# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在生成式 AI 时代,全球数据总量正以惊人速度增长,据 IDC 预测,2025 年将突破 180ZB,其中 80% 为非结构化内容,传统数据分析在应对多模态信息和打破结构化数据技术壁垒方面尽显乏力,“人工找数 + 手动分析” 的模式严重抑制甚至沉没了数据价值。与此同时,数据分析的传统体系从 ETL 到前端报表,虽解决了 “有报表看” 的问题,却在即时用数、用数闭环等场景中暴露出数据链路长、门槛高、决策行动滞后、实时性不足等结构性痛点。
在这样的背景下,TabTab.ai 选择从一个被巨头忽视、却蕴藏着巨大爆发潜力的赛道切入 —— 为用户提供全链路 Data Agent。不同于单一工具只关注公域数据的获取,TabTab.ai 围绕数据全链路(获取、准备、建模、洞察、可视化)构建了全栈自动化的 Multi-Agent 系统,能够按照自然语言意图自主规划、执行与校验,输出可维护、可追溯的结果。TabTab.ai 带来的价值在于重构人机交互模式,通过自然语言对话,把“结构化读写 + 自动推理”变成分钟级的闭环,使得数据能主动响应“数找人” 需求,彻底绕过分层建设的传统数据分析链路,迎来 Vibe Data Analysis 新范式,进而加速数据平权,实现人人皆分析师的愿景。
TabTab.ai 的创始人黄启功,是一位连续创业者,早年在 IBM 中国开发中心担任研发工程师,负责过 IBM WebSphere 中间件产品的研发,包括 IBM BPM、WebSpere Application Server 等,后来转战云原生,负责 IBM Bluemix PaaS 云平台的研发,当时黄启功敏锐地预判了云原生未来的发展前景,本着技术改变世界的热情毅然辞职创立了国内首家基于 Kubernetes 的容器云 PaaS 时速云,后来时速云的业务逐步延伸到云原生应用及数据平台,带着未竟的使命——“让计算产生价值 让数据成为资产”,时速云于2021年7月被全资收购。经历过云原生的完整创业周期,这次黄启功带着 TabTab.ai 重新归来。
