# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
干货来了!
如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。
就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。
Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。

让我们也来跟着大神学习一下。
首先,什么是大模型推理呢?
其实就是大语言模型在给出最终答案前的中间思考步骤。

比如问
“artificial intelligence”每个单词的最后一个字母连起来是什么?
有推理过程的回答会先分别找出“artificial”的最后一个字母是“l”,“intelligence”的最后一个字母是“e”,再把它们拼接成“le”;而没有推理的就直接给出“le”这个结果。
这种推理过程和人类的思维过程无关,而关键在于生成了大量的中间内容。
那为什么中间思考步骤很重要呢?
一个原因是它可以让复杂问题变得可解。
简单来说,对于能用布尔电路解决的问题,假设电路规模是T,哪怕是固定大小的Transformer模型,生成O(T)个中间步骤就能搞定。
但如果跳过中间步骤,直接让模型输出最终答案,要么需要极深的模型层数(增加计算成本),要么根本无法解决。
Denny Zhou和马腾宇等人的著作《Chain of Thought Empowers Transformers to Solve Inherently Serial Problems》提到如果给Transformer引入思维链,就能大大提高模型推理能力。
这篇论文说明了只要引入思维链,那么无需扩展模型的规模就能让Transformer变得强大到能解决任何问题。
理论上来说,只要有足够的CoT步骤,Transformer就可以模拟多项式大小电路可以执行的任何计算,从而缩小了Transformer与图灵机之间的差距。

另一方面是中间步骤可以提升答案的准确性和可靠性。
没有推理步骤时,模型可能靠“瞎猜”给出答案。
例如问:
我有3个苹果,爸爸比我多2个,一共多少个?”
直接输出的答案可能是错误的“5个”;
但有推理步骤的回答就是“爸爸有3+2=5个,总共3+5=8个”),答案更可能正确。
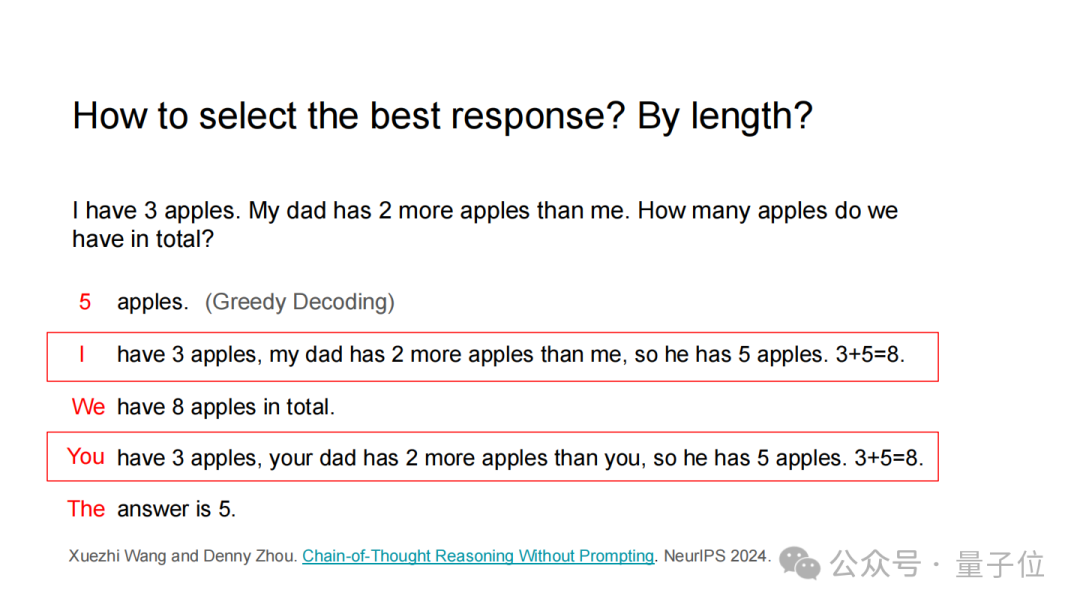
这是因为推理步骤迫使模型有理有据地推导,尤其是对需要逻辑链条的问题(如数学、因果分析),减少了随机猜测的概率。
就像做数学题一样,一步步推导可比瞎蒙准确率高多了。
并且,对于有推理过程的答案会让模型更有信心。
Denny Zhou还强调预训练模型即使没有经过任何微调,也具备推理能力。
只不过,基于推理的输出通常不会出现在输出分布的优先级部分,因此无法通过贪婪解码(选择概率最高的输出)输出。

