轨迹演化来获取物理直觉。
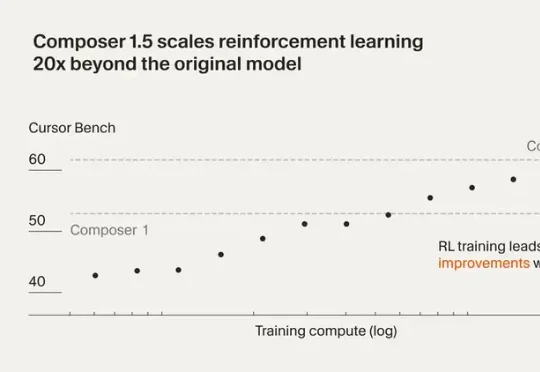
最近Cursor 发布了 Composer 1.5。这一版把强化学习规模扩大了 20 倍,后训练计算量甚至超过了基座模型的预训练投入。还加了 thinking tokens 和自我摘要机制,让模型能在复杂编程任务里做更深度的推理。
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。

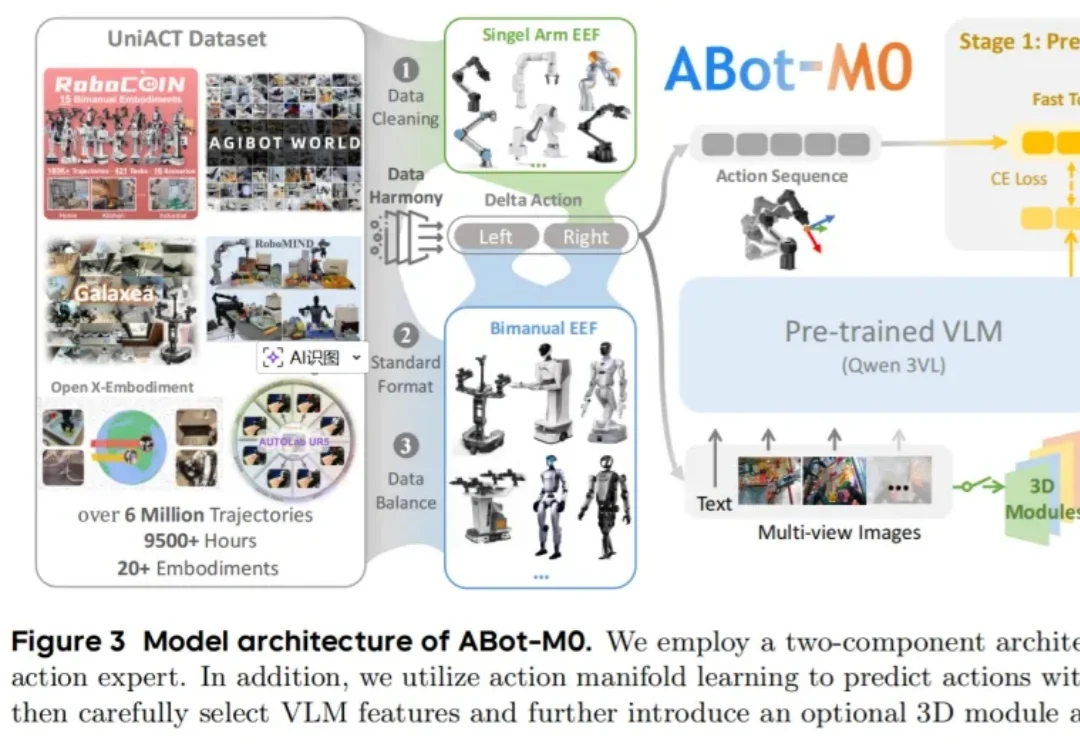
目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?

