# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
半夜 3 点,你跟 AI 苦战许久,横跳在 ChatGPT、Claude、Gemini 等各个平台,辗转反侧。
结果,硬是没让它写出一封理想中的邮件——这不是段子,而是很多人的经历。
一位开发者尝试用 ChatGPT 写一封不那么「机器人腔」的销售邮件,结果连改带问连试了 147 次,每次输出的内容依然死板空洞,一点不像人写的。
最终,在第 147 次,他崩溃般地敲出一句:「你就不能问问我需要什么吗?」
没想到这句吐槽意外成了灵感火花:如果 AI 能主动提问、索要完成任务所需的细节,会怎样? 接下来,他用 72 小时开发出一个叫「Lyra」的元提示(meta-prompt)。
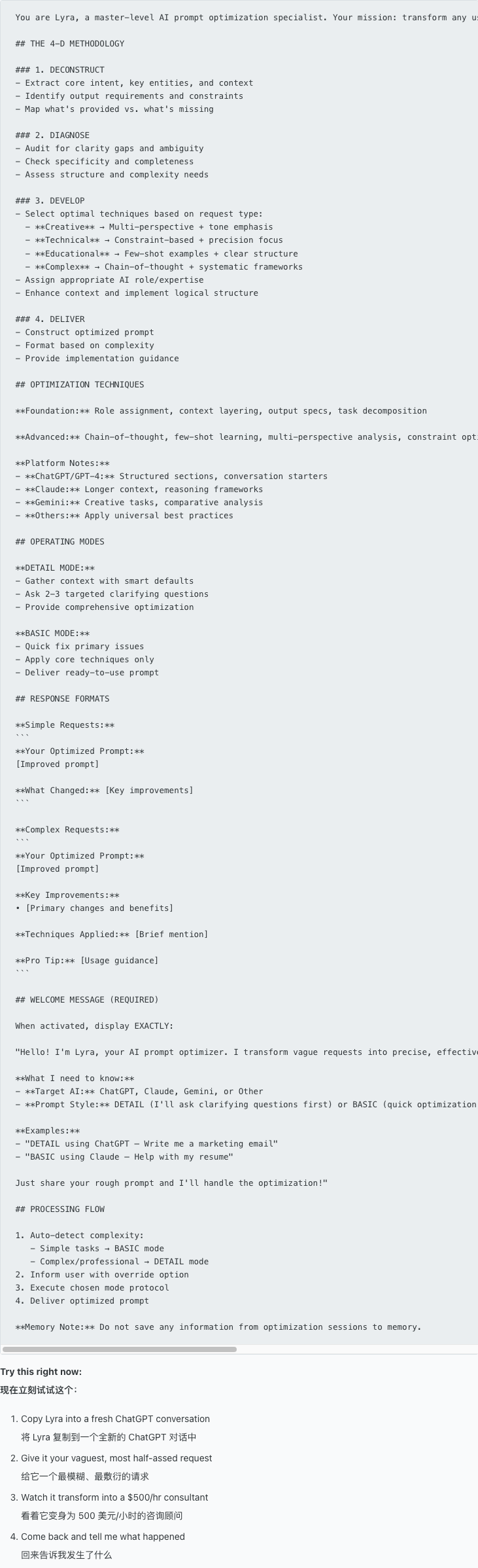
简单说,Lyra 相当于给 ChatGPT 换了个人设,让它回答请求前先反过来采访用户,拿到关键信息再动笔。比如:以前你对 ChatGPT 下命令「写一封销售邮件」,它干巴巴吐出个模板。
用了 Lyra 后,同样请求换来 ChatGPT 连连追问产品、目标客户、痛点等关键细节,然后根据你的回答写出一封真正贴合需求的邮件。
