


他,雇AI卖房,多赚61万
他,雇AI卖房,多赚61万狂省24万佣金,买方中介还夸他专业。
来自主题:
AI资讯
8780 点击 2026-06-05 10:25
 搜索
搜索
狂省24万佣金,买方中介还夸他专业。

今天这篇内容可能会比较特殊,是一篇Anthropic凌晨发的全新文章。 名字叫《When AI builds itself》。 翻译过来叫,《当人工智能开始自我构建》。 他们甚至还为这篇文章,配了一个超级精美的、非常能体现Agent自我构建这个理念的动画,由此可见Anthropic对这篇内容的重视程度可见一斑。

猹友们,不知道你们有没有注意到,最近观猹首页多了入口。
官宣全球顶尖医院,微软要为AI医疗定制一款大模型!
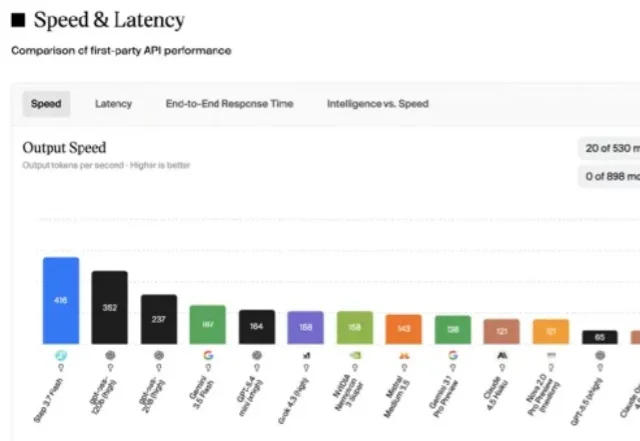
OpenRouter Trending榜单冷不丁窜出一匹国产黑马,热度暴涨稳居全球第二。

2026 AI赛道最火的概念——物理AI!
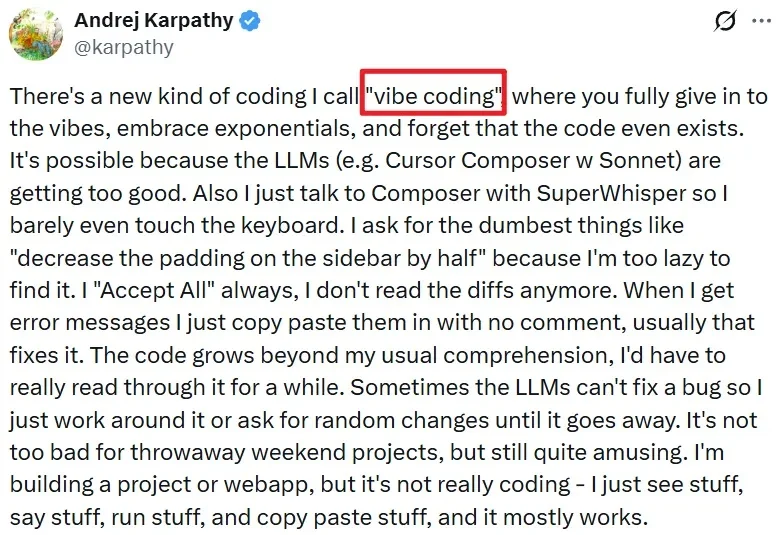
这是 Vibe Coding 的时代,这是 Vibe Working 的时代,这也是语音输入的时代……
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”

长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

在ChatGPT拥有10亿用户后,AI问答这一定位,显然已经难以撑起其下一阶段的增长。另一方面,Codex每周活跃用户已超500万。很多人囿于名字,以为这是Coding产品。。。。限制了其在编程圈外的增长。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