在提及为何此时选择从 Data Agent 切入,黄启功谈到:
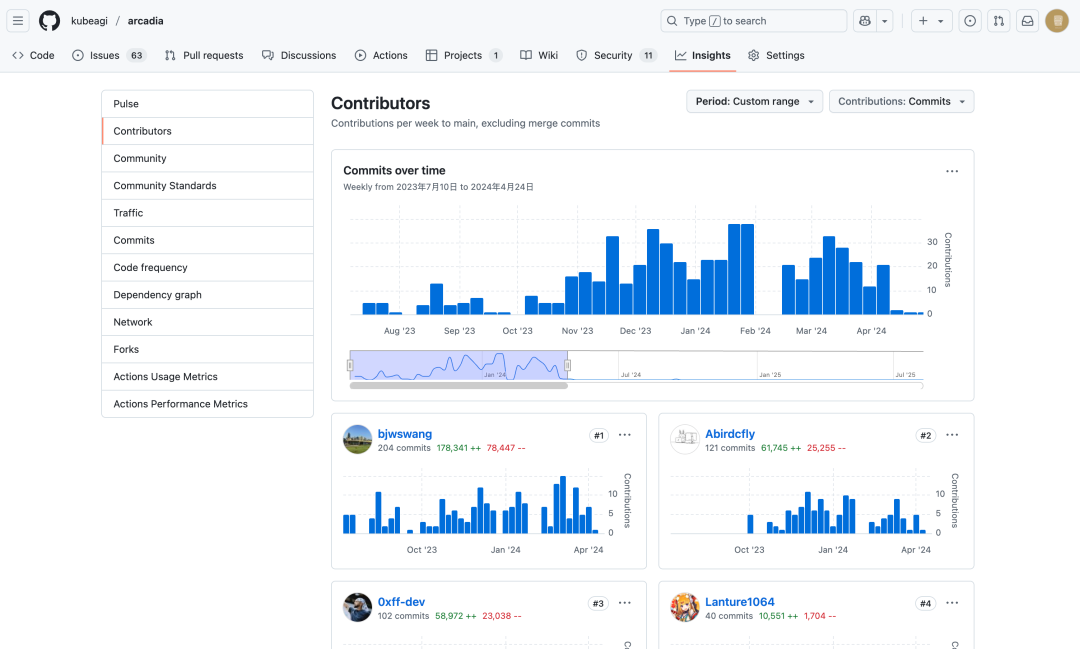
TabTab.ai 的早期技术团队来自于大模型开源项目 KubeAGI 的核心贡献者,KubeAGI 是一个基于云原生的大模型推理及运营管理平台,于2023年7月开源,为开发人员提供了一个统一的界面,通过智能体工作流编排引擎、RAG 检索增强生成和 LLM 推理及微调支持来构建、调试、部署和管理 AI Agent 应用。出于利他主义,开源 KubeAGI 为基于云原生 + Ray 的大模型分布式推理系统提供了一种思路,这比后来字节跳动开源的云原生大模型推理系统 AIBrix 早了将近一年半。
据 IDC 预测,2025年全球数据总量将突破180ZB,其中80%为非结构化内容,而传统数据分析在处理多模态信息(非结构化数据)时有诸多不足,另一方面,结构化数据则被层层封锁在技术壁垒之后 —— 从数据库、数据湖仓到数据中台,最终通过数据分析师加工成报表,且仅有少数决策者能以较高成本触及数据。在这种“人工找数+手动分析”的模式下,数据价值被抑制甚至沉没。
在这样的背景下,TabTab.ai 推出了首个全链路 Data Agent,让 Vibe Data Analysis 时刻到来。Vibe Data Analysis的核心在于数据分析场景下重构人机交互模式:通过自然语言对话,把“结构化读写 + 自动推理”变成分钟级的闭环,使得数据能主动响应“数找人” 需求,彻底绕过分层建设的传统数据分析链路。这一范式变革让数据分析从“工具插件”升级为“决策伙伴”,普通人员无需技术背景即可自动搜集、处理、分析数据并形成决策建议, Vibe Data Analysis 将加速数据平权,推动数据分析即生产力。