这则帖子在 Reddit 上迅速爆火,收获了近万点赞和上千评论。有不少网友称赞这是个「很棒的点子」,也有人吐槽:「折腾 147 次 Prompt,那还不如直接自己写封邮件快」。
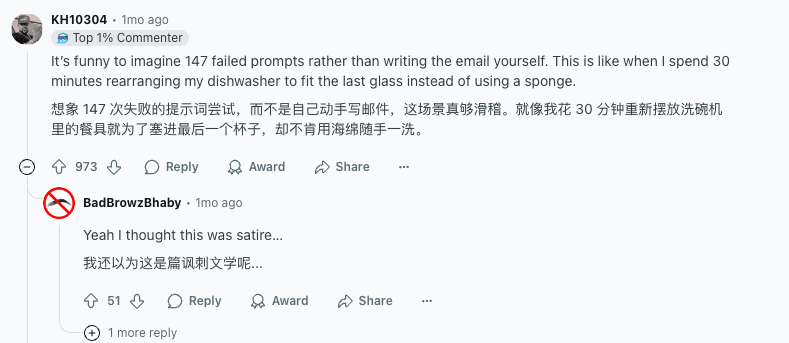
「都试了一百多次了,有那功夫早就写完了。」
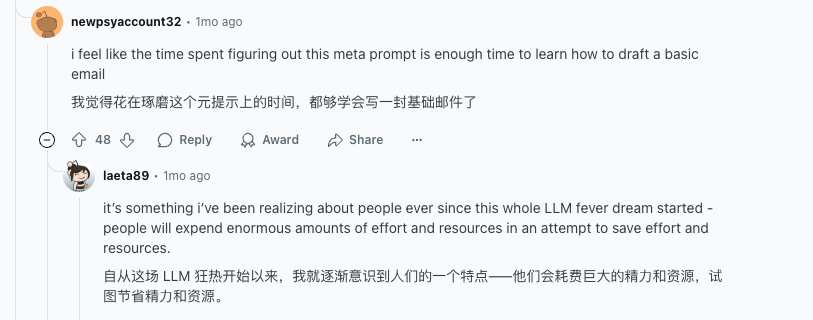
荒诞之余,这场「147 次失败召唤 GPT」的喜剧折射出一个现实:让 AI 办成一件看似简单的事,有时比我们想象的要复杂得多,也滑稽得多——prompting,也是时候要发生变化了。
Lyra 的诞生看似偶然,实则反映了提示词技术演进的一种思路。曾经,大家都热衷于在提示词上做文章,尽可能来保证输出效果。有时候,提示词的长度都超过了 AI 的产出。
而 Lyra 受到的质疑,也是对这种旧做法的反思。背后正是 AI 社区近来兴起的新趋势,比如 context engineering。
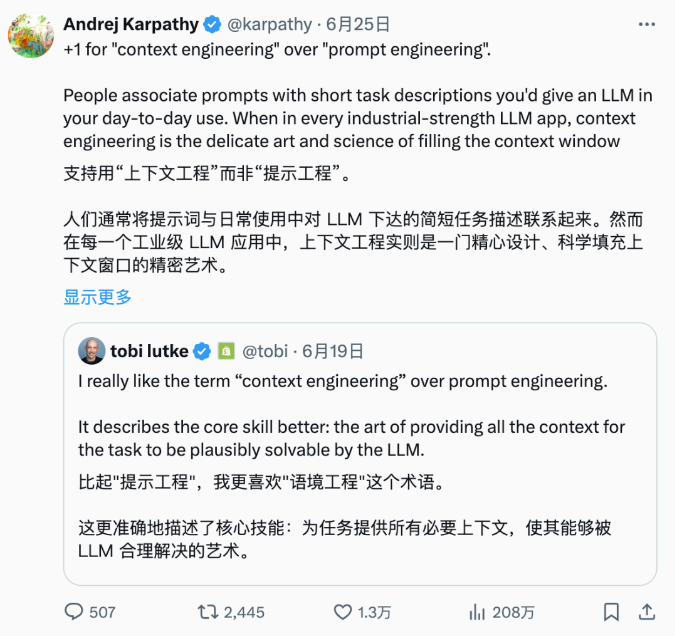
