# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着内容创作智能化需求的爆发,长时长、高质量数字人视频生成始终是行业痛点。近日,字节跳动商业化 GenAI 团队联合浙江大学推出商用级长时序音频驱动人物视频生成模型 ——InfinityHuman,打破传统音频驱动技术在长视频场景中的局限性,开启 AI 数字人实用化新征程。
只需提供一张人物图像与对应音频素材,InfinityHuman 就能自动生成连贯自然的高分辨率长视频:无论是 30 秒的产品快推、还是 3 分钟的演讲致辞,均能实现专业级呈现。技术团队演示中,仅凭一段音频即可让电影中的人物复活 " 为动态数字人,视频效果生动自然,肢体动作与语音节奏高度同步。

该图由 AI 生成
InfinityHuman 的关键优势在于创造性解决了长期动画中的两大核心难题:
从项目主页展示的案例来看,InfinityHuman 已实现多场景商用级应用:
尤其值得关注的是,该模型对中文语音的支持效果尤为出色,在分钟级长视频中仍能保持身份稳定与手部动作自然,充分满足中文内容创作需求。



如需了解更多技术细节和效果演示,可访问:

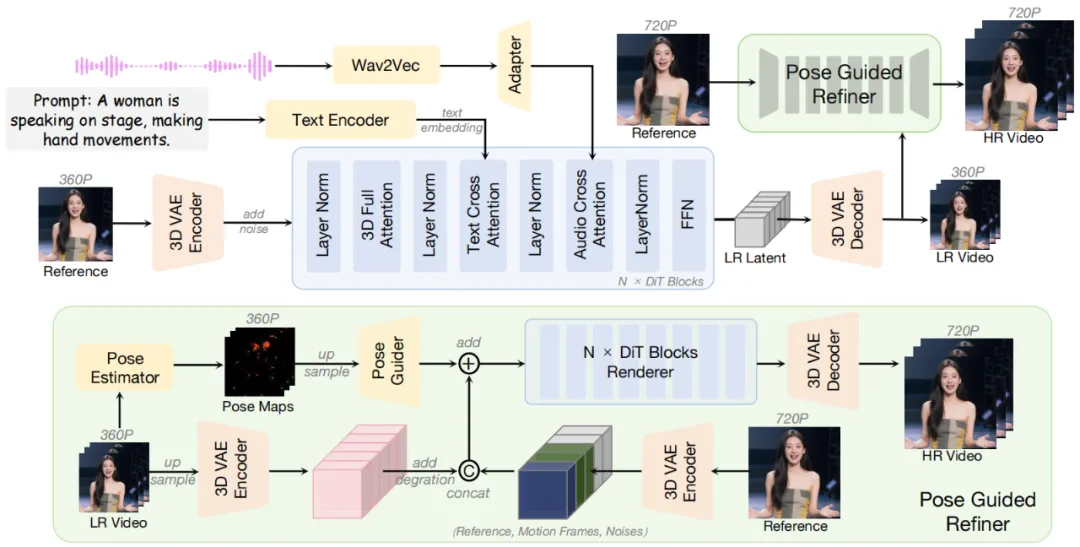
如图所示,InfinityHuman 是一个统一框架,旨在通过单张参考图像、音频和可选文本提示生成长时间、全身的高分辨率说话视频,确保视觉一致性、精准唇同步和自然手部动作。该框架采用 “由粗到细” 策略:先通过低分辨率音视频生成模块得到含粗略动作的低分辨率视频,再由姿态引导细化模块结合低分辨率视频和参考图像生成高分辨率视频,同时引入手部校正策略提升手部动作的真实感与结构完整性。
低分辨率音视频生成模块基于 Flow Matching 和 DIT,融合参考图像、文本、音频等多模态信息,通过多模态条件注意力机制增强音频与视觉的对齐;姿态引导细化模块利用参考图像作为身份先验,结合低分辨率视频及其姿态序列,通过前缀潜变量参考策略和姿态引导确保长时生成中的时序连贯性与外观一致性;手部特定奖励反馈学习则针对手部易出现的畸变问题,利用预训练奖励模型进行偏好微调,提升手部结构的合理性与真实感。
实验结果表明,InfinityHuman 在音频驱动全身说话视频生成任务中表现优异。在 EMTD 和 HDTF 数据集上的评估显示,该方法在视觉真实感(FID)和时序连贯性(FVD)指标上均优于 FantasyTalking、Hallo3 等主流基线方法,生成视频的整体质量显著提升。身份一致性方面,通过姿态引导细化模块有效维持了与参考图像的相似度,解决了长时生成中的外观漂移问题。针对手部生成这一难点,手部特定奖励反馈学习显著提升了手部关键点的准确性,减少了手指畸变、关节异常等常见问题,尤其在复杂手势场景中表现稳定。
消融实验进一步验证了核心模块的有效性:移除姿态引导细化模块会导致视觉质量下降、身份一致性减弱,视觉细节模糊且时序连贯性降低;取消手部奖励机制则使手部关键点精度下降,手部失真现象明显增多。
综合定量指标和定性分析,InfinityHuman 在高分辨率、长时长视频生成任务中实现了真实感、一致性与动作自然度的全面提升。

作为字节跳动旗下专注于音视频数字人生成的研发力量,商业化 GenAI 的 VIVID(Voice Integrated Video Immersive Digital)Avatar 团队始终站在技术前沿,致力于突破音频与视觉融合的技术边界。团队以 “让数字人更鲜活、更实用” 为目标,在语音合成与视频生成两大方向持续深耕,形成了从基础研究到商业化落地的完整技术链路。
语音合成方向,团队推出 MegaTTS3、Make-An-Audio 2 等模型,视频生成领域,从长视频模型 HumanDiT、NeurIPS 2024 收录的 MimicTalk 个性化 3D 建模,到 ICLR 2024 Spotlight 成果 Real3D-Portrait 单样本 3D 合成,再到 DiTalker 等音频驱动方案,构建了覆盖长视频、3D 肖像、实时驱动的完整技术矩阵。目前,团队已通过 GitHub 开源平台(https://github.com/VIVID-Avatar/)分享多项核心技术,并将最新研发的长时序音频驱动视频生成模型 InfinityHuman 部署至商业化即创平台,让前沿技术从实验室快速走向产业应用,为内容创作、教育培训、电商直播等领域提供低成本、高质量的数字人解决方案。
文章来自于微信公众号“机器之心”



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
