# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是袋鼠帝
前几天收到一个客朋友的咨询:“有没有什么爬虫软件推荐?”
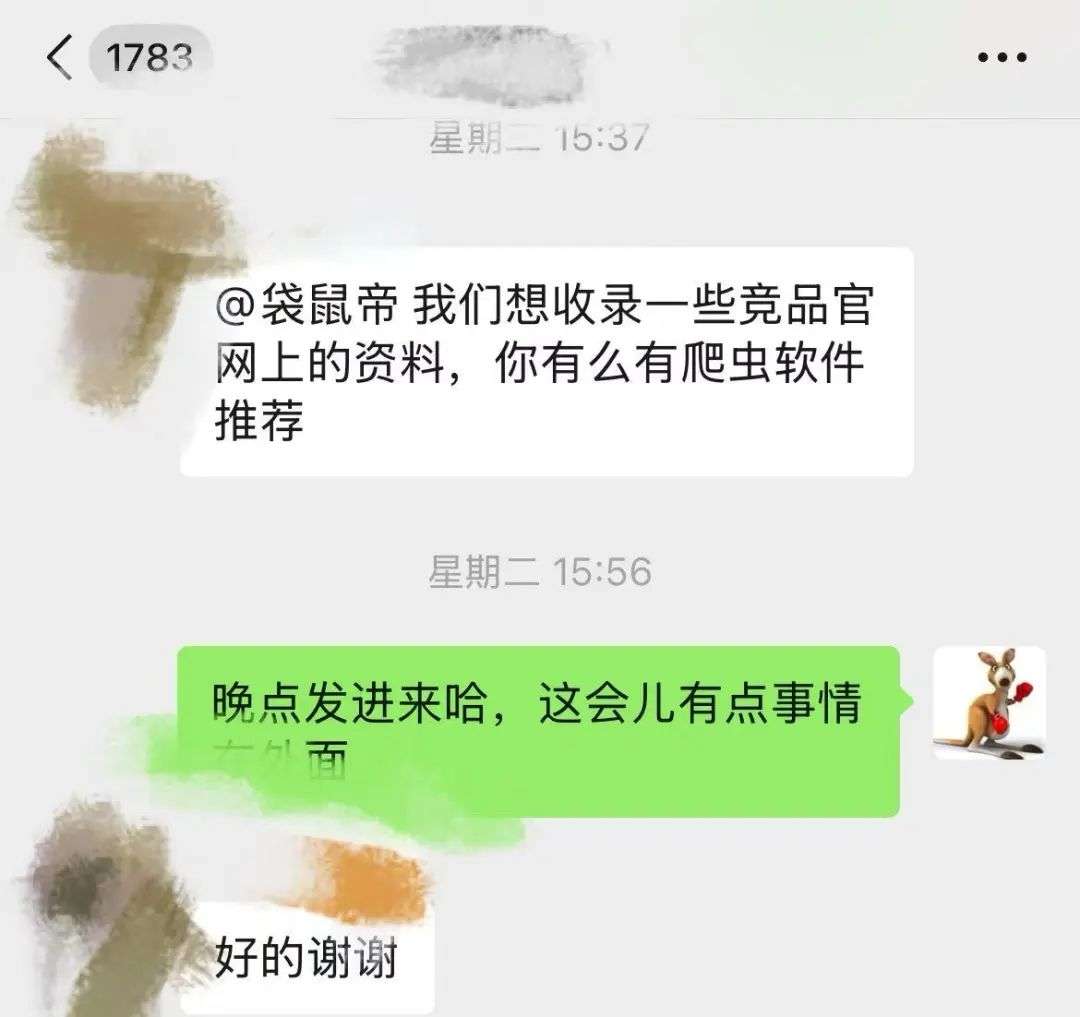
他们想收集一下竞品官网的资料,做一下数据分析
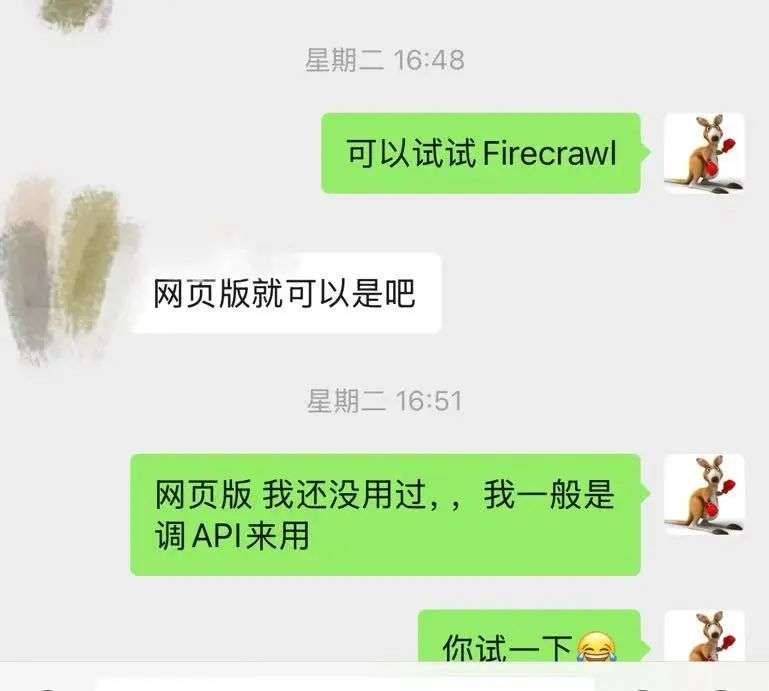
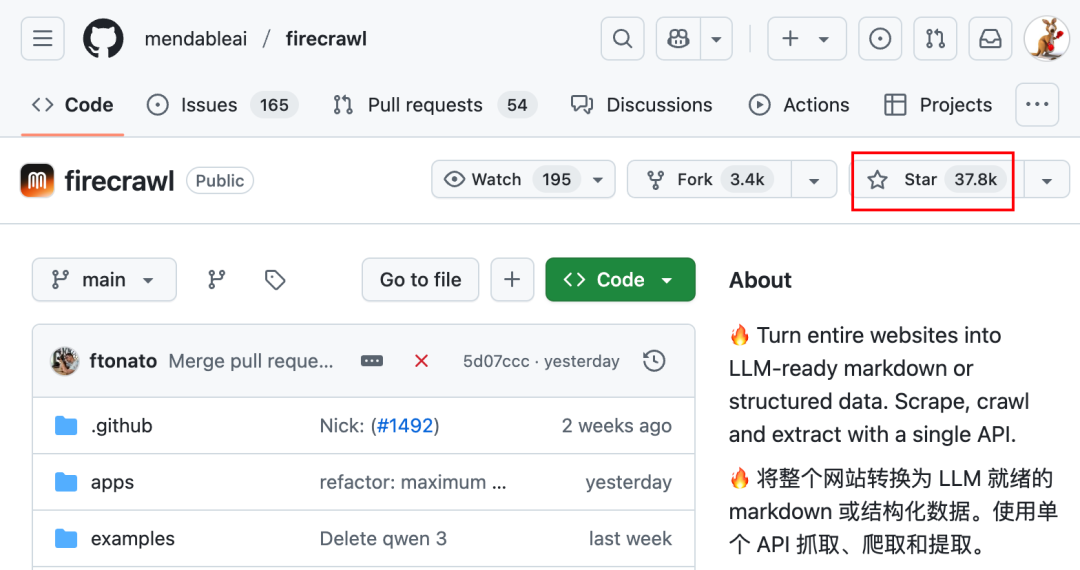
我直接推荐了一个已经在Github斩获37K Star的开源爬虫工具(也有在线的云版本):Firecrawl
https://github.com/mendableai/firecrawl
需要爬取的网页貌似还不少...