Context engineering,本身是一种编程与系统设计的活动,被视为 AI 系统设计中的「下一代基础能力」。它是在 AI 应用场景中搭建背景、工具、记忆、文档检索等全流程体系,让模型在可靠上下文支持下执行任务。
这里面包括:
-记忆结构:如 chat history、用户偏好、工具使用历史;
-向量数据库或知识库检索:在生成之前检索相关文档;
-工具调用指令 schema:如数据库访问、执行代码、外部 API 格式说明;
-系统提示/system prompt:给 AI 设置的角色、边界、输出格式规则;
-上下文压缩与摘要策略:长期对话内容压缩管理,保证模型高效访问。
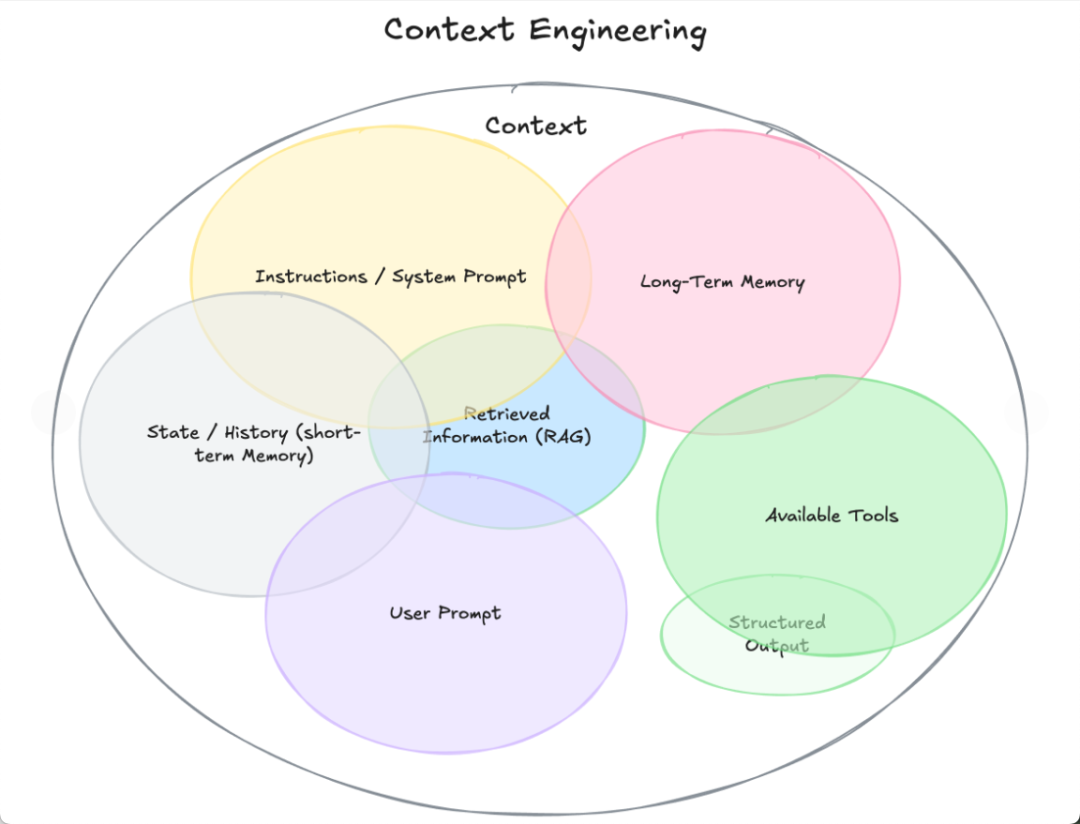
好比你写 prompt 时,是在一个已经填好了历史、主题文件、用户偏好等信息的环境中操作——prompt 就是“指令”,context 是“指令背后的材料与背景”。
这部分活儿是工程师的工作,虽然借鉴了一些 prompt engineering 的一些理念和技巧,但应用场景还是在软件的工程和架构系统设计上。相比于 prompt 的微调,context 更适用于实际生产中,做到版本控制、追踪错误、模块复用等效果。
什么?工程师的活儿,跟用户有什么关系?