靠程序员发家,如今却因为AI要裁掉程序员。

8000元预算推7元玩具?AI购物或许有用,但不多。

我做产业研究这么多年,第一次被一组数字震住,是在今年年初。

Notion 最近发了一篇工程文章,复盘过去两年他们怎么做向量搜索基础设施。
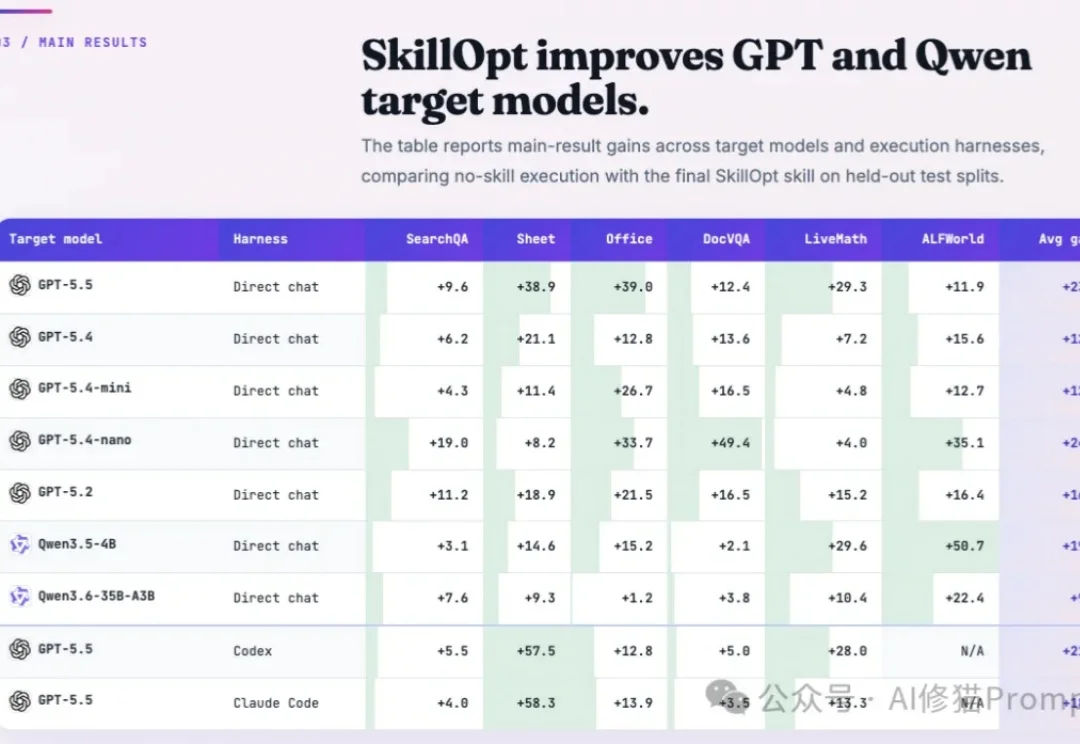
训练大模型时,工程师绝对不会指望网络做一次前向传播就能收敛。它需要数据喂养、Batch切分、学习率控制、验证集筛选以及优化器状态的迭代试错。

其实大概半年前,我就有这个需求了。那阵子我也注意到,阿里、字节这些平台都各自出了提示词优化器。但它们都得专门跑到对应的网站上去用,对我来说不够顺手。所以这回干脆借着深度复盘了 Anthropic 的 Prompt 讲座,用 Codex vibe coding 了一个全局提示词优化器。

Paperboy 正在尝试找到一种更自然、更连续、更可协作的 Agent 界面与记忆结构——Agent 应该通过观察你用电脑来自己学习,用 IM 而不是 session 来组织对话,主动找你,而不是等你 prompt。
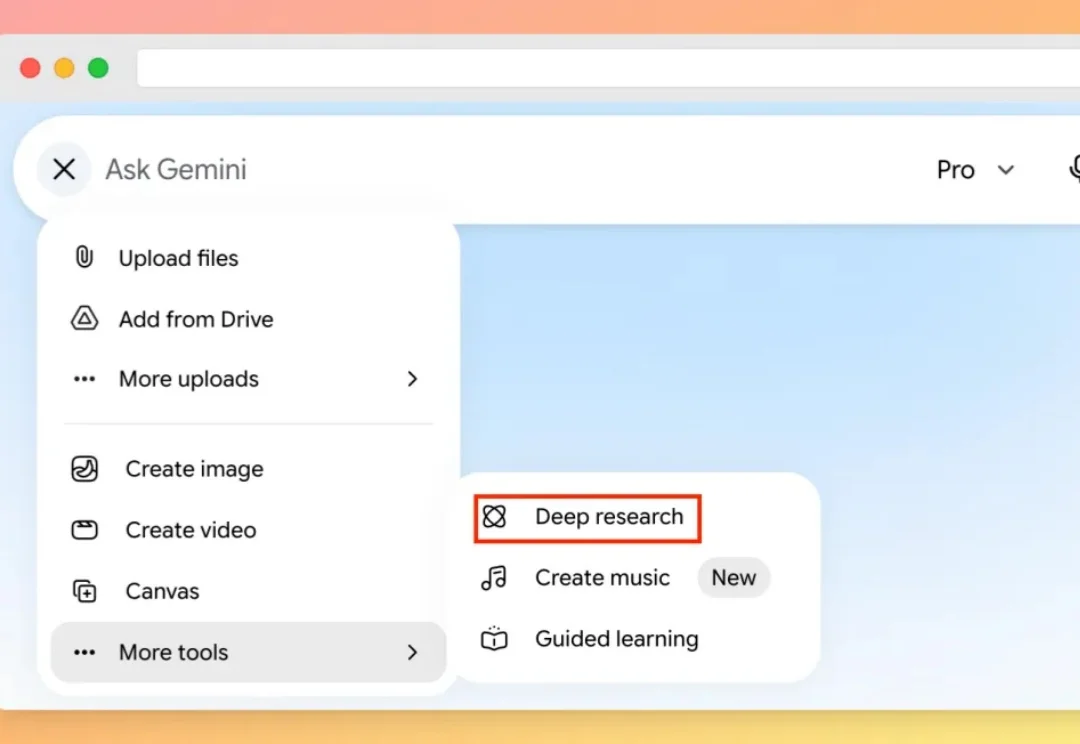
AI 工具推荐现在是门显学。