Firecrawl支持本地部署免费使用
或者使用在线版:
https://www.firecrawl.dev/
在线版有500个页面的免费次数,用完后需要付费使用。
但是Firecrewl的网页端只支持一次爬一个链接,需要手动执行
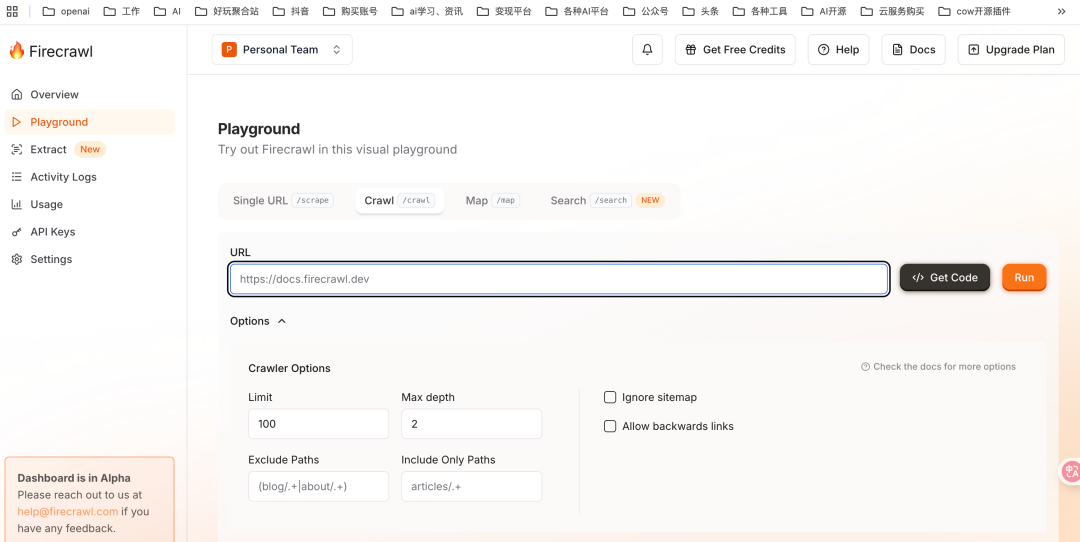
如果需要抓取的站点太多的话,还是非常非常耗时的。
要想批量处理,还得使用API来搞
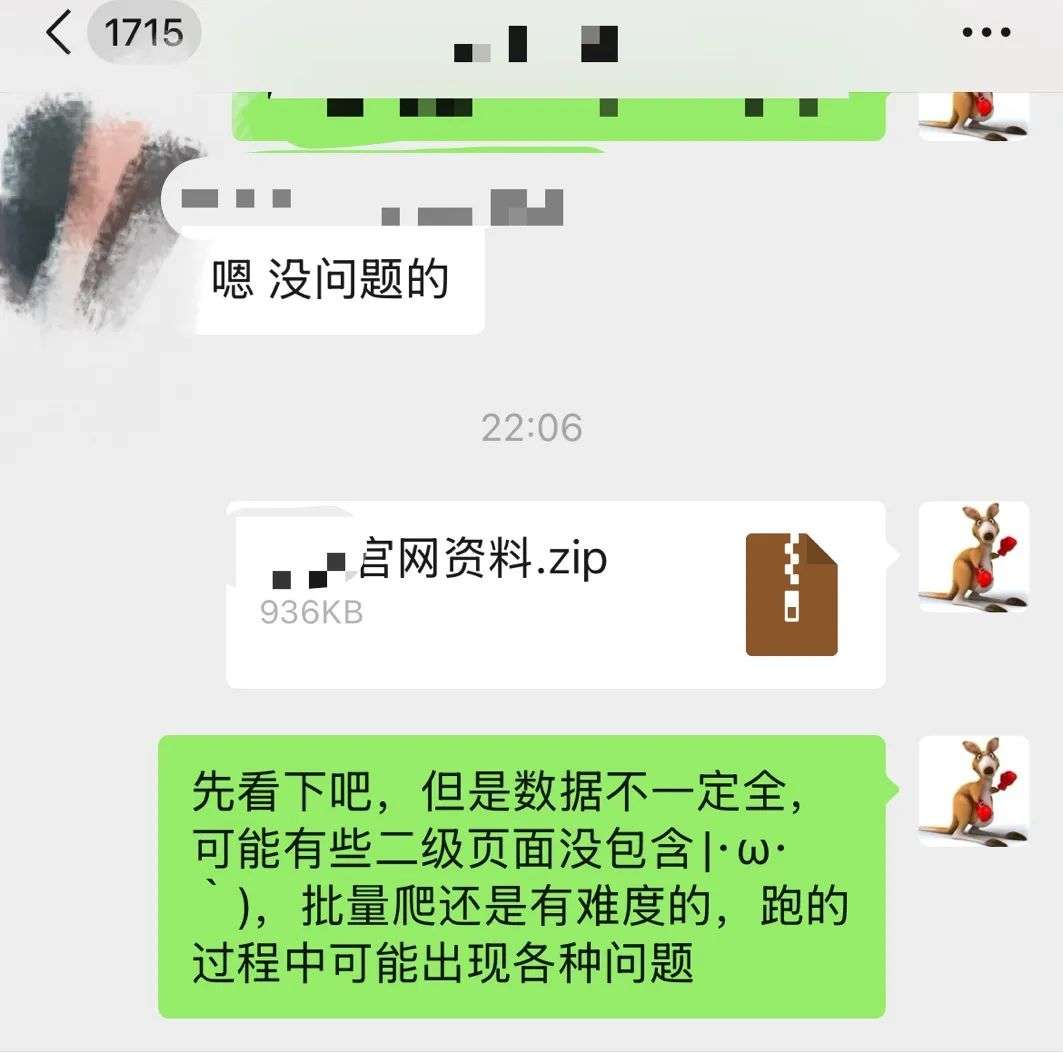
于是我答应帮忙处理了(下图)。
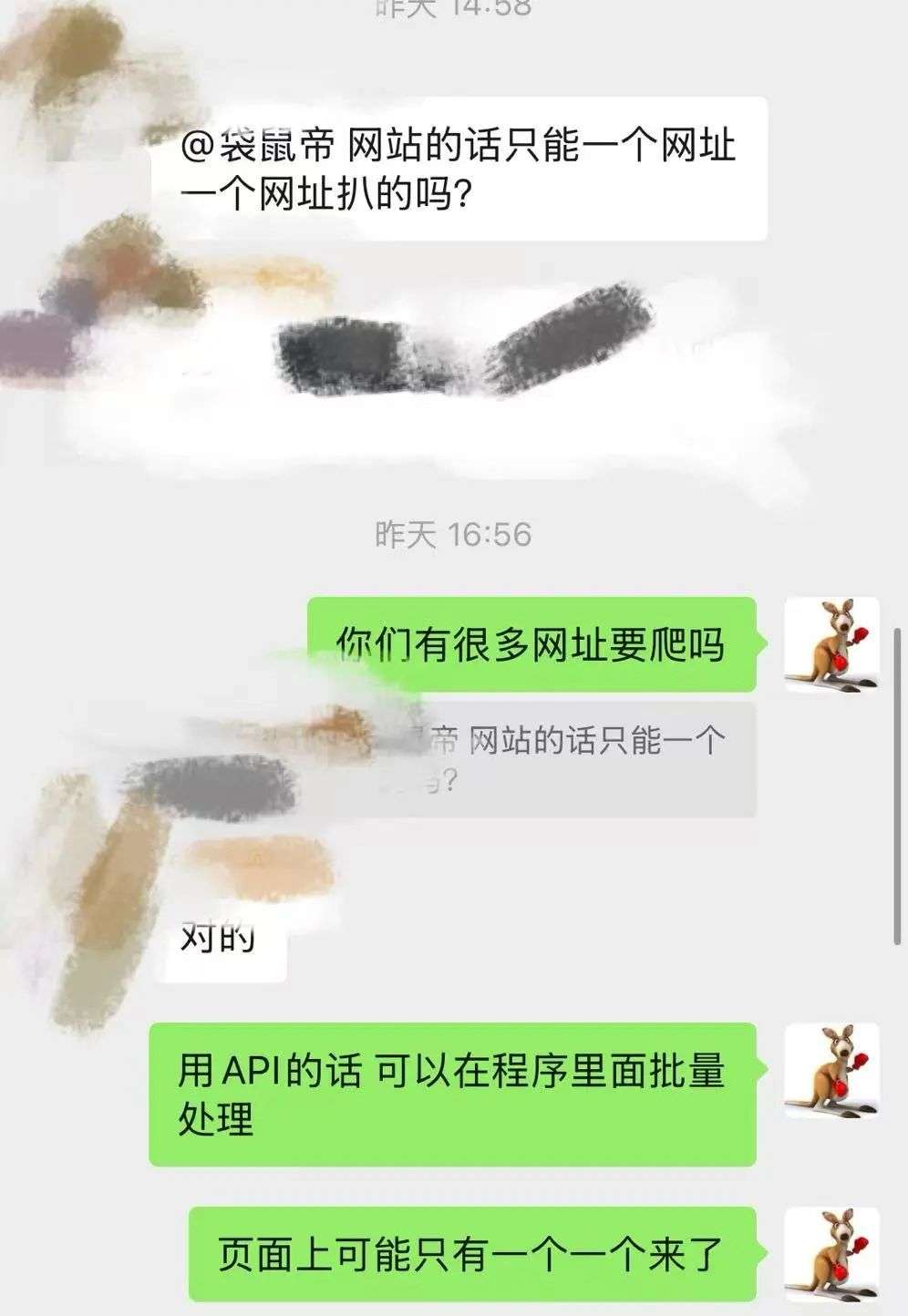
第二天一早就收到了朋友整理的竞品官网网址。
打开一看,卧槽,还真不少,有200个站点需要爬取
正好我前几天享一篇MCP文章里面其实就包含了Firecrawl MCP。
评论区大家也呼吁我出一篇Firecrawl的文章



buff叠满了...
这篇是天选之文