TabTab.ai 围绕数据全链路(获取、准备、建模、洞察、可视化)构建了全栈自动化的 Multi-Agent 系统,能够按照自然语言意图自主规划、执行与校验,输出可维护、可追溯的结果。TabTab.ai 全链路 Data Agent 主要在三个方面构筑竞争壁垒:
第一,Data Agent 的核心燃料 — 数据源,不同于 Chatbot 只关注通过 Deep Research 获取公域数据, TabTab.ai 一开始便重视多种数据源的建设,在支持针对公域数据的深度搜索基础上,还拓展了众多私域和垂直领域数据源。私域数据已支持多种数据库和文件格式,如飞书表格、飞书文档、MySQL、PostgreSQL、ClickHouse等;垂直领域数据源方面,TabTab.ai 已接入IT桔子创投数据、天眼查、巨量千川、万相台无界等。
第二,面向结构化数据的语义层构建,做到数据"100%准确,0幻觉",语义层构建负责将用户的业务知识、分析方法、指标体系和原始数据转化为大模型可理解、可执行的上下文。语义层构建之所以重要,是因为它能影响 Data Agent 的准确率,特别是对于已经是结构化数据的语义理解,通常准确率需达到90%甚至100%,一些特有的行业术语(如商品 SKU 的运营指标与语义体系)、个性化“黑话”都需要在语义层被精准理解和映射。TabTab.ai 语义层构建目前主要有两点:1)添加业务术语库,帮助 TabTab 更好地理解用户的需求;2)构建训练集,TabTab 能通过用户的点赞反馈,不断优化答案生成过程,提升回答质量。用户也可以直接添加训练数据,帮助 TabTab 更快地进行强化学习。
