# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

有史以来最具想象力的小钢炮系列,MiniCPM 4.0 来了!
一口气带来 端侧性能大小王:
一款 8B 闪电稀疏版,创新稀疏架构掀起高效风暴;一款 0.5B,轻巧灵动的最强小小钢炮。
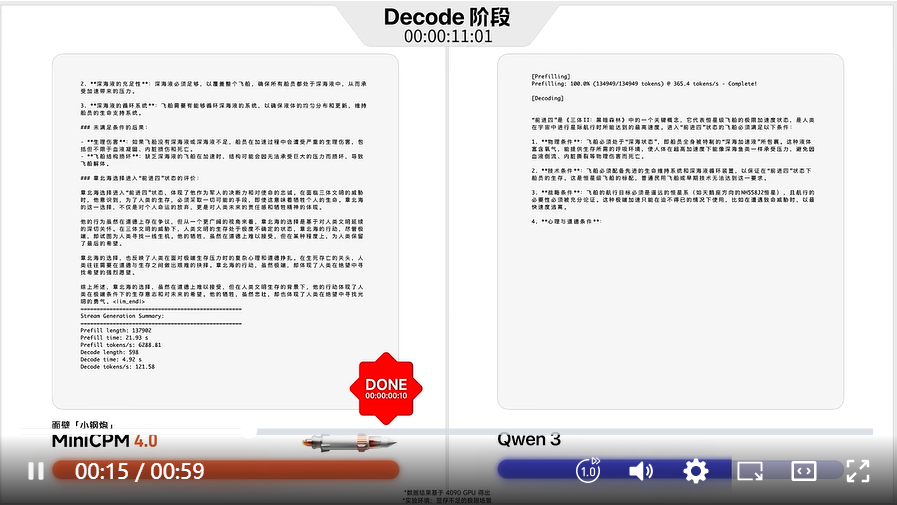
第一眼,震惊于它的速度
有多快?
极限情况下 220 倍、常规 5 倍的速度提升,来自系统级稀疏创新层层加速。
一次,是速度的狂飙。220 倍极致的速度提升,5 倍常规提速;
长长长文本,唰地一下处理完成。通过 高效双频换挡提速,长文本用稀疏,短文本用稠密,切换快如流!值得一提的是,这次我们实现了端侧存储的大升级,长文本缓存锐减,相较于 Qwen3-8B 仅需 1/4 的缓存存储空间。
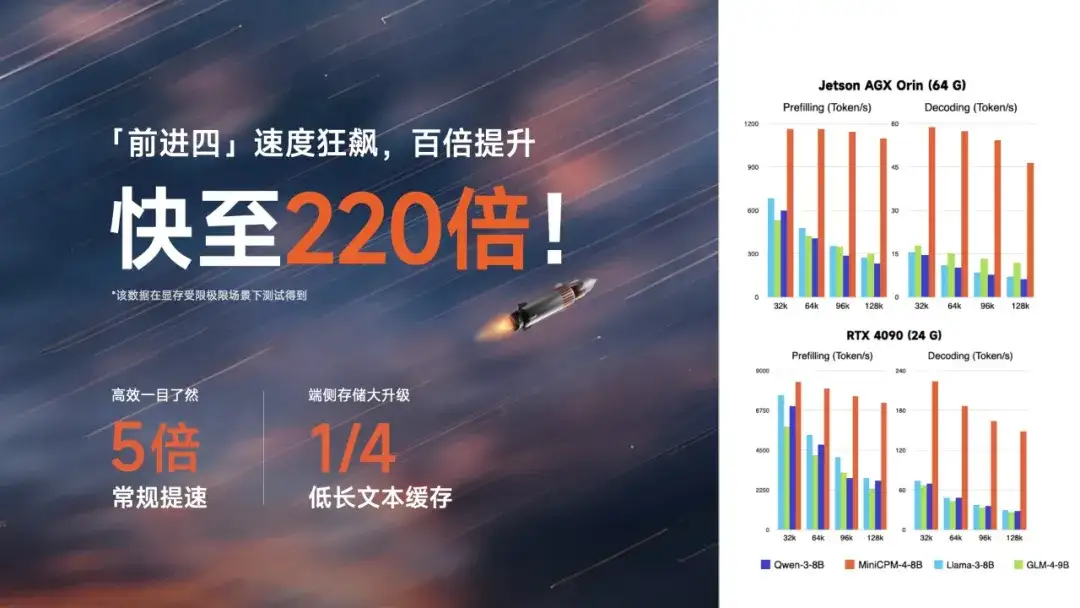
一次,是效能的狂想。创新大爆发,小钢炮 4.0 贡献了 行业首例全开源的系统级上下文稀疏化高效创新。5% 极高稀疏度,带来极限加速;更以目不暇接的自研创新技术,从架构层、系统层、推理层、数据层层层优化,真正做到 系统级软硬件稀疏化高效落地。

