# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你有没有想要修复的老照片或者视频?
好消息来了!
这两天我在逛 L 站的时候偶然发现一位佬友的安利帖,直接被种草。
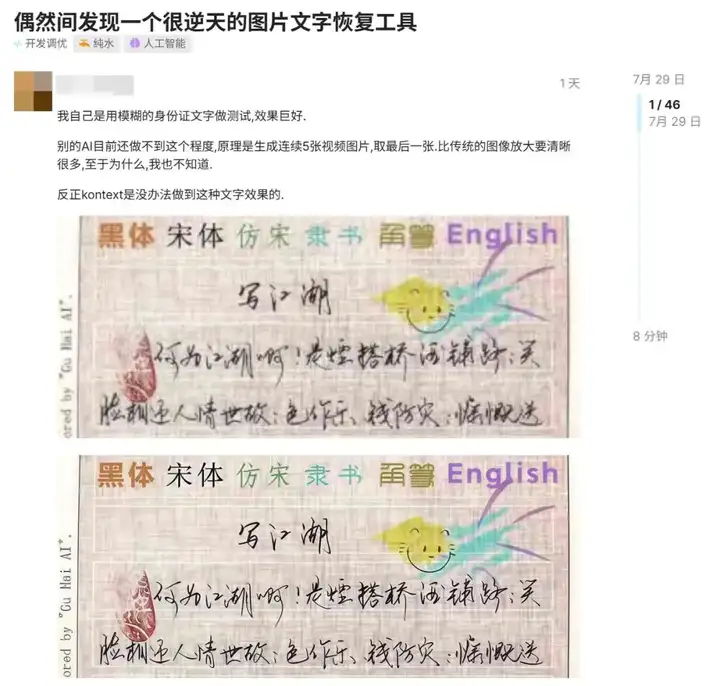
评论区也是清一色的好评。