第三,Multi-Agent 智能多代理架构,数据分析的任务交付通常是复杂、多步骤的,单一 Agent 无法完成。需要将任务拆解为意图理解、任务规划、取数、分析、可视化、报告生成等,由不同的专业化 Agent 模块分工协作,并通过任务规划 Agent 高效调度其他 Agent。TabTab 的 Multi-Agent 智能多代理架构,涵盖了Plan Agent、Intent Agent、Deep Research、Algorithm Agent、Excel Agent、SQL Agent、Writer Agent、FE Agent等核心组件,以及若干子 Agent 和实用工具。TabTab 具备自主进化的意图识别和任务规划分发能力,支持主动/被动人工干预,较好均衡 AI 思考与人类决策。通过精准的上下文管理和记忆管理技术,在最低限度减少损耗的前提下,有效降低 Agent 交接过程中的上下文长度,延长感知时间范畴。
TabTab 面向的用户人群主要是超级个体、知识工作者和 SMB 客户,目前 SaaS 版已支持在线积分包充值,根据任务执行消耗的资源计费。针对行业 SMB 客户,正在探索与行业客户共创,按结果付费的模式,例如针对KOC营销场景,帮助用户提升了多少ROI,按收益结果分成。预计Q4会上线海外版。目前 TabTab 的典型案例场景包括:
1. 多源数据的搜集汇合与自动化处理
任务指令:帮我找下九合创投2025年以来新投资的创业公司,并找下被投企业的最新新闻,新闻不足3条的可以通过搜索深度查找下,数据保存为一个Excel,Excel中的第一个sheet为九合创投被投企业列表,每个被投企业的最新新闻单独一个sheet呈现。
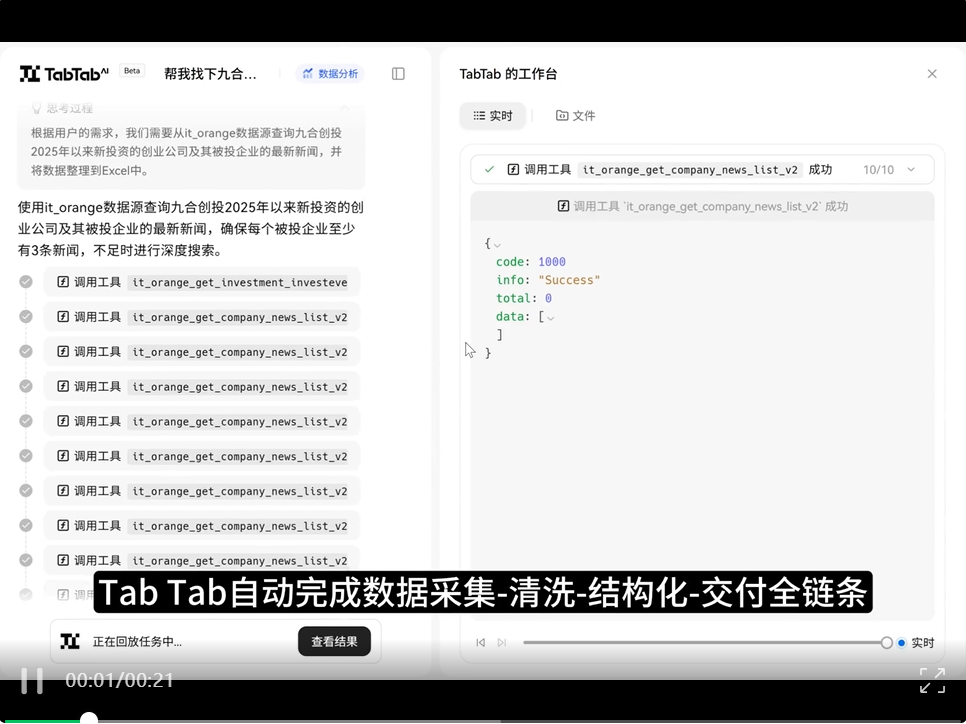
案例亮点:TabTab 自动完成数据采集 - 清洗 - 结构化 - 交付全链路,完成多源异构数据整合、智能搜索策略、Excel 自动操作等。通过模拟分析师的工作流,实现了从信息获取到商业洞察的全链路交付,为投资机构、行业研究人员提供高效的数据支撑工具。