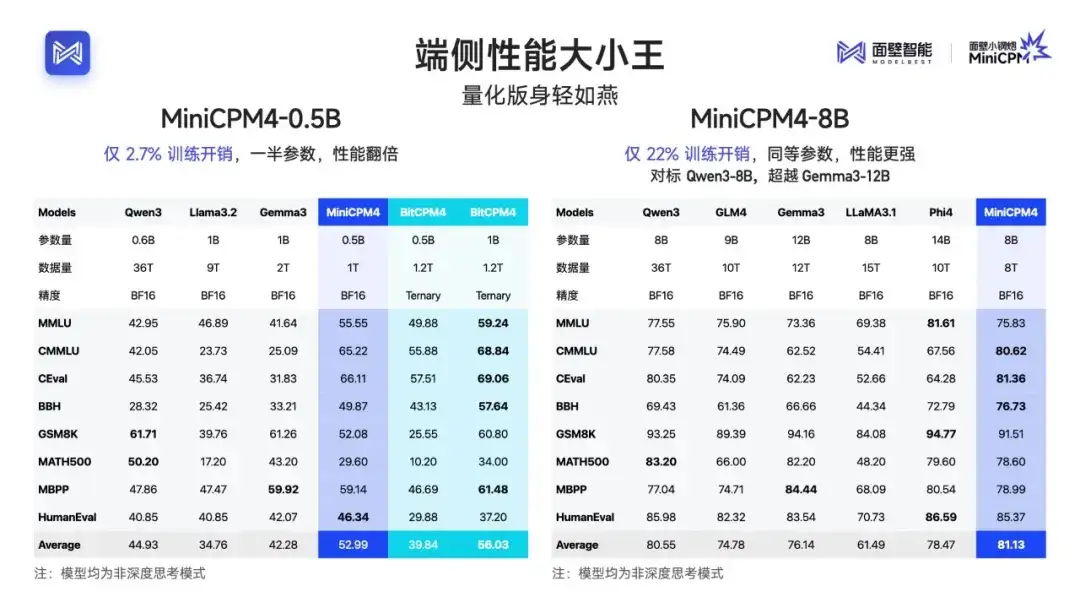
一次,是性能的迸发。延续 以小博大,0.5B
小小钢炮以 仅 2.7% 的训练开销,达到一半参数、性能翻倍效果;
8B 稀疏版仅 22% 训练开销,
对标超越 Qwen3, Gemma3 12B,卫冕 端侧最强。
一次,是落地的强悍。高效推理三级火箭,自研 CPM.cu 极速端侧推理框架,从 投机采样创新、模型压缩量化创新、端侧部署框架创新 几方面,带来 90% 的模型瘦身 和极致速度提升,实现端侧推理 从天生到终生的丝滑。

与此同时,面壁智能也携手诸多行业伙伴,持续推动 MiniCPM 4.0 模型适配及应用拓展。截止目前,MiniCPM 4.0 已实现 Intel、高通、MTK、华为昇腾等主流芯片的适配。例如,此次英特尔与面壁智能携手,在模型开发阶段即充分考虑英特尔硬件架构特性联合定制投机解码配置,结合英特尔加速套件与 KV Cache 内存增强技术,在 Intel 平台上基于 InfLLM v2 在 128K 长文本下已实现 3.8 倍推理速度提升,基于 FR-Spec 投机采样已实现 2.2 倍加速的推理优化效果,携手为业界带来了全新的模型创新和 PC 端性能体验。
此外, MiniCPM 4.0 可在 vLLM、SGLang、LlamaFactory、XTuner 等开源框架部署。

同时加强了对 MCP 的支持,且性能超过同尺寸开源模型(Qwen-3-8B),进一步拓展了模型开发、应用潜力。在应用上实现了端侧比肩 DeepResearch 的表现,可成为用户的端侧「小内阁」,随时随地生成高质量研究报告。