那么我们如何让它输出推理后的答案呢?
一种方法是提示。
既然模型对于有推理过程的答案更有信心,那么我们可以通过思维链提示或者加上提示词来让模型进行推理。
比如思维链提示,你可以给它一个带步骤的例子,给它打个样。或者你可以告诉它:让我们一步步想。
不过,Denny Zhou和Xuezhi Wang在《Chain-of-Thought Reasoning Without Prompting》一文中提出其实不用这些提示,只要改变模型的解码方式,就能让预训练的语言模型展现出推理能力。

原来模型在生成答案时,通常只用最可能的那个词(贪心解码),但如果看看排在后面的几个可能的词(top-k替代词),会发现里面藏着一步步推理的路径。
而且当有这种推理路径时,模型对答案的信心也更高。
于是他们提出了CoT-decoding方法,就是从这些top-k的解码路径中,选出那些有推理过程且模型信心高的路径,这样能让模型在各种推理任务上表现得更好,甚至能接近经过指令微调的模型效果。
不过,另一种方法就是监督微调(SFT)。
监督微调就是用人类写的带步骤的题和答案训练模型,让模型学着生成类似的步骤。
但这种方法有个问题是泛化性不太好,换个新场景可能就不灵了,而且模型做大了也没用。
于是,研究人员对监督微调进行了改进,一种是自我改进,让模型自己生成步骤和答案,然后用正确的那些训练自己,有点像学生自己做题纠错。
另一种是强化学习微调,反复让模型生成答案,多练正确的,少练错误的。这里面,能判断答案对不对的“验证器”很重要。

现在,强化学习微调已成为了引出推理的最强大的方法。
并且,Denny Zhou认为扩展强化学习应该专注于生成长响应,也就是《Chain of Thought Empowers Transformers to Solve Inherently Serial Problems》这篇文章中的观点。
另外,进一步的重大改进是聚合和检索的方法。
LLM是概率模型,其解码时追求的是在给定问题下推理和最终答案的联合概率最大,而我们想要的是给定问题下最终答案的概率最大,两者并不一致。

于是有了以下改进方法:
最后,Denny Zhou总结了提升LLM推理能力的要点:

并指出未来的突破方向是解决非唯一可验证答案的任务,以及构建实际应用而非仅解决基准测试问题。
Denny Zhou是中科院博士,2017年加入Google前在微软担任了11年的高级研究员。

他创立并领导了Google Brain中的推理团队,Google Brain现已成为Google DeepMind的一部分。
他的研究目标是通过构建具备推理能力的大型语言模型解决人工通用智能(AGI)问题,核心方向包括思维链、自洽性、任务分解、零样本学习、组合泛化及大语言模型理论等,追求实现完美泛化。
在2022年,他荣获谷歌研究技术影响力奖、2022年WSDM时间考验奖等。
近年来,他多次受邀在耶鲁大学、哈佛大学、斯坦福大学等多所高校和机构进行主题为语言模型推理的演讲。
这次Denny Zhou在斯坦福大学CS25课程上用的课件已附在文末~
完整版pdf:https://dennyzhou.github.io/LLM-Reasoning-Stanford-CS-25.pdf
参考链接:
[1]https://x.com/denny_zhou/status/1948499173986201915
[2]https://dennyzhou.github.io/
文章来自于微信公众号“量子位”,作者是“闻乐”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