2. 数据清洗与处理,自适应治理数据,懂规则更懂业务,还能与飞书表格联动
任务指令:获取 10 只主流基金数据(含基金代码、名称、类型、最新单位净值、近 1 月 / 3 月 / 1 年收益率、基金经理、成立时间、基金规模),并通过在线搜索补充这些基金的行业排名、用户好评率及近 3 年最大回撤;清洗数据(剔除重复条目、统一日期格式为 YYYY-MM-DD、将收益率转为百分比保留 2 位小数),新增 “风险等级”(按最大回撤分为 R1-R5)和 “性价比评分”(=(近 1 年收益率 ×0.6)-(最大回撤 ×0.4));将处理后的数据整理成一个 Excel,并写入到飞书多维表格中,多维表格名称为: “基金分析总表”
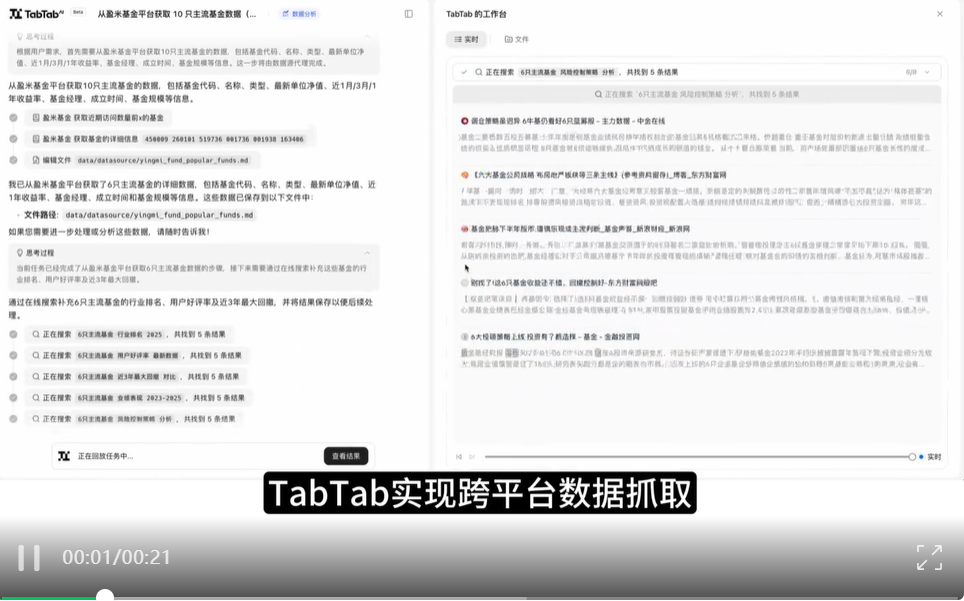
案例亮点:TabTab 可实现跨平台合规抓取数据,从多个权威平台获得基金基础数据,并对非结构化数据完成格式统一、单位转换、去重校验处理,完成风险量化与动态评估,并支持将数据同步到飞书多维表格。实现了从原始数据到决策依据的价值转化。
3. 无需编写 SQL,零门槛上手,支持自迭代的对话式数据库分析
任务指令:帮我分析下用户画像:1)用户的核心偏好品类、平均购买频率、客单价;2)对比新用户(登录≤30 天)与老用户(登录>180 天)的消费品类占比及促销敏感度;3)结合收入分层,看不同收入群体的消费力与复购原因。并且据此分析结果,帮助我为核心群体制定对应的营销策略
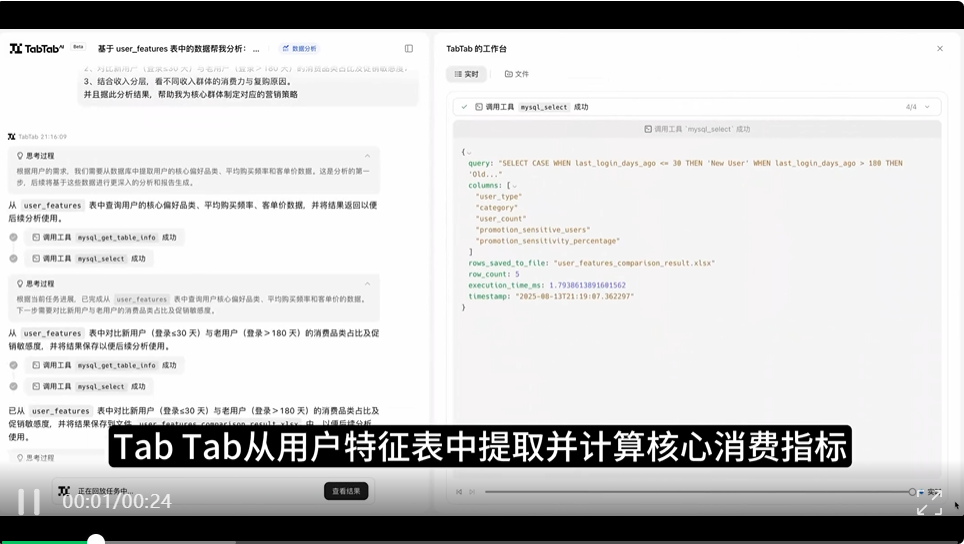
案例亮点:从 MySQL 用户特征表中自动提取并计算核心消费指标,结合收入分层挖掘不同收入群体的消费力及复购动因,将这些数据洞察转化为针对核心用户群体的精准营销策略,形成从数据提取、指标分析、群体对比到策略制定的完整闭环,助力基于用户行为与属性的精细化运营决策。