快 220 倍,极致的速度提升,意味着什么?
对于一个以「高效」为信仰的团队——
快,不仅是速度,更意味着我们是否在追求思想的领先,并将它付诸实地。

如同 F1 赛道上,冠军风驰电掣的身影,起源于草稿簿上天才想法的起笔,血脉贲张于引擎、燃油、加速、散热等环环连扣动力系统从内而外的优化,锱铢必较于每一条车身曲线风阻最优化的计量,无数看不见的细节串联成就了世人面前的惊鸿一跃。
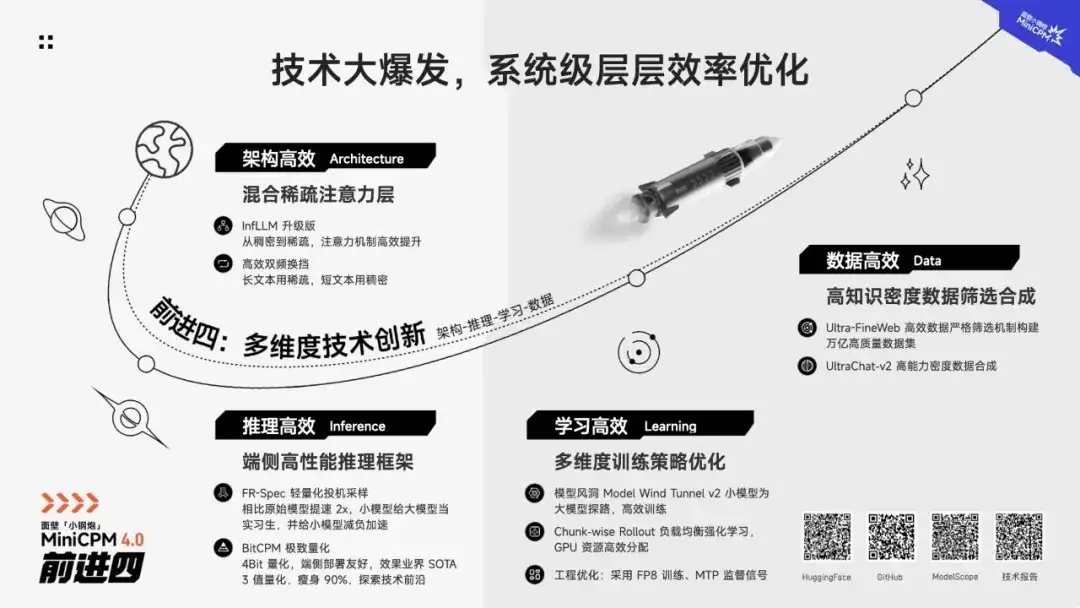
每一寸模型「效率」进击的背后,是对包括模型层、系统层与硬件层这套复杂架构的系统级创新优化;意味着将每一寸效率提升、能耗降低的空间,极致探索。
甚至,榜单上一个身位的领先,背后可能是设计思想与制造产线积累建设的“十年”之功……
在模型领域,上一个给我们带来如此系统级创新震撼的是年初的 DeepSeek。而这次,我们希望在深耕的端侧领域,做出一些微小贡献。