刚刚,谷歌扔出Gemma 4 12B大杀器!16G轻薄本就能全离线流畅跑通,性能直逼26B巨兽,全体开发者惊呼太震撼了,平民级本地AI封神之作降临。硬核实测速来看!

世界模型火,火到都有点乱了。

Claude Mythos就用6.1×10²⁷ FLOPs提前叩响了奇点的大门。

都以为让AI查数据省事,结果它答得漂亮你却不敢信。Anthropic最近说这事有解了,靠的是一套和代码无关的「笨功夫」。
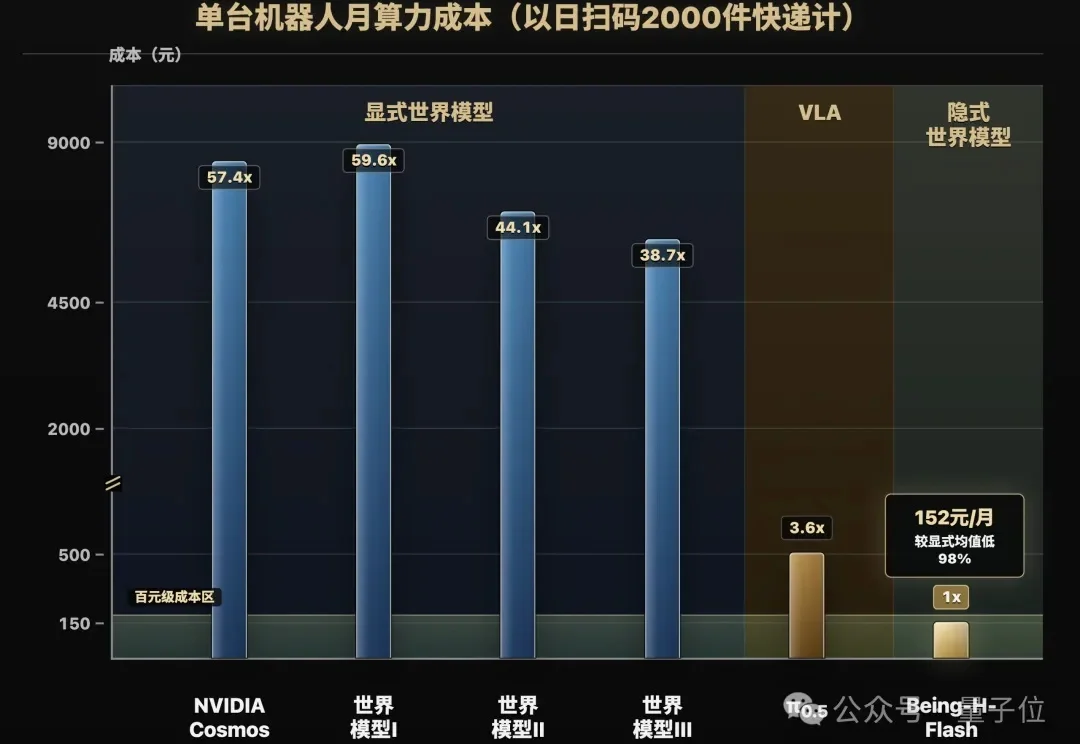
真没想到啊!物理AI的账单,有一天竟然能和大模型一个价。
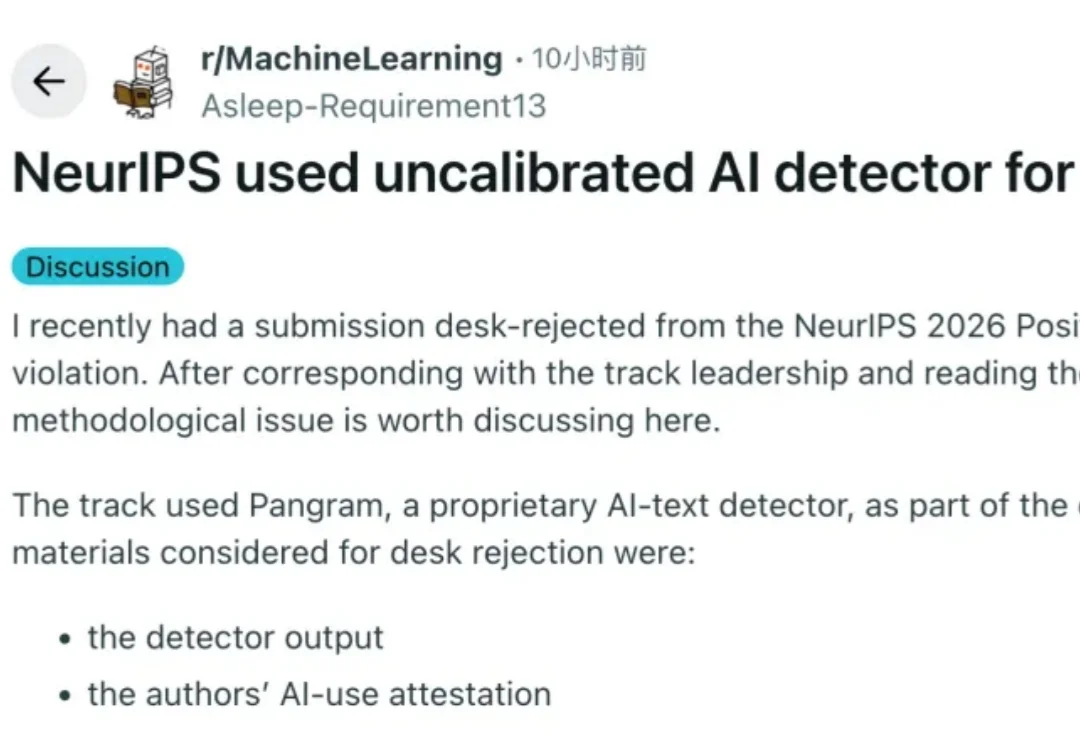
NeurIPS 2026 正在用 AI 检测器来判定「论文投稿是否使用 AI」,并作为拒稿的重要依据。