4. 分钟级实现数据处理和数据可视化
任务指令:我上传了一份宁德时代(300750)近一年的日线股票行情数据,请帮我分析其股价与成交量的整体走势和波动情况,并生成可视化分析报告。
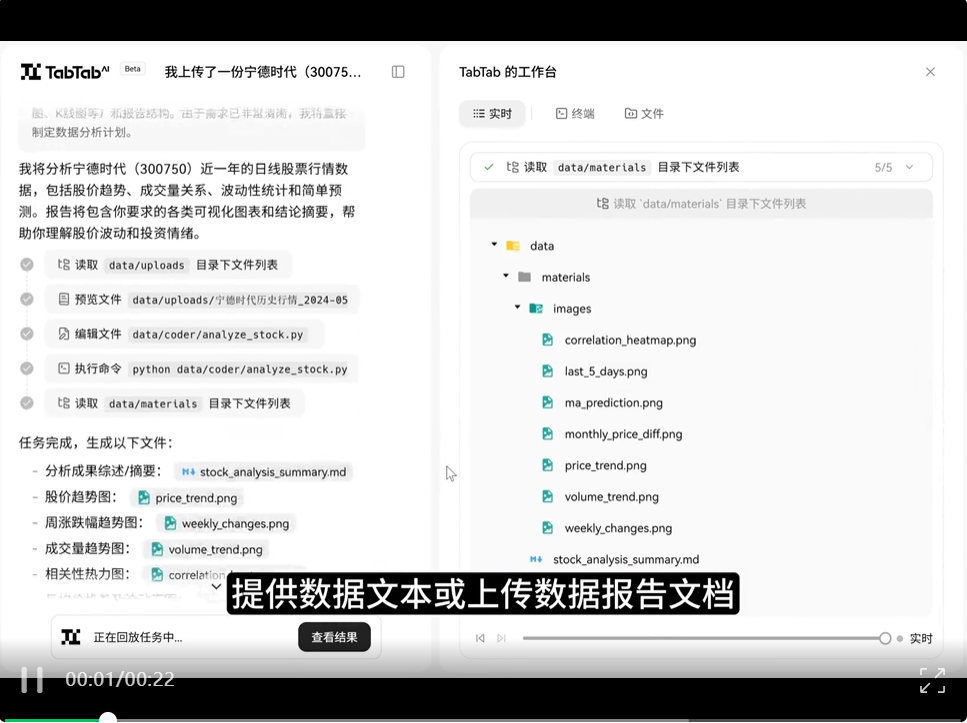
案例亮点:TabTab在分钟级自动整理关键数据,制作成精美的数据分析仪表盘,并以可视化报告形式呈现。支持饼图、条形图、极坐标图、散点图等丰富的展现形式,有效降低用户制作各类图表门槛。
5. 深度财务分析报告生成
任务指令:分析拼多多2024年年度财报和2024年Q4的财报
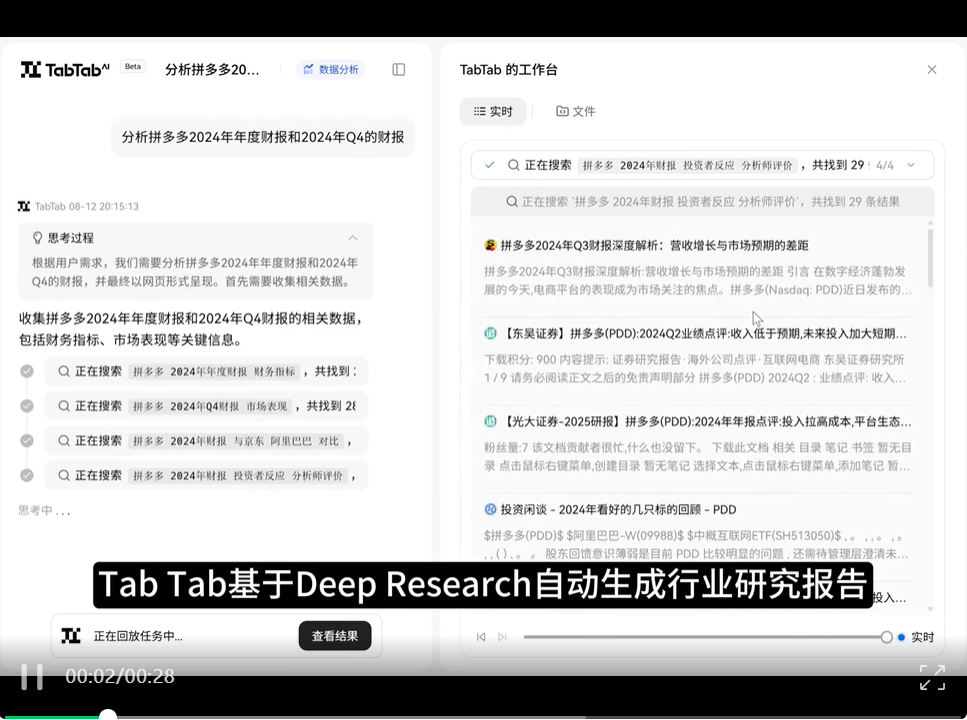
案例亮点:TabTab 基于深度搜索自动搜集并整理财务数据,并交付完整的财务分析报告等。完成从海量数据中提炼关键信息,进行自动趋势预测和数据可视化,并且能将复杂的分析结果以丰富的图表形式呈现。
传统数据分析中,数据生成环节往往被专业技术人员垄断 —— 从数据清洗、模型搭建到指标计算,每一步都需要掌握 SQL、Python 等编程语言,或是熟悉复杂的 BI 工具操作逻辑。这导致业务人员明明最了解实际需求,却因技术门槛无法直接参与数据创作,形成 “需求传递损耗” 与 “响应滞后” 的双重困境。
TabTab 通过全链路 Data Agent,将数据生成的权力交还给每一个人。用户无需编写代码,只需用日常语言描述需求(如 “请帮我分析近期的销量趋势,包括产品销售情况和增长数据”),TabTab 便能自动理解意图,进行多源数据搜集与处理、执行分析算法、 深度洞察、数据可视化,在数十分钟内生成结构化数据、分析报告、精美网页和幻灯片内容。
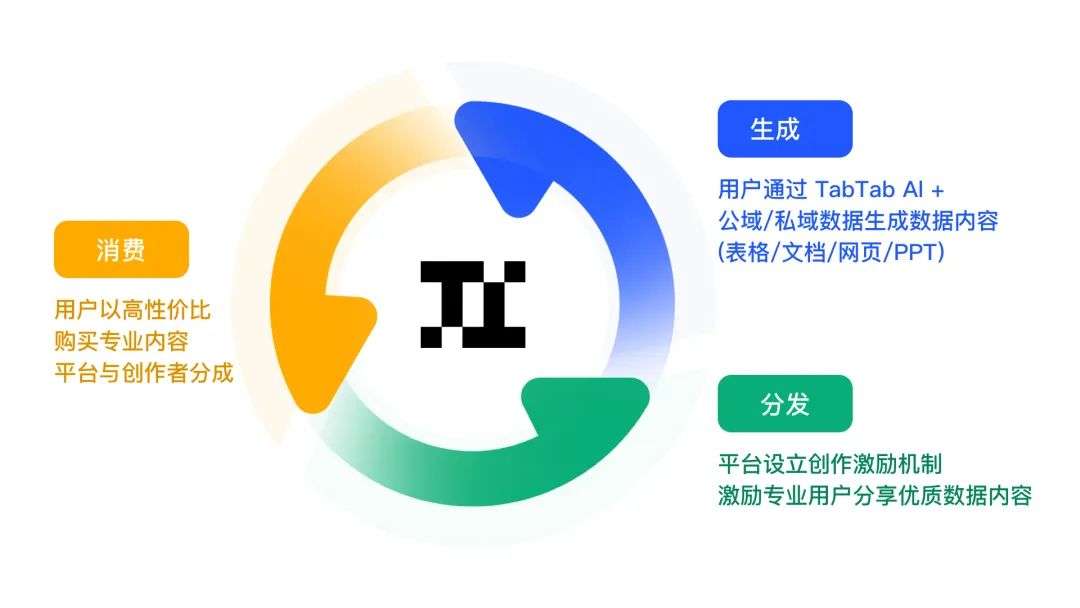