引入稀疏注意力架构,做从内而外的创新,为什么在当下如此重要?
一是长文本处理、深度思考能力,成为人们对大模型能力愈来愈迫切的需求,而传统稠密模型上下文窗口受限;
二是 DeepSeek 等明星项目以稀疏模型架构撬动的「高效低成本」收益 愈益得到关注认可;而 端侧天然因存储带宽限制等严苛限制,对效率提升与能耗降低要求更加迫切。
专注端侧高效探索数年,我们首次将算法架构与硬件推理一体化创新,带来这次超乎想象的小钢炮模型升级。
➤ 架构高效
InfLLM 稀疏注意力结构再升级
从逐字重复计算,到分块分区域高效「抽查」
稀疏度越高,意味着加速比越高、模型越高效。第二代 InfLLM 工作,将稀疏度从传统 40%-50%,提高至极致的 5%,计算量降低至 10%,且对算子底层重写,进一步加速提升,并使得对文本相关性精准性大大提升。
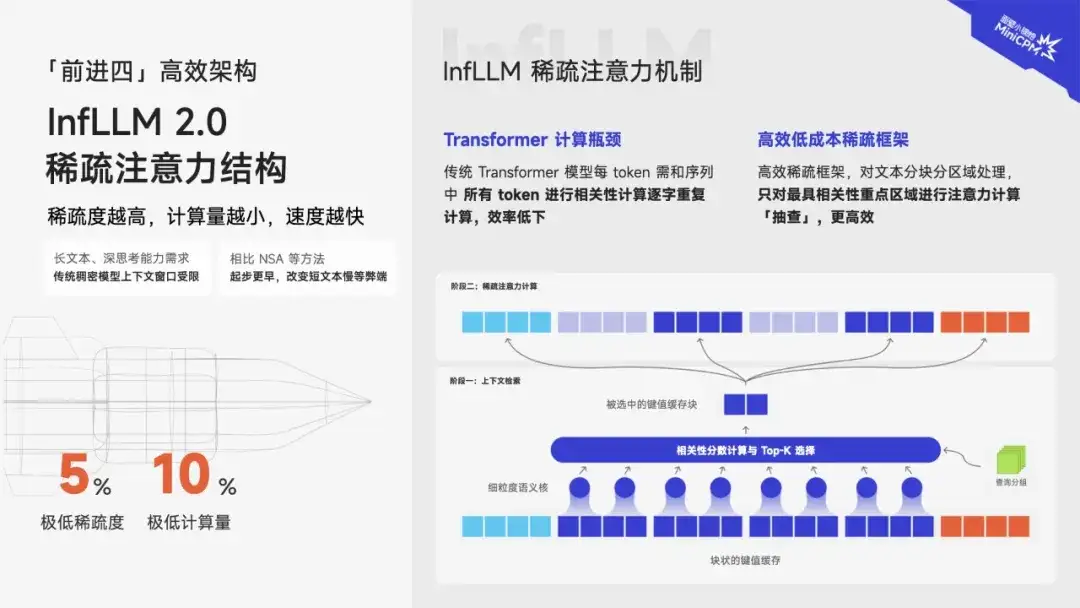
在传统 Tansformer 模型的相关性计算中,每个 token 都需要和序列中所有 token 进行相关性计算,重复且低效;我们以 InfLLM 高效稀疏架构对文本进行分块分区域处理后,只需对最有相关性的重点区域进行注意力计算「抽查」,更加高效!
➤ 推理高效
推理高效三级火箭
自研全套端侧高性能推理框架
在推理层面,MiniCPM 4.0 通过 CPM.cu 自研推理框架、BitCPM 极致低位宽量化、ArkInfer 自研跨平台部署框架等技术创新,实现了极致的端侧推理加速。
CPM.cu 端侧自研推理框架,做到了 稀疏、投机、量化的高效组合,最终实现了 5 倍速度提升。其中,FR-Spec 轻量投机 采样类似于 小模型给大模型当“实习生”,并给小模型进行词表减负、计算加速。通过创新的词表裁剪策略,让小模型专注于高频基础词汇的草稿生成,避免在低频高难度词汇上浪费算力,再由大模型进行验证和纠正。
BitCPM 量化算法,实现了业界 SOTA 级别的 4-bit 量化,并成功探索了 3 值量化(1.58bit)方案。通过精细的混合精度策略和自适应量化算法,模型在瘦身 90% 后,仍能保持出色的性能表现。
ArkInfer 自研跨平台部署框架,面向 多平台端侧芯片极致优化,实现了大平台的高效投机采样和限制编码,确保端侧多平台 Model Zoo 丝滑使用。
自 2024 年,我们已开启 InfLLM 为代表的稀疏注意力研究。同时相比思想上与 InfLLM 同源、年初 DeepSeek 发布的 NSA 方法,可以有效改善短文本速度较慢的弊端。 通过创新架构自动换挡,可针对不同任务切换注意力机制——
稀疏注意力机制,处理高难度的长文本、深思考;稠密注意力机制,一般短文本轻松拿捏;实现了长文本、短文本的双重丝滑。

为什么面壁总能带来同等参数、性能更强,同等性能、参数更小的先进模型?
区别于业界普遍采用的“大力出奇迹”路线,面壁智能坚持以效率为核心的技术路径。
对大模型科学化的探索,贯穿从数据、训练、学习、推理等层层流程。看得见的领先背后,是无数看不见的「黑科技」,与数不完的严苛标准;是点点滴滴细节精益求精的结果沉淀。