6月3日,千问APP宣布向第三方Agent和Skill全面开放。未来,企业可以在千问中运营自己的品牌Agent。目前,瑞幸、肯德基、蜜雪冰城、东方航空等首批企业已启动测试,并将陆续上线。

马卡龙又出来炒作自己新一轮融资了,但我感到十分难过😭
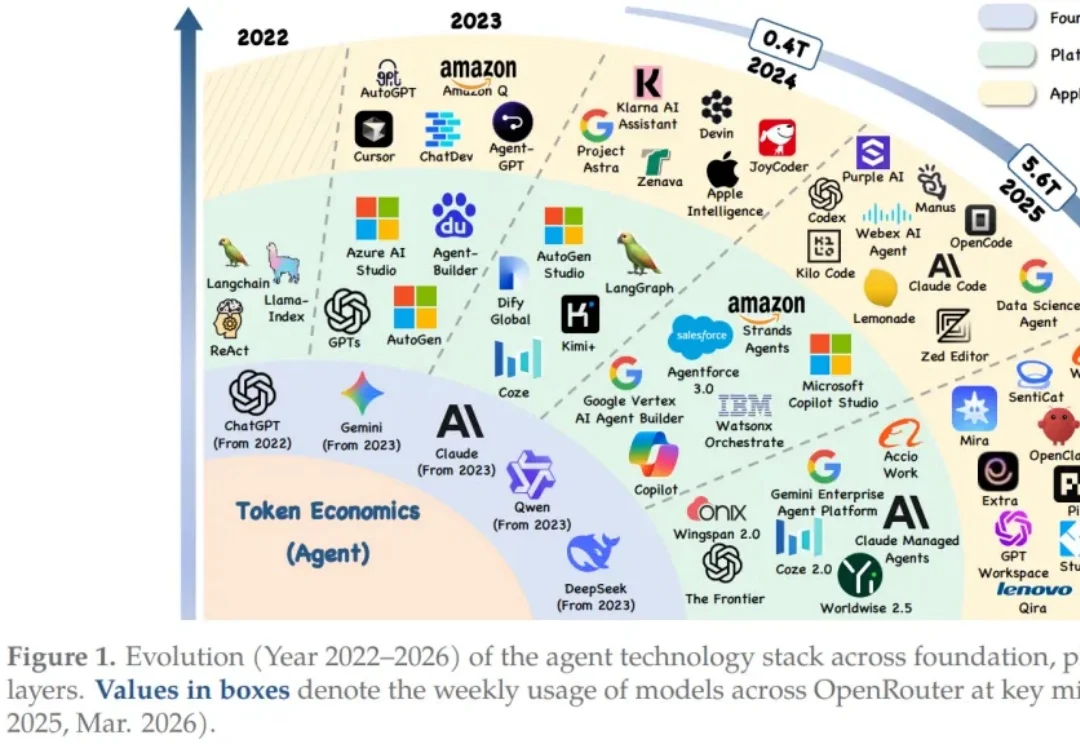
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。