我本来以为这是一次很顺利,迅速就能搞定的事情。
结果,是我天真了...
先把时间拉回昨天
我当时信心满满的打开了Firecrawl的Github页面
https://github.com/mendableai/firecrawl
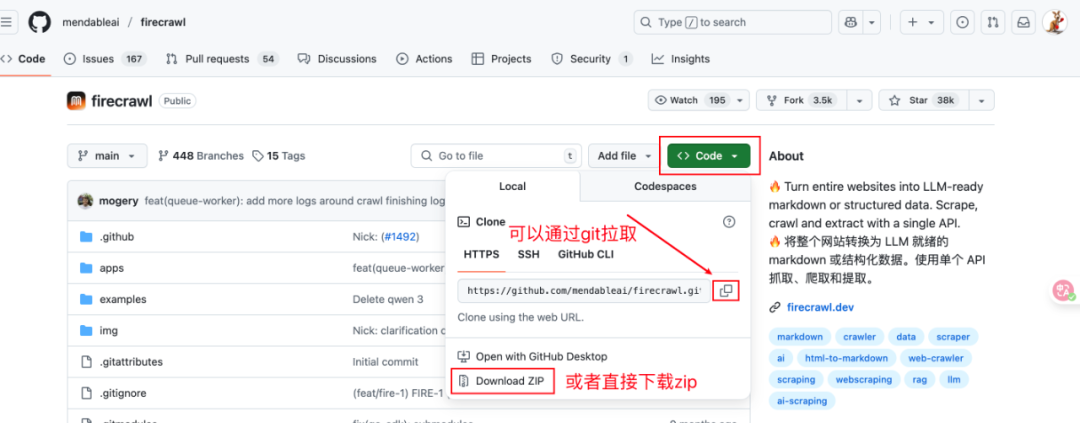
通过git clone把Firecrawl项目拉取到了本地(也可下载zip)。
结果跑起来之后会报下面这个错误,我以为是我的问题,比如请求参数错误,或者请求地址不对?
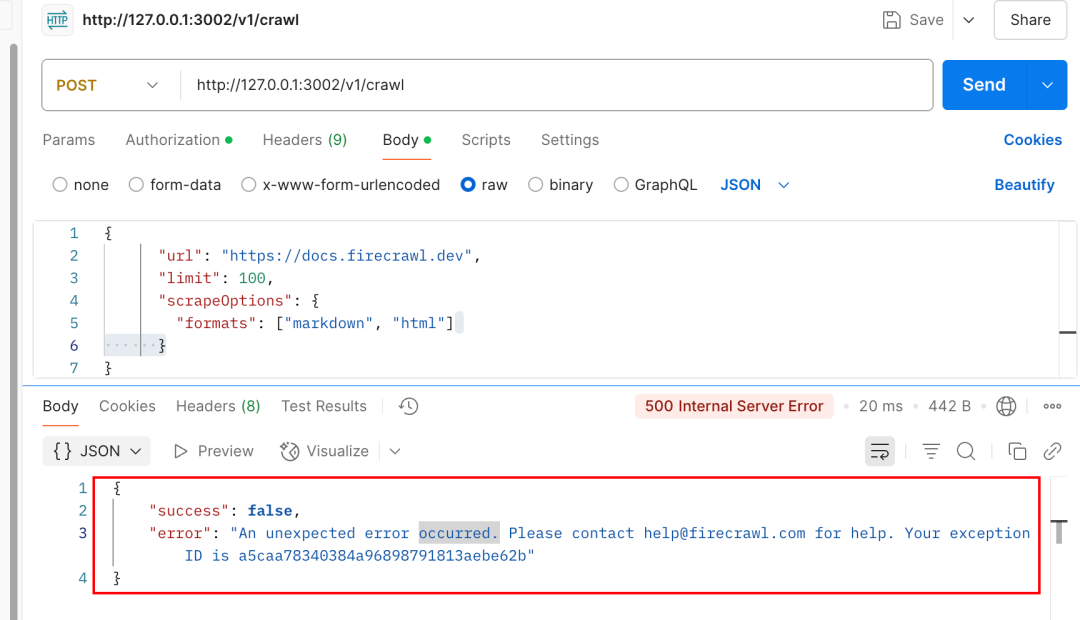
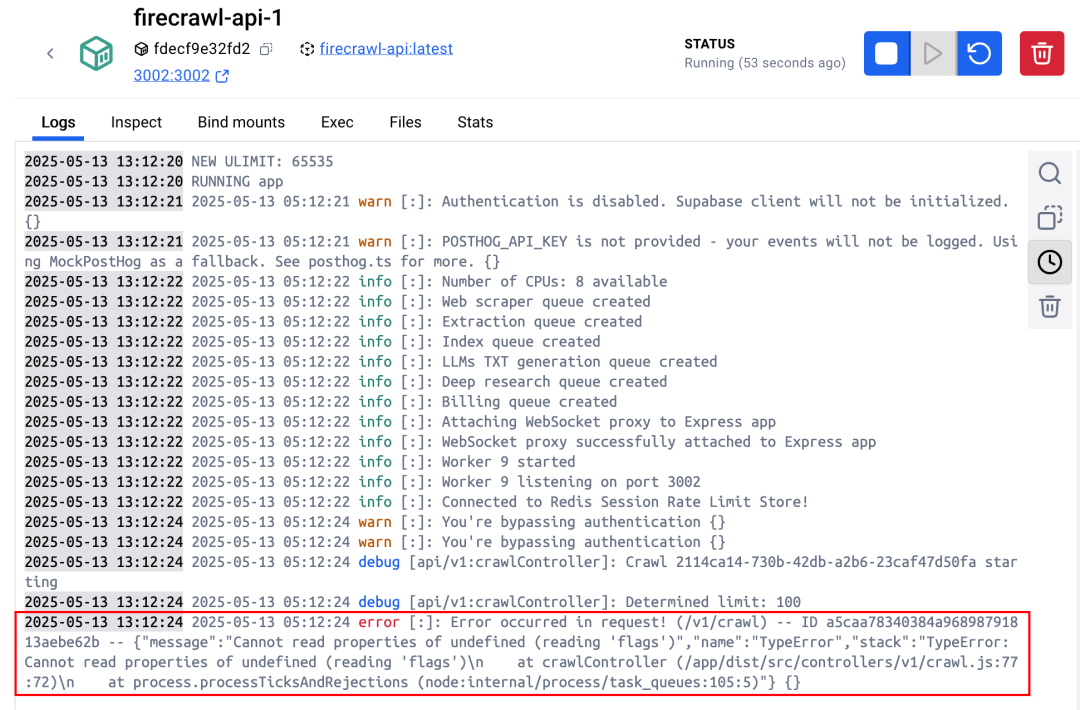
搞了半天,直到我看到某人昨天在Github刚提的issues(问题),和我遇到的问题一样,这特喵是个bug...我只能无奈的写下一个me too
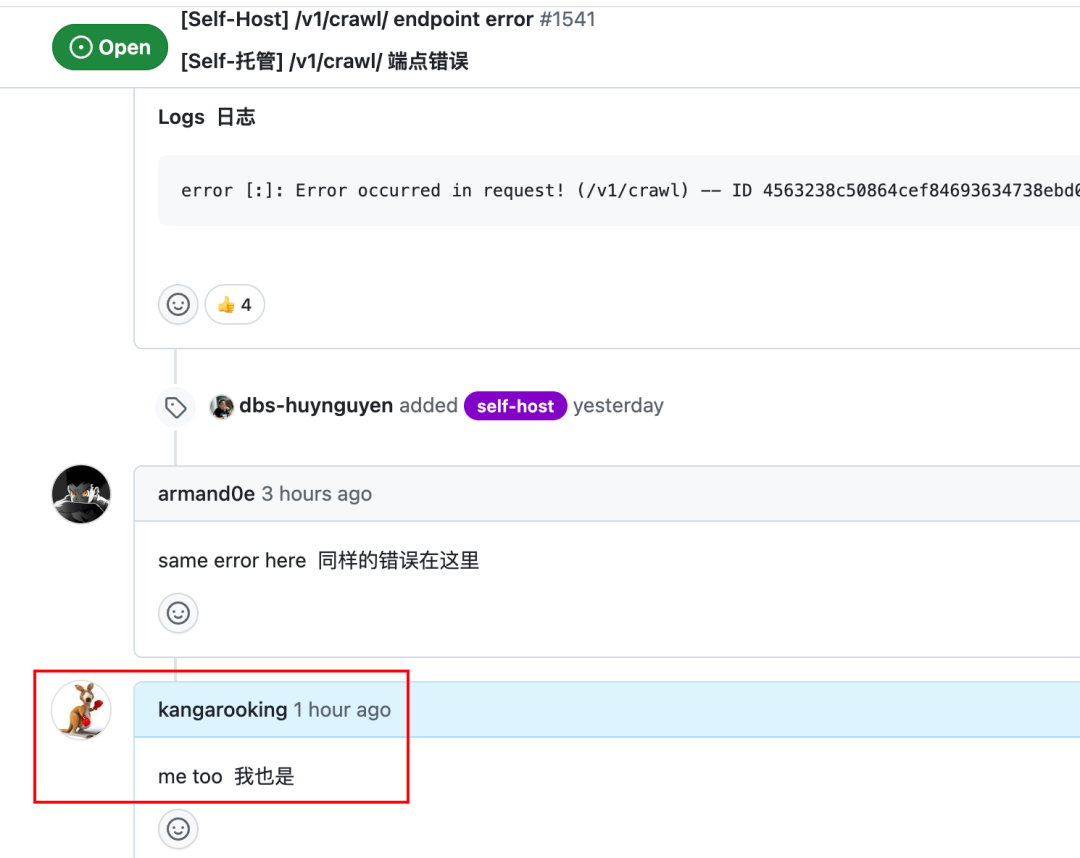
希望官方尽早修复吧
