# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
相信很多用户已经见识过或至少听说过 Deep Research 的强大能力。
今天凌晨,OpenAI 宣布 Deep Research 已经面向所有 ChatGPT Plus、Team、Edu 和 Enterprise 用户推出(刚发布时仅有 Pro 用户可用),同时,OpenAI 还发布了 Deep Research 系统卡。
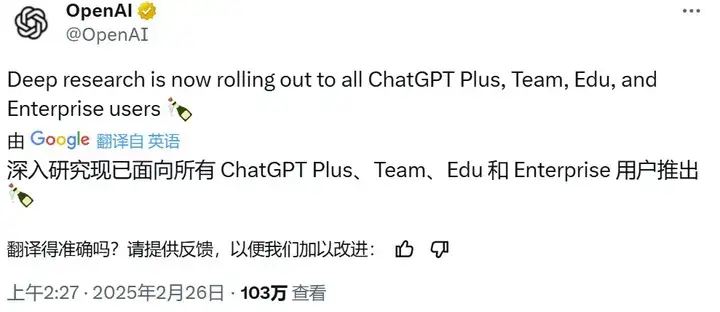
此外,OpenAI 研究科学家 Noam Brown 还在 𝕏 上透露:Deep Research 使用的基础模型是 o3 正式版,而非 o3-mini。
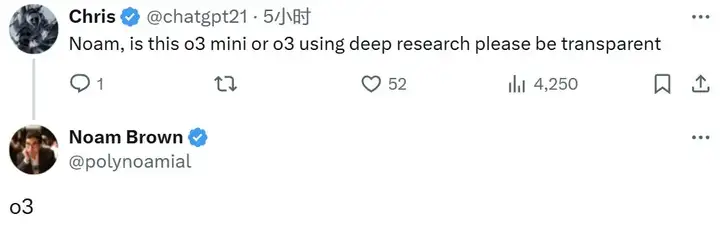
Deep Research 是 OpenAI 本月初推出的强大智能体,其能使用推理来综合大量在线信息并为用户完成多步骤研究任务,从而助力用户进行深入、复杂的信息查询与分析。参阅机器之心报道《刚刚,OpenAI 上线 Deep Research!人类终极考试远超 DeepSeek R1》。
在发布之后的这二十几天里,OpenAI 还对 Deep Research 进行了一些升级:
OpenAI 这次发布的 Deep Research 系统卡报告介绍了发布 Deep Research 之前开展的安全工作,包括外部红队、根据准备度框架进行的风险评估,以及 OpenAI 为解决关键风险领域而采取的缓解措施。这里我们简单整理了这份报告的主要内容。

地址:https://cdn.openai.com/deep-research-system-card.pdf
Deep Research 是一种新的智能体能力,可针对复杂任务在互联网上进行多步骤研究。Deep Research 模型基于为网页浏览进行了优化的 OpenAI o3 早期版本。Deep Research 利用推理来搜索、解读和分析互联网上的大量文本、图像和 PDF,并根据遇到的信息做出必要的调整。它还可以读取用户提供的文件,并通过编写和执行 Python 代码来分析数据。
「我们相信 Deep Research 可以帮助人们应对多种多样的情形。」OpenAI 表示,「在发布 Deep Research 并将其提供给我们的 Pro 用户之前,我们进行了严格的安全测试、准备度评估和治理审查。我们还进行了额外的安全测试,以更好地了解与 Deep Research 浏览网页的能力相关的增量风险,并增加了新的缓解措施。新工作的关键领域包括加强对在线发布的个人信息的隐私保护,以及训练模型以抵御在搜索互联网时可能遇到的恶意指令。」
OpenAI 还提到,对 Deep Research 的测试也揭示了进一步改进测试方法的机会。在扩大 Deep Research 的发布范围之前,他们还将花时间对选定的风险进行进一步的人工检测和自动化测试。
本系统卡包含 OpenAI 如何构建 Deep Research、了解其能力和风险以及在发布前提高其安全性的更多详细信息。