➤ 学习高效
模型风洞 ModelTunnel v2
小模型为大模型打草稿,高效训练
小模型为大模型探路,高效训练
小模型寻求大模型训练最佳配置,将学习率、批大小等移至大模型训练,完成最优配置搜索
Chunk-wise Rollout
负载均衡强化学习,GPU 资源高效分配
RL 训练中,单一数据过长时,将在 GPU 上产生大量空泡,导致负载不均
因此将长数据分段采样,使其在下一阶段继续生成
DeepSeek 同款工程优化
极致探索点滴效率提升空间
➤ 数据高效
UltraClean高效数据严格筛选机制
构建万亿高质量数据集
“半成品加工法” 高效验证 ,90% 成本下降
先训一个“半熟”模型,再用新数据快速微调,如同预制菜快出成果
轻巧 fastText 工具,进行 LLM 质检
处理 15 万亿数据只需 1000 小时 CPU,如同扫地机器人代替保洁大队!
UltraChat-v2
高能力密度数据合成
高能力密度数据合成,构建大规模知识密集型、推理密集型、指令遵循型、长文本处理型、工具调用型,多文样化的有监督微调数据

MiniCPM 4.0 的发布,是汇集了我们创新技术信仰的纵身一跃,亦是 大模型成长规律「密度定律」的又一 成功验证。
当前,面壁小钢炮 MiniCPM 系列 已获得全平台 破千万的下载。未来,基于「密度定律 」,还将持续提高大模型的知识密度与智能水平,推动端侧智能高效发展与规模化产业应用。
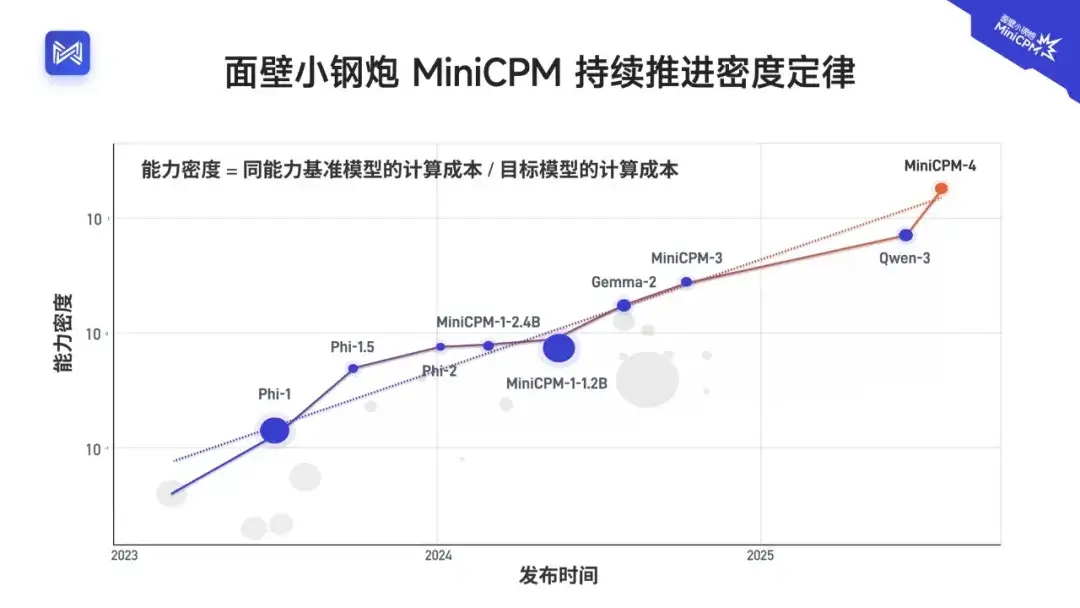
伴随大模型训练成本的加速降低,知识密度的极速提升,我们相信,未来每个终端设备都将搭载一个人类智慧等级的端侧大脑。
端侧大模型完成与智能终端完成神经突触链接,将唤醒端侧 AGI 的觉醒时刻。
那时,正如信息革命到来,以每个人拥有个人电脑、个人手机为标志;AGI 智能革命到来的时刻,人人将享有专有化的智能,处处将闪耀高等智能的灵光,以突破网络限制、充分保障信息安全的贴身距离,随时随地、千人千面,贴心响应每一个个性化的需求。
那时,高效高性能的端侧智能,也是你的专属智能,将成为你最值得信任的默契好友,陪你跨越人生海海,走遍天涯海角!