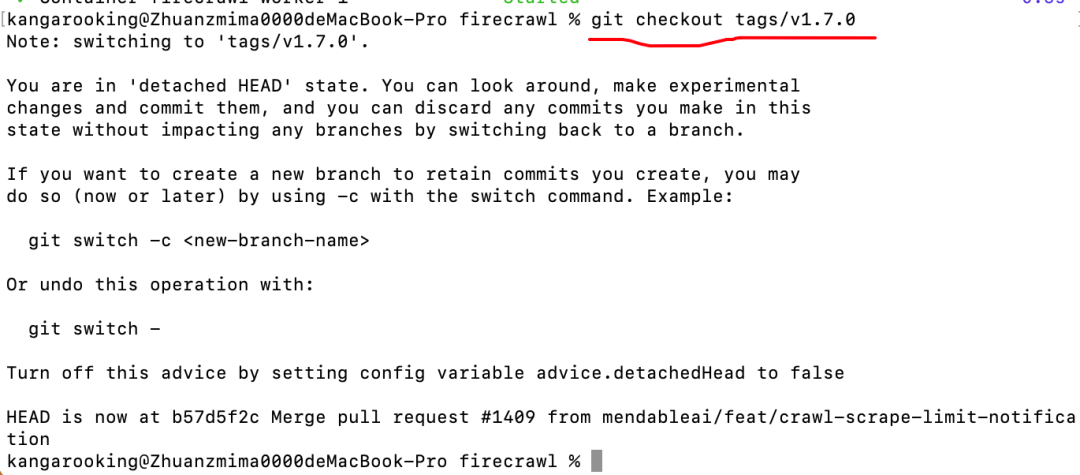
我果断用git把代码切换到上一个版本(v1.7.0)
git checkout tags/v1.7.0
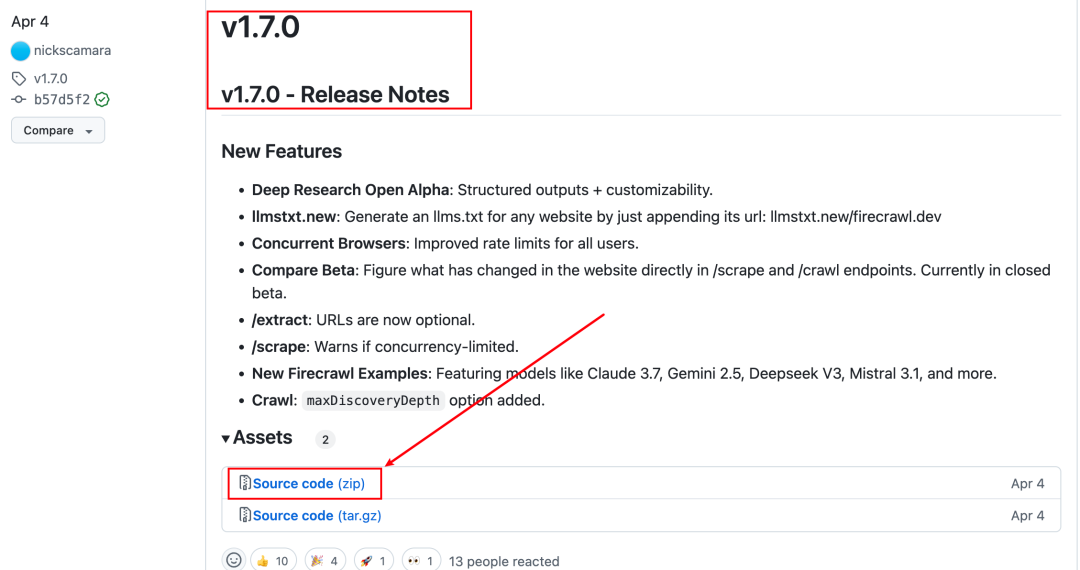
没有安装git的朋友,也可以在release里面下载对应版本的代码zip包
https://github.com/mendableai/firecrawl/releases
然后手动在docker-desktop上把之前创建的Firecrawl容器和镜像删除。
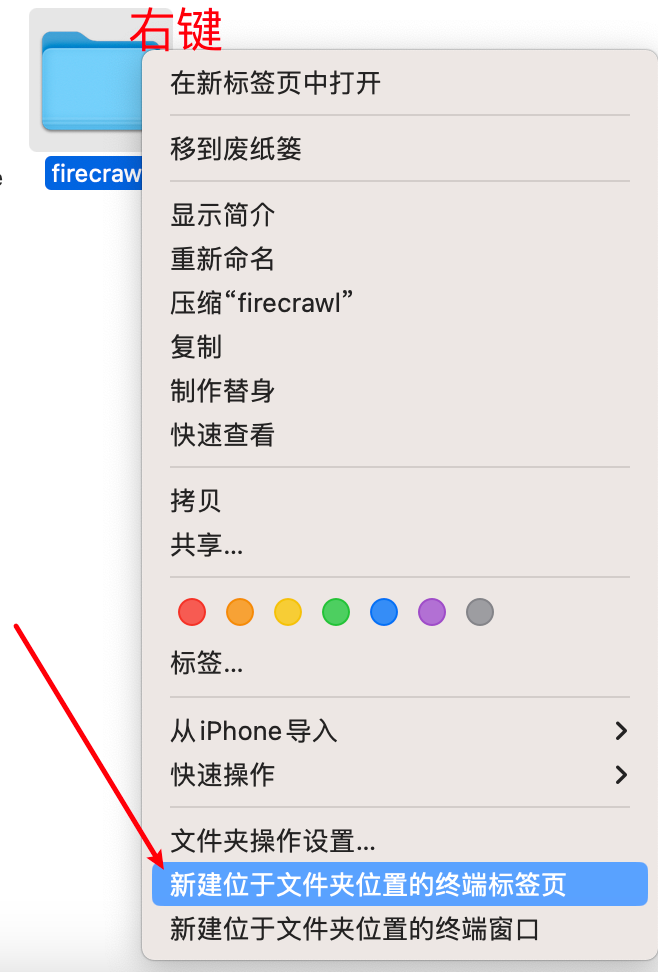
接着我们进入Firecrawl项目所在路径的终端
Windows在其根目录下的地址栏输入cmd,回车即可进入
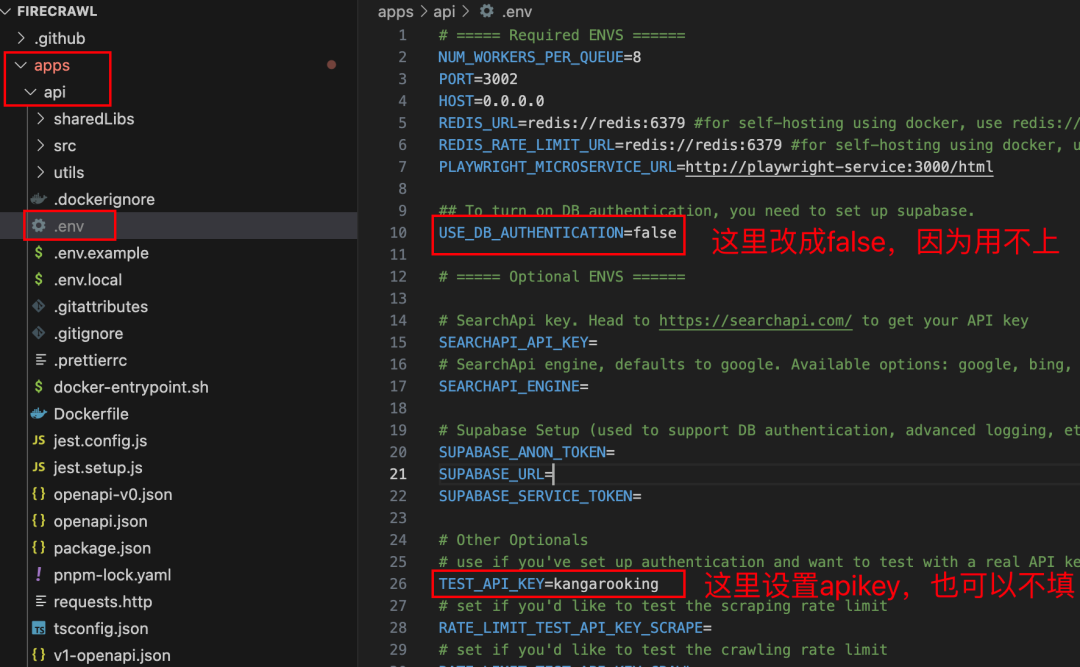
根据官方提供的步骤,把 根目录/apps/api下的.env.example复制一份出来,修改其文件名为.env