Deep Research 的训练数据是专门为研究用例创建的新浏览数据集。
该模型学习了核心的浏览功能(搜索、单击、滚动、解读文件)、如何在沙盒环境中使用 Python 工具(用于执行计算、进行数据分析和绘制图表),以及如何通过对这些浏览任务进行强化学习训练来推理和综合大量网站以查找特定信息或撰写综合报告。
其训练数据集包含一系列任务:从具有 ground truth 答案的客观自动评分任务,到带有评分标准的更开放的任务。
在训练期间,评分过程使用的评分器是一个思维链模型,其会根据 ground truth 答案或评分标准给出模型响应的分数。
该模型的训练还使用了 OpenAI o1 训练用过的现有安全数据集,以及为 Deep Research 创建的一些新的、特定于浏览的安全数据集。
外部红队方法
OpenAI 与外部红队成员团队合作,评估了与 Deep Research 能力相关的关键风险。
外部红队专注的风险领域包括个人信息和隐私、不允许的内容、受监管的建议、危险建议和风险建议。OpenAI 还要求红队成员测试更通用的方法来规避模型的安全措施,包括提示词注入和越狱。
红队成员能够通过有针对性的越狱和对抗策略(例如角色扮演、委婉表达、使用黑客语言、莫尔斯电码和故意拼写错误等输入混淆)来规避他们测试的类别的一些拒绝行为,并且根据这些数据构建的评估将 Deep Research 的性能与之前部署的模型进行比较。
评估方法
Deep Research 扩展了推理模型的能力,使模型能够收集和推理来自各种来源的信息。Deep Research 可以综合知识并通过引用提出新的见解。为了评估这些能力,需要调整已有的一些评估方法,以解释更长、更微妙的答案 —— 而这些答案往往更难以大规模评判。
OpenAI 使用其标准的不允许内容和安全评估对 Deep Research 模型进行了评估。他们还为个人信息和隐私以及不允许的内容等领域开发了新的评估。最后,对于准备度评估,他们使用了自定义支架来引出模型的相关能力。
ChatGPT 中的 Deep Research 还使用了另一个自定义提示的 OpenAI o3-mini 模型来总结思维链。以类似的方法,OpenAI 也根据其标准的不允许内容和安全评估对总结器模型进行了评估。
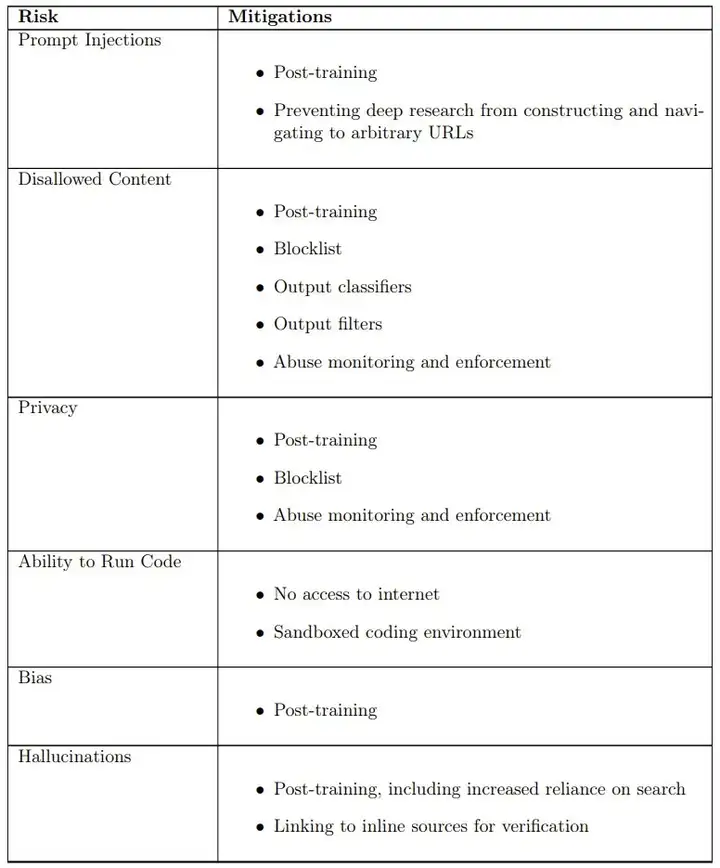
观察到的安全挑战、评估和缓解措施
下表给出了风险和相应的缓解措施;每个风险的具体评估和结果请参阅原报告。
准备度框架评估
准备度框架是一个动态文档,其中描述了 OpenAI 跟踪、评估、预测和防范来自前沿模型的灾难性风险的方式。
该评估目前涵盖四个风险类别:网络安全、CBRN(化学、生物、放射、核)、说服和模型自主性。
只有缓解后(post-mitigation)得分为「中」或以下的模型才能部署,只有缓解后得分为「高」或以下的模型才能进一步开发。OpenAI 根据准备度框架对 Deep Research 进行了评估。
准备度框架详情请访问:https://cdn.openai.com/openai-preparedness-framework-beta.pdf