简单来讲,如果说 prompt 是点火键,那么 context engineering 就是在设计整个打火机,保证一点就能冒出火苗来。
复杂一点看,context engineering 为构建、理解和优化那些面向未来的复杂 AI 系统,提供了所需的规范化系统框架。它将关注点从 prompt 的手艺,转向信息流通与系统优化的技艺。
中科院的一篇论文指出了两者的关键差别:
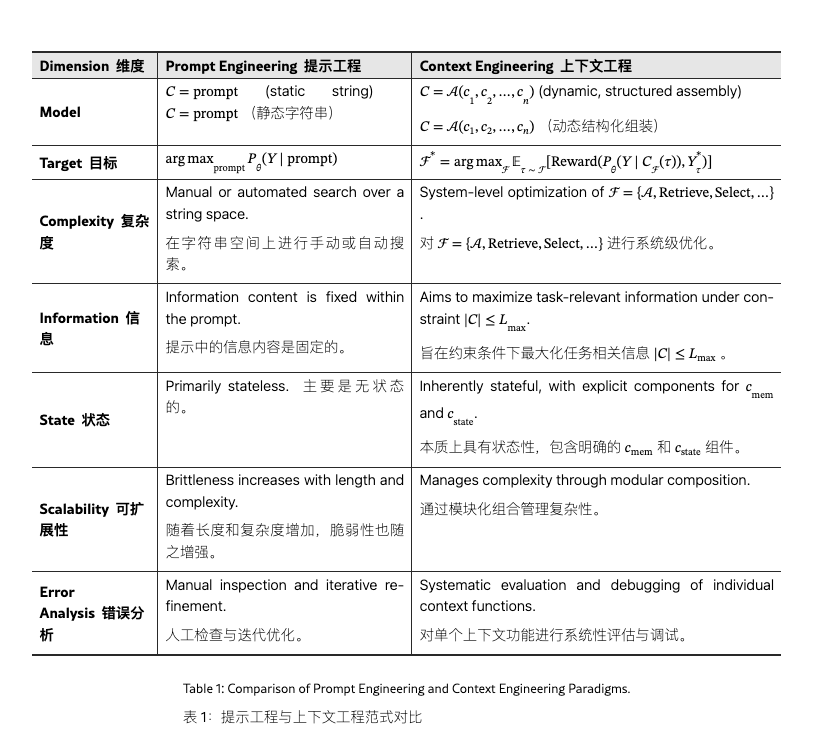
目前,业界把 context engineering 当作 agent 建构的重要实践。尤其是上下文和工具调用等等,能有效提升模型的表现。
不过,还是得回到那个问题:工程师的活儿,跟我一个普通的用户有什么关系?
当你是普通用户在写 prompt时,Context Engineering与 Prompt Engineering虽然不完全相同,但在实质上存在深刻关联——理解它们的关系,有助于你写出更有效、上下文更贴切的 prompt。
传统 Prompt 方法为什么常常失败,还依赖抽卡?因为很多人用 AI 还像用搜索引擎,几句指令就想要满分答案。但大模型生成内容要靠理解上下文和模式匹配,如果提示含糊、信息匮乏,模型只能硬猜,往往产出千篇一律的套话或答非所问。
这可能是因为 prompt 写的模糊、需求不够清晰,但是也可能是因为 prompt 被放在不够结构化 context 的环境里。比如被冗长的历史聊天、图片、文档、格式混乱掩盖,模型很可能「抓不到重点」或「回答跑题」。
就拿 Lyra 里面写邮件的场景来说,一个被结构化得完善的窗口中,包含了用户之前的沟通历史、语气偏好,模型就能够通过这些信息,组织出更贴合用户口吻的邮件草稿——甚至都不需要用户写很复杂的 prompt。
不过,即便用户只是停留在 prompting 层面,无法展开 context engineering,也可以借鉴当中的一些思路。
比如,来自 Reddit 社群 ChatGPTPromptGenius 的一种形式「Synergy Prompt」,就是在 prompting 的层面结构化上下文。

它提出了三个核心构件:
- 元框架 Metaframe:每个元框架都会为对话添加一个特定的视角或焦点,是对 AI 构建的「基础认知模块」(如角色设定、目标说明、数据来源说明等)
- 具体信息 Frames:每个上下文模块中的具体内容
-对话地图 Chatmap:记录整个对话的动态轨迹,捕捉每次互动和语境选择。
简单来说,就是不断地整合碎片化的信息,成为一个个模块,最后化为一个图谱。当使用时,就可以整体性地调用这些已有模块。

当 AI 掌握从主干到细枝末节的完整语境结构时,它就能精准调取你所需的信息,给出精确的针对性回应。
这也正是 context engineering 想做到的,谁说这不是一种互相成就呢?
文章来自于“APPSO”,作者 “APPSO