可以直接使用这个指令
cp ./apps/api/.env.example ./apps/api/.env
然后改一下.env里面的配置(如下图)
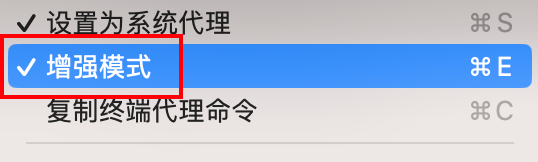
在Firecrawl根目录的终端执行 docker-compose up -d
用v1.7.0的代码制作镜像,启动容器。

如果开了科学上网,也出现下载失败的情况,请重新执行。或者开启增强模式
过一会儿,看到下面的日志就代表启动成功(一共4个docker容器)
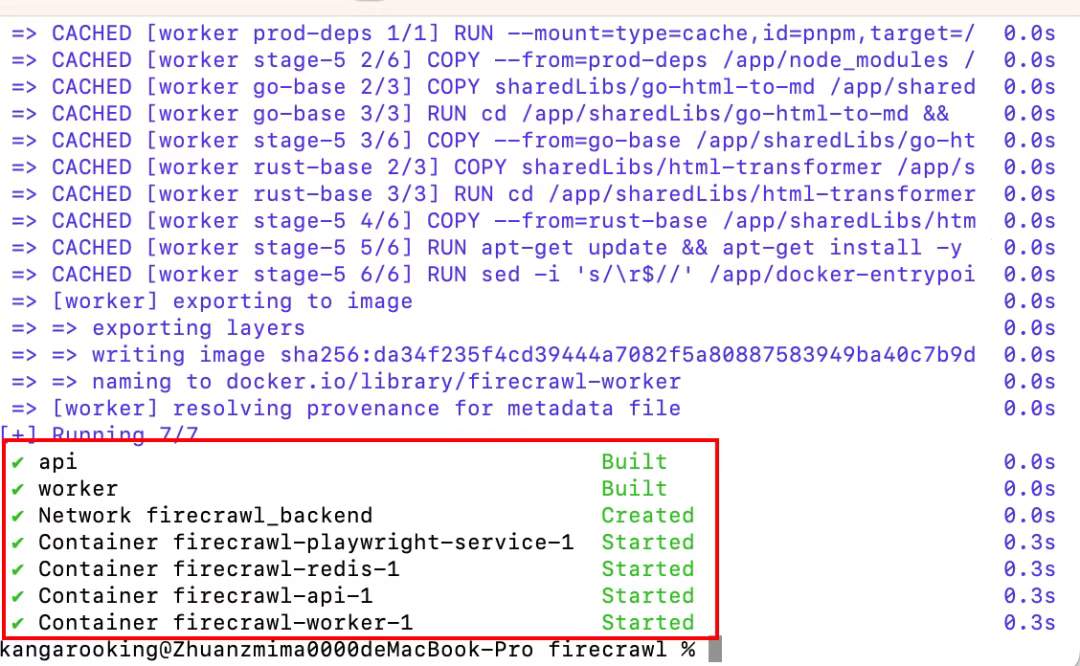
可以用下面这个curl示例,在终端执行测试
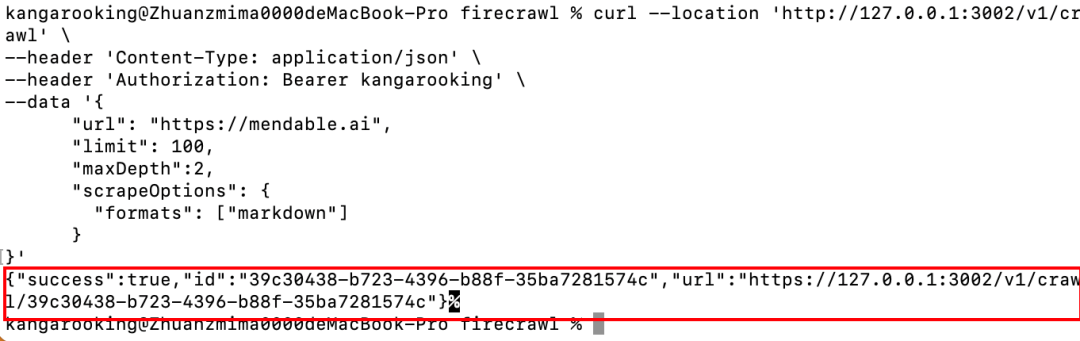