下面更具体地看看对 Deep Research 的准备度评估。Deep Research 基于针对网页浏览进行了优化的 OpenAI o3 早期版本。为了更好地衡量和引出 Deep Research 的能力,OpenAI 对以下模型进行了评估:
对于 Deep Research 模型,OpenAI 测试了各种设置以评估最大能力引出(例如,有浏览与无浏览)。他们还根据需要修改了支架,以最好地衡量多项选择题、长答案和智能体能力。
为了帮助评估每个跟踪风险类别中的风险级别(低、中、高、严重),准备团队使用「indicator」将实验评估结果映射到潜在风险级别。这些 indicator 评估和隐含风险水平经过安全咨询小组(Safety Advisory Group)审查,该小组确定了每个类别的风险水平。当达到或看起来即将达到 indicator 阈值时,安全咨询小组会进一步分析数据,然后确定是否已达到风险水平。
OpenAI 表示模型训练和开发的整个过程中都进行了评估,包括模型启动前的最后一次扫描。为了最好地引出给定类别中的能力,他们测试了各种方法,包括在相关情况下的自定义支架和提示词。
OpenAI 也指出,生产中使用的模型的确切性能数值可能会因最终参数、系统提示词和其他因素而异。
OpenAI 使用了标准 bootstrap 程序计算 pass@1 的 95% 置信区间,该程序会对每个问题的模型尝试进行重新采样以近似其指标的分布。
默认情况下,这里将数据集视为固定的,并且仅重新采样尝试。虽然这种方法已被广泛使用,但它可能会低估非常小的数据集的不确定性,因为它只捕获抽样方差而不是所有问题级方差。换句话说,该方法会考虑模型在多次尝试中对同一问题的表现的随机性(抽样方差),但不考虑问题难度或通过率的变化(问题级方差)。这可能导致置信区间过紧,尤其是当问题的通过率在几次尝试中接近 0% 或 100% 时。OpenAI 也报告了这些置信区间以反映评估结果的内在变化。
在审查了准备度情况评估的结果后,安全咨询小组将 Deep Research 模型评级为总体中等风险(overall medium risk)—— 包括网络安全、说服、CBRN、模型自主性都是中等风险。
这是模型首次在网络安全方面被评为中等风险。
下面展示了 Deep Research 与其它对比模型在 SWE-Lancer Diamond 上的结果。请注意其中上图是 pass@1 结果,也就是说在测试的时候,每个模型在每个问题上只有一次尝试的机会。
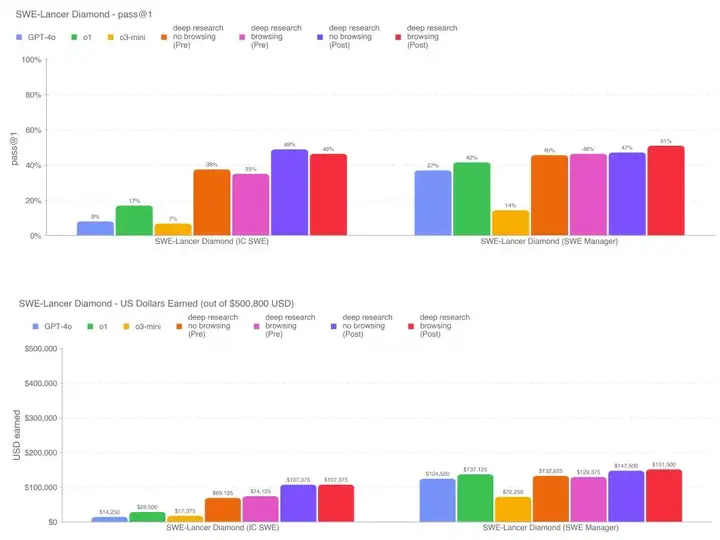
整体来看,各个阶段的 Deep Research 的表现都非常好。其中,缓解后的 Deep Research 模型在 SWE-Lancer 上表现最佳,解决了大约 46-49% 的 IC SWE 任务和 47-51% 的 SWE Manager 任务。
更多评估细节和结果请访问原报告。
文章来自于“机器之心”,作者“Panda”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