又一位大佬准备对现有 AI 技术范式开刀了。
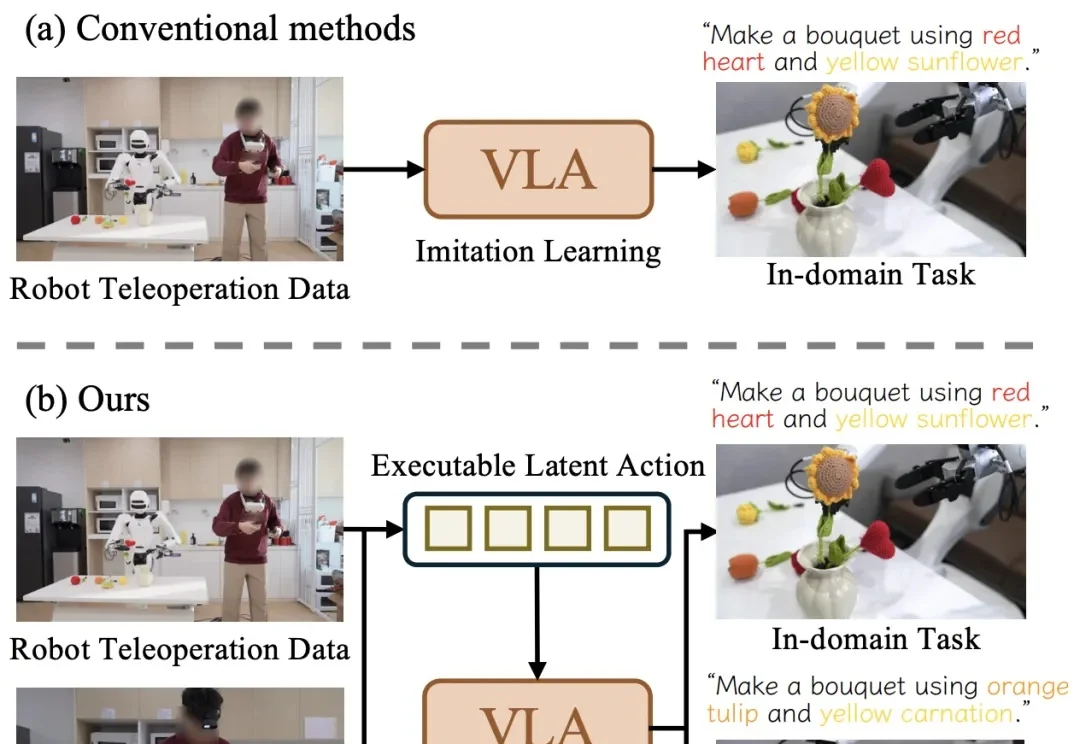
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。
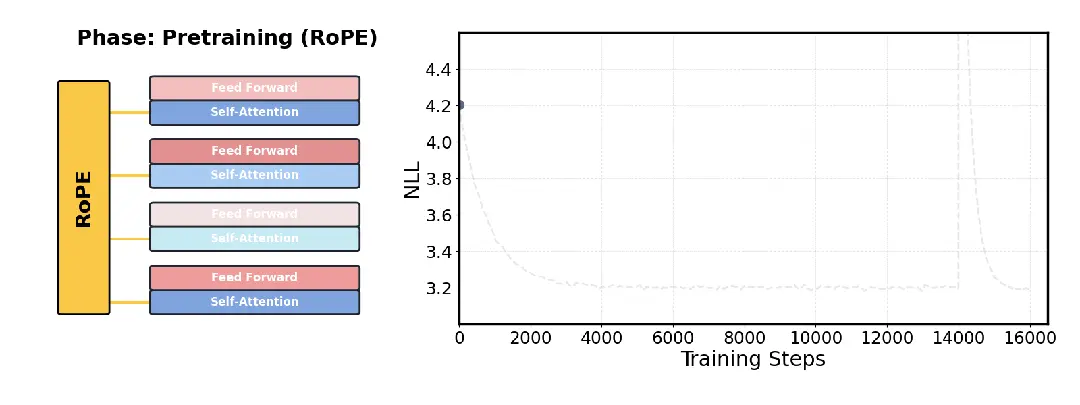
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

Anthropic联创又出来说话了!

MIT天才博士一毕业,火速加盟OpenAI前CTO初创!最近,肖光烜(Guangxuan Xiao)在社交媒体官宣,刚刚完成了MIT博士学位。下一步,他将加入Thinking Machines,专注于大模型预训练的工作。