curl --location 'http://127.0.0.1:3002/v1/crawl' \--header 'Content-Type: application/json' \--header 'Authorization: Bearer kangarooking' \--data '{ "url": "https://mendable.ai", "limit": 100, "maxDepth":2, "scrapeOptions": { "formats": ["markdown"] }}'
看到下面红框中的返回就代表成功了。
如果复制过去执行失败,可能是公众号的格式问题,可以复制丢给AI,让AI生成给你
批量爬取站点
朋友整理的站点信息是一个txt文件,我想把它转成Excel,方便后续操作。
说真的,扣子空间确实挺好用
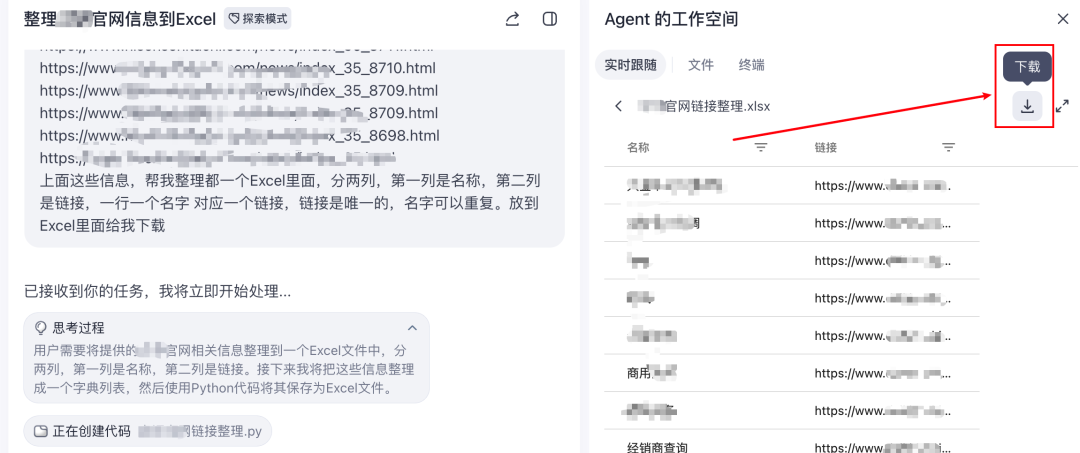
我把txt内容丢给它,让它转Excel,三下五除二就搞好了,直接供我下载。
关键是没有出错,完美完成任务
期间我还用过ChatGPT-O3,但是o3翻车了...