帖子里提到的工具是由字节发布的视频和图片高清修复模型:SeedVR2 。

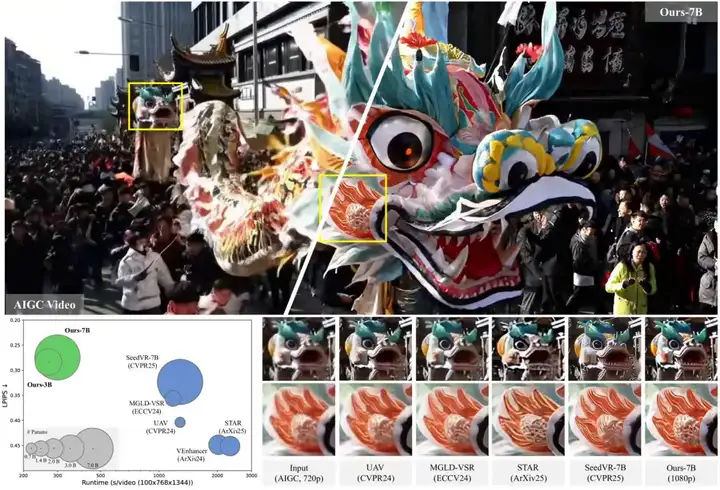
我们先来一起感受一下它的视频修复前后对比效果。

是不是很清晰?更关键的是清晰的很真实,没有那股 AI 味。
再来看图像增强的前后对比。

还有增强的局部细节。

不得不说,这效果,确实有点东西。
我们顺藤摸瓜找到了这个项目,它不仅可以直接在 ComfyUI 上运行,也可以直接在本地跑。
项目指路:
https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler
我们先来一起看看这个项目的论文。
现有 VR 方法要想实现生成逼真的细节,通常需要数十个步骤才能生成视频样本,从而导致相当高的计算成本和延迟。 在处理高分辨率的长视频时,如此巨大的成本会进一步放大。
相比起来,SeedVR2 针对真实数据执行对抗性 VR 训练。大量实验结果表明,SeedVR2 只需一步即可实现相当甚至更好的性能。
那么,SeedVR2 是怎么在显著降低计算成本的同时还保证甚至提升了视频高清修复的质量呢?
首先自然是大大降低的计算成本。
与其他 VR 方法相比,SeedVR2 训练了有史以来最大的 VR GAN(生成器和鉴别器总共约 16B ),可以在单个采样步骤中实现高质量的恢复,效率很高。
SeedVR2 采用了扩散对抗性后训练(APT),通过确定性蒸馏和对抗性后训练从而消除了传统知识蒸馏方法中需要预先生成大量样本的计算成本。
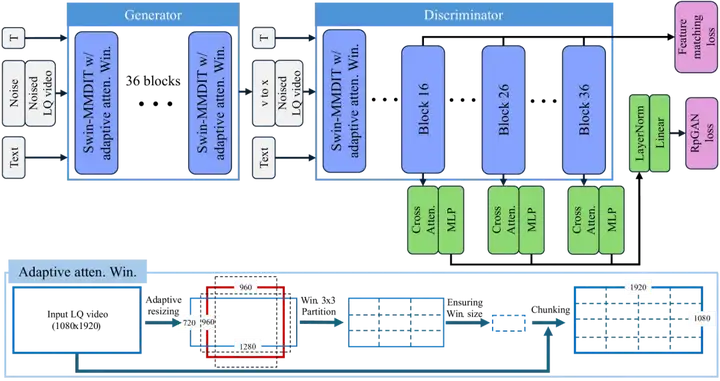
其次,SeedVR2 提出了一种有效的自适应窗口注意力机制,能够在具有清晰细节的单个前进步骤中实现高效的高分辨率。
其中动态调整窗口大小以适应输出分辨率,避免使用具有预定义窗口大小的窗口注意力在高分辨率 VR 下观察到的窗口不一致。这也让 SeedVR2 具备了处理高分辨率视频的能力。
最后,SeedVR2 也对训练过程进行了优化。在进行对抗训练之前,首先采用渐进式蒸馏策略。并且使用 RpGAN loss 替代了传统的非饱和 GAN 损失,以避免模式崩溃问题。
这个项目的亮点还有很多,感兴趣的小伙伴可以移步下面的链接:
https://arxiv.org/abs/2506.05301
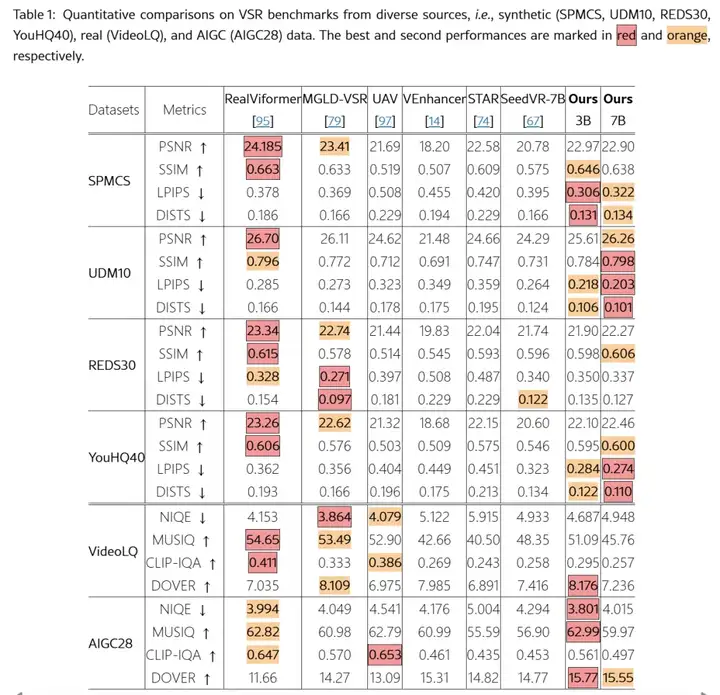
SeedVR2 在 72 块 NVIDIA H100-80G GPU 上进行训练。评估涵盖了合成数据集(如 SPMCS,UDM10)、真实世界数据集(VideoLQ)和 AIGC 数据集(AIGC28) 。
评估指标包括全参考指标(PSNR, SSIM, LPIPS)和无参考指标(NIQE, MUSIQ, DOVER)。
可直接从 Comfyui-Manager 访问,搜索“seedvr2”并单击“安装”并重新启动。
也可以采取以下方式:
cd ComfyUI/custom_nodes
git clone https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler.git
若使用虚拟环境(venv):
pip install -r ComfyUI-SeedVR2_VideoUpscaler/requirements.txt
安装 flash_attn/Triton,过程速度提高 6%(不是强制性的)
pip install flash_attn
pip install triton
若使用 ComfyUI 内嵌 Python(python_embeded):
python_embeded\python.exe -m pip install -r ComfyUI-SeedVR2_VideoUpscaler/requirements.txt
python_embeded\python.exe -m pip install flash_attn triton
模型将自动下载到:models/SEEDVR2