TabTab 将打造“生成 - 分发 - 消费”的数据飞轮:在生成端,用技术降低数据创作的门槛,释放全民数据生产力;在分发端,TabTab 将设立创作激励机制,激励专业用户分享优质数据内容;在消费端,用户以高性价比购买专业数据内容报告,不用苦想提示词。
这一模式的核心价值,在于实现数据平权—— 让数据不再是少数分析师的 “专业工具”,而是每个用户都能轻松驾驭的 “决策利器”。当每个人都能通过 Data Agent 生成数据、获取数据、运用数据时,数据才能真正成为驱动业务增长的 “燃料”,助力用户在数字化时代构建起不可替代的竞争优势。
不同于其他 AI 创业者一开始就定位海外市场,以规避国内激烈的内卷竞争,TabTab 团队在结合自身的优势,经过深思熟虑后,决定先在本土做出产品 MVP,跑通 PLG 模式(Product Lead Growth),形成可迁移的积累效应后,再把国内的成功模式复制到海外。诚然,团队深刻意识到快速迭代的重要性,在历时 7 个月研发出 TabTab 国内版后,预计3个月内将推出海外版,因为除了用户账号、支付体系、数据源等差异外,底层技术绝大部分能直接复用。
在 GTM 层面,TabTab 团队对于国内 B 端市场驾轻就熟,要突破的地方是如何做出标准化、订阅式以及渠道化的产品,这样才能建立可持续增长的商业模式;面向海外市场,将主打超级个体和知识工作者等用户群体,同时加紧储备相关人才。
全球化是中国新一代企业的主旋律,条条道路通罗马,不盲目跟随,有自己的节奏方能行稳致远。
TabTab.ai 产品已于近日上线,此前已完成百万美金级种子轮融资。TabTab.ai 正在竭诚招聘大模型算法、开发、产品、市场、海外增长负责人,对于前100位成员创始人都会 1v1 直聊。此刻,你是否因为我们的愿景而躁动,与其仰望星空,不如一起点亮它——加入我们,让你的才华成为改变世界的光!
文章来自于微信公众号“Z Potentials”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