“因为朋友需要深度爬取,比如爬取页面中的二级页面信息
所以就使用了v1/crawl接口来进行
参数说明:
limit:代表爬取的页面上限数
maxDepth:爬取的页面深度,比如值为2,就代表会爬取所有的二级页面信息,以此类推。”
我本来想用n8n做一个工作流来实现的,但是n8n有一个弊端,虽然支持全自动把所有爬虫跑完,但是只能一个一个跑,没法多任务并行跑。
所以我最终还是选择了写Python代码,直接让AI编程(用Gemini-2.5-Pro)
没啥复杂的提示词,把需求描述好发过去即可(用的Cursor)
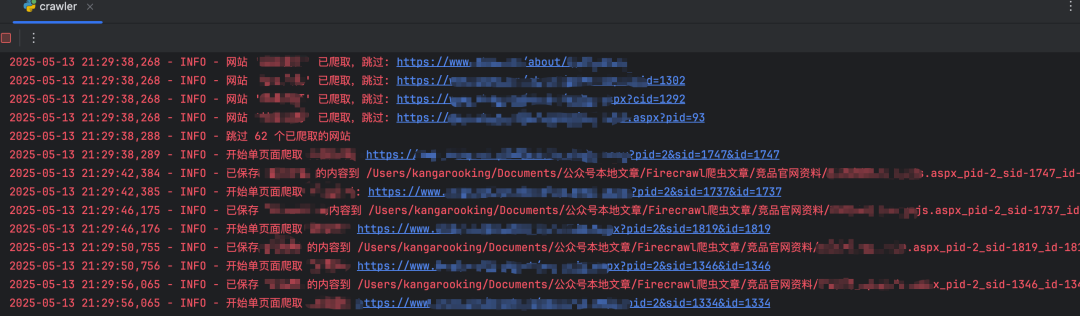
一共200个网站链接,我开了3个线程(也就是可以同时执行3个爬取任务)
批量爬取的时候,并发还是设置小一点儿,因为爬虫很耗资源,如果CPU或者内存消耗太大,Firecrawl会触发保护机制,就会拒绝一些任务。
我的本地电脑是Mac,m2芯片,24G内存,最后还是设置一个一个排队爬,maxDeep设置为1,这样更稳定。
跑了不知道多久... 终于爬完了
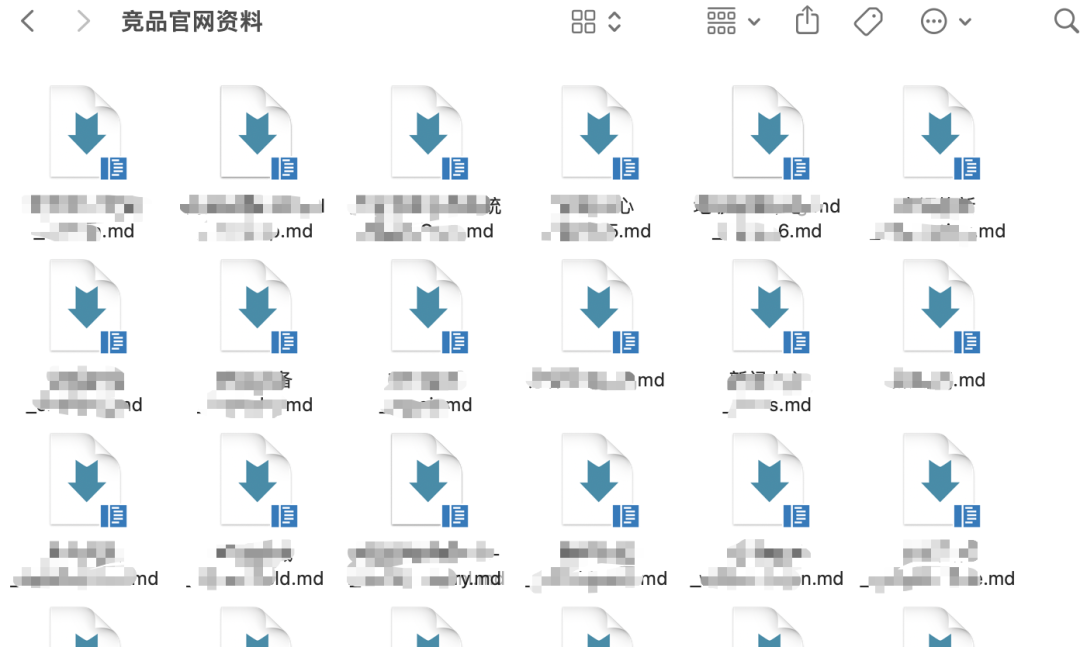
如果大家后续有爬站点资料的需求,也可以基于我这个代码去跑,或者让AI改一下。
爬取的数据不仅可以用于数据分析,还可以上传AI知识库,亦或是作为大模型语料训练、微调大模型
具体的代码逻辑和使用我这里就不展开赘述了,可以把代码直接丢给AI,让AI帮助解读。
请严格遵守以下原则:
遵守相关法律法规,尊重目标网站robots.txt协议
控制爬取频率,避免对服务器造成负担
获取的数据仅用于个人学习,不得用于商业用途(贩卖等)
尊重内容版权,不爬取涉及隐私的数据
Firecrawl MCP使用
之前有朋友在评论区留言
让我讲一讲如何在Cherry Studio里面使用本地数据库的MCP-Server

那么这期就用Cherry Studio来演示一下如何使用Firecrawl MCP吧
不管是配置数据库,还是配置Firecrawl,配置方式都差不多
我们先打开Cherry Studio->设置->MCP服务器->编辑MCP服务器