*附录 面壁核心科研团队稀疏模型架构研究项目一览表
自2021年,面壁智能 与 OpenBMB 社区 的核心研究员们已经注意到:人脑仅需平均不到 20 瓦能耗即可完成复杂认知任务,其高效机制的其中两大核心,正是基于 稀疏激活(每次平均不到 5% 神经元参与任务)与 功能模块化(不同区域分工协作)。我们发现大模型前馈网络中也存在显著的稀疏激活与功能模块演化现象,这一认知启发我们重新审视大模型的计算结构,试图在智能演化与效率之间寻找更优的路径。由此,奠定了团队在高效大模型方向的基础工作。
2023年5月
在《Emergent Modularity in Pre-trained Transformers》成果中,研究团队发现:大模型在预训练过程中会自发形成功能模块,就像大脑皮层中的视觉、语言区域分工协作。
➤ 论文链接:
🔗 https://arxiv.org/pdf/2305.18390
➤ 开源链接:
🔗 https://github.com/THUNLP/modularity-analysis
2021 年 10 月
清华 NLP 实验室联合微信团队、上海清华国际创新中心、BAAI 智源研究院和 AIR 研究院等提出了一种模型压缩新方法:MoEfication 来解决大模型落地时的计算瓶颈。只用原来 20% 的 FFN 计算量,就能保持原始大模型的效果。
➤ 论文链接:
🔗 https://arxiv.org/pdf/2110.01786
➤ 开源链接:
🔗 https://github.com/thunlp/MoEfication
2024年9月
《Configurable Foundation Models》一文,提出了一种更先进的类脑 AI 结构。 通过设计可插拔的模块接口,它不仅考虑了训练过程中的“模块化”,还把模型后期如何调整、扩展都考虑进去了。
这个架构的一个重要发现是:大模型在训练的过程中,其实会自动“分区”——有的部分擅长语言,有的擅长数学,有的专攻编程,而且每次用的时候,只会激活相关的那一部分,其他部分并不会运行。也就是说,大模型本身就有点像人脑,不是所有部分都一起运转,而是“用哪块、启动哪块”。
训练大模型就像搭积木一样灵活,可以按需组合、更新、扩展,不仅提升了模型的“知识密度”,也让模型在设备端运行得更快、更省电。
➤ 论文链接:
🔗 https://arxiv.org/pdf/2409.02877
➤ 原文回溯:
🔗 MoE之外,高效稀疏模型架构的狂飙!清华&面壁团队新发现
2024年2月
团队联合中国科学院计算技术研究所、腾讯公司等提出了 ProSparse 方法,探索如何在保证模型性能的同时提高稀疏度。
➤ 论文链接:
🔗 https://arxiv.org/pdf/2402.13516
➤ 稀疏模型开源地址:
ProSparse LLaMA2-7B:
🔗 https://huggingface.co/SparseLLM/prosparse-llama-2-7bProSparse
LLaMA2-13B:
🔗 htttps://huggingface.co/SparseLLM/prosparse-llama-2-13b
➤ MiniCPM-S 1B:
🔗 https://huggingface.co/openbmb/MiniCPM-S-1B-sft
2024年2月
团队联合上海交通大学 IPADS 组、中国科学院计算技术研究所和中国人民大学高瓴人工智能学院等机构发表成果ReLU²,研究揭示:只要选对合适的激活函数,模型能在保持智商的同时节省 90% 的脑力消耗。就像人类遇到简单问题不会动用全部脑力,科学家发现大模型也能开启节能模式。
➤ 论文链接:
🔗 https://arxiv.org/pdf/2402.03804
➤ 模型链接:
🔗 https://huggingface.co/SparseLLM
2024年11月
研究团队开展了一项名为 Sparsing Law 的研究,旨在对大模型稀疏激活的 scaling 特性及影响因素进行全面、系统性的研究。研究团队提出更准确、更通用的稀疏度衡量指标——CETT-PPL-p%。
➤ 论文链接:
🔗 https://arxiv.org/pdf/2411.02335
➤ 开源链接:
🔗https://github.com/thunlp/SparsingLaw
文章来自于微信公众号“面壁智能”。




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