可以将 SeedVR2 Video Upscaler 作为独立的多 GPU 支持脚本运行,而无需 ComfyUI。
git clone https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler SeedVR2_VideoUpscaler
cd SeedVR2_VideoUpscaler
conda create -n seedvr python=3.12.9
conda activate seedvr
or
python -m venv venv
windows :
.\venv\Scripts\activate
linux :
source ./venv/bin/activate
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txt
usage: inference_cli.py [-h]
--video_path VIDEO_PATH
[--seed SEED]
[--resolution RESOLUTION]
[--batch_size BATCH_SIZE]
[--model {
seedvr2_ema_3b_fp16.safetensors,
seedvr2_ema_3b_fp8_e4m3fn.safetensors,
seedvr2_ema_7b_fp16.safetensors,
seedvr2_ema_7b_fp8_e4m3fn.safetensors}]
[--model_dir MODEL_DIR]
[--skip_first_frames SKIP_FIRST_FRAMES]
[--load_cap LOAD_CAP]
[--output OUTPUT]
[--output_format {video,png}]
[--cuda_device CUDA_DEVICE]
[--preserve_vram]
[--debug]
options:
-h, --help show this help message and exit
--video_path VIDEO_PATH Path to input video file
--seed SEED Random seed for generation (default: 100)
--resolution RESOLUTION Target resolution width (default: 1072)
--batch_size BATCH_SIZE Number of frames per batch (default: 5)
--model Model to use (default: 3B FP8) in list:
seedvr2_ema_3b_fp16.safetensors,
seedvr2_ema_3b_fp8_e4m3fn.safetensors,
seedvr2_ema_7b_fp16.safetensors,
seedvr2_ema_7b_fp8_e4m3fn.safetensors
--model_dir MODEL_DIR Directory containing the model files (default: seedvr2_models)
--skip_first_frames SKIP_FIRST_FRAMES Skip the first frames during processing
--load_cap LOAD_CAP Maximum number of frames to load from video (default: load all)
--output OUTPUT Output video path (default: auto-generated)
--output_format {video,png} Output format: 'video' (mp4) or 'png' images (default: video)
--cuda_device CUDA_DEVICE CUDA device id(s). Single id (e.g., '0') or comma-separated list '0,1'for multi-GPU
--preserve_vram Enable VRAM preservation mode
--debug Enable debug logging
# Upscale 18 frames as png
python inference_cli.py --video_path "MAIN.mp4" --resolution 1072 --batch_size 9 --model seedvr2_ema_3b_fp8_e4m3fn.safetensors --model_dir ./models\SEEDVR2 --load_cap 18 --output "C:\Users\Emmanuel\Downloads\test_upscale" --output_format png --preserve_vram
# Upscale 1000 frames on 4 GPU, each GPU will receive 250 frames and will process them 50 by 50
python inference_cli.py --video_path "MAIN.mp4" --batch_size 50 --load_cap 1000 --output ".\outputs\test_upscale.mp4" --cuda_device 0,1,2,3
文章来自于“JackCui”,作者“JackCui”。