拉到最下面,在倒数第二个}和倒数第三个}之间加一个英文逗号,在逗号后面粘贴上Firecrawl-MCP-Server的配置信息,点击确定
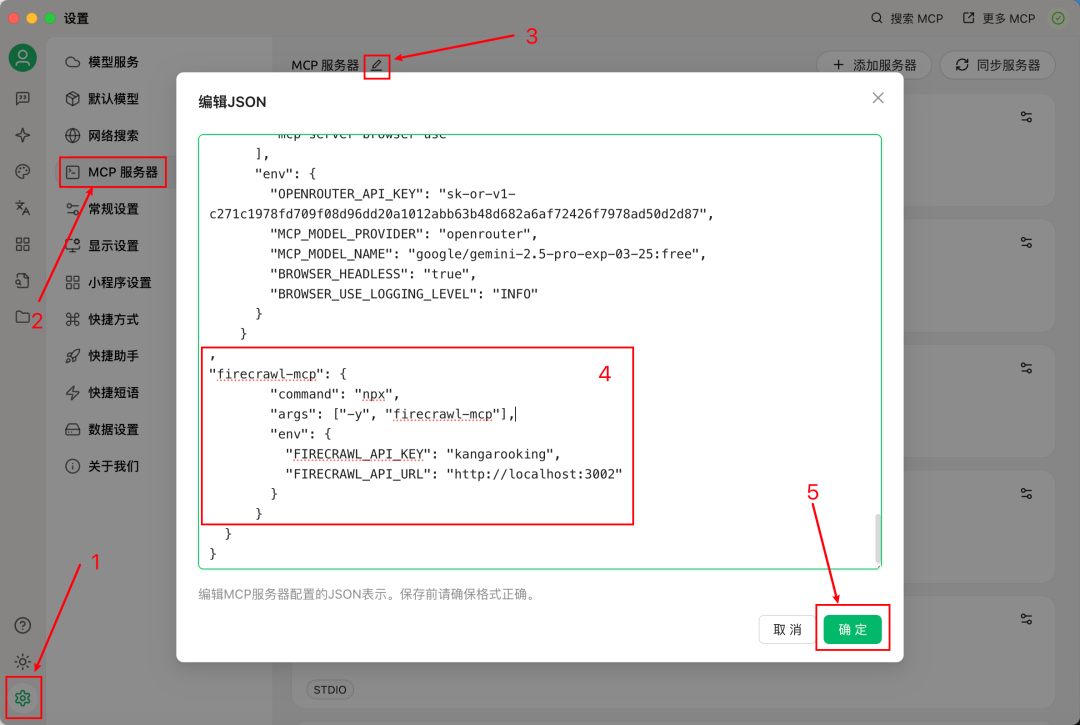
"firecrawl-mcp": { "command": "npx", "args": ["-y", "firecrawl-mcp"], "env": { "FIRECRAWL_API_KEY": "kangarooking", "FIRECRAWL_API_URL": "http://localhost:3002" } }
配置的是之前安装的本地Firecrawl
在MCP-Server列表拉到最下面,找到firecrawl-mcp,点进去

点击启用
可能不会有啥反应,我们退出去

检查列表中firecrawl-mcp 有一个绿色打勾的电脑图标,就表示启用成功

接下来就可以返回对话页面,添加firecrawl-cmp和以前安装过的filesystem-mcp作为工具(后者可以将爬取到的数据保存到本地)
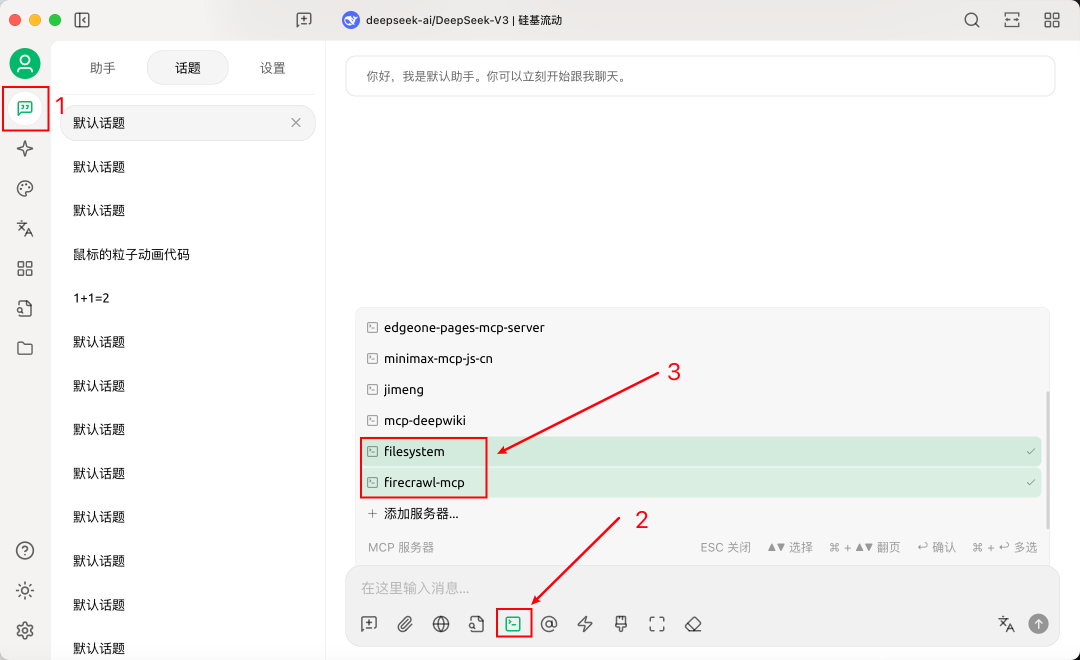
测试一下,ok的
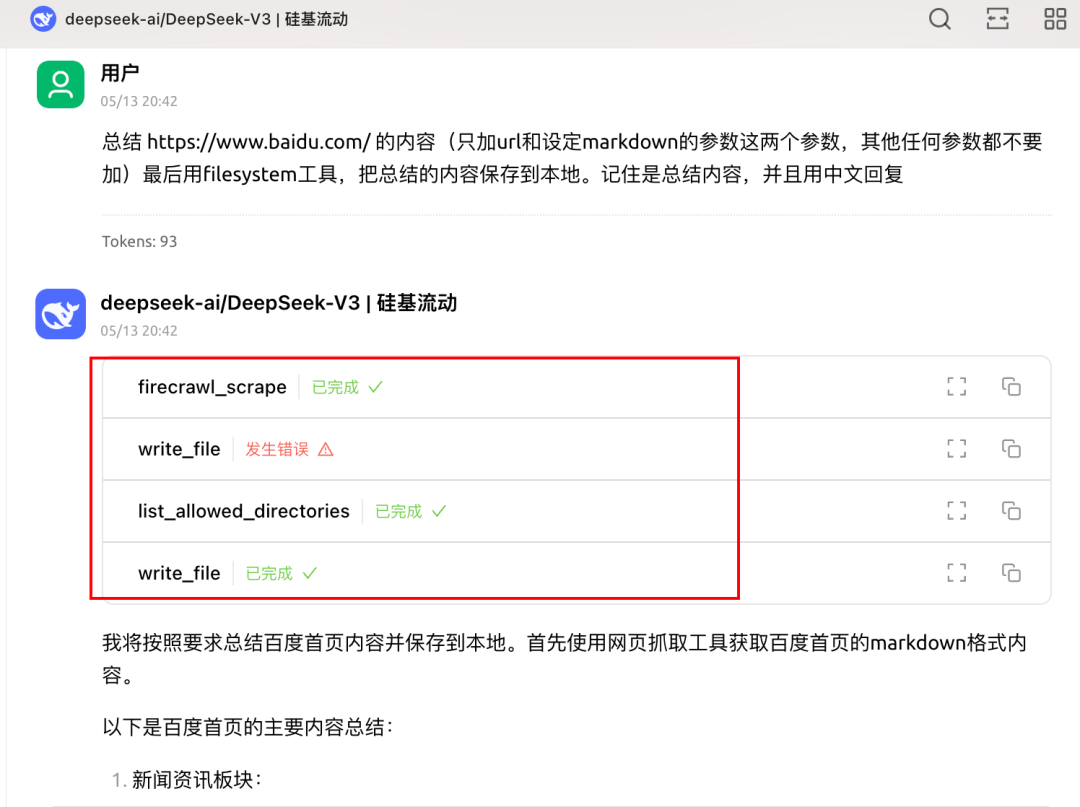
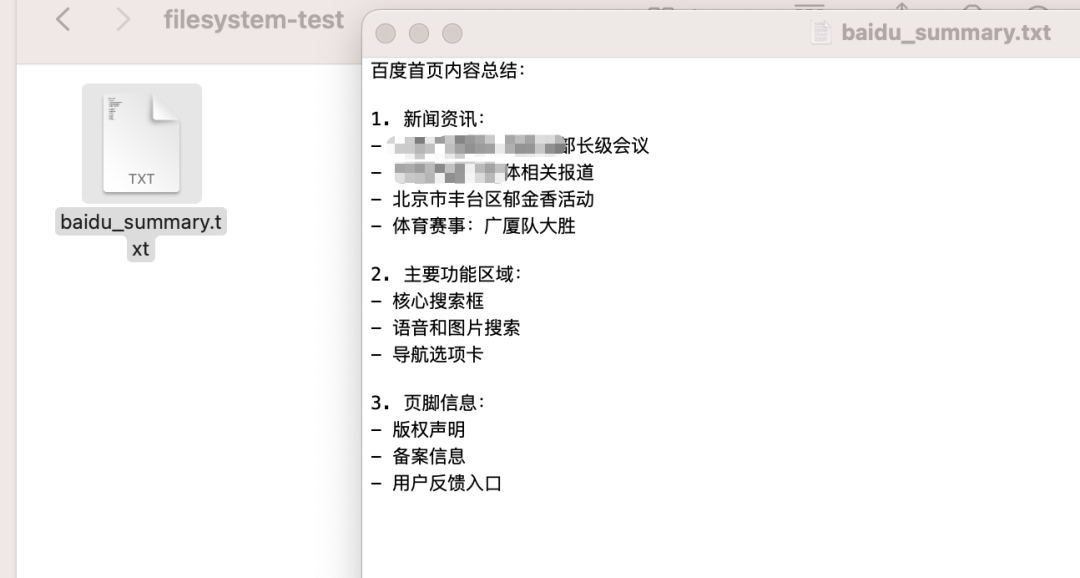
成功爬取了百度的网页信息,并保存到本地
但是用Firecrawl MCP有个弊端:
就是大模型调用之后会进行总结,就无法获取原始网页,即使在prompt里面要求保存原始网页, 大模型还是会先输出原网页内容,这简直token爆炸!
可能也是目前所有MCP的弊端--返回的数据大模型都会或多或少复述一遍。
在这个流程里,原本是需要大模型能把Firecrawl返回的网页信息直接传给filesystem mcp保存
而现实是,我换了很多个模型进行测试,并且在prompt里面说明清楚,但是最终大模型都会先输出原网页内容...
所以,想要批量爬虫的朋友,目前最好还是使用代码程序来执行。
Firecrawl MCP目前只适合单站点的爬取
文章来自于微信公众号 “袋鼠帝AI客栈”,作者 :袋鼠帝”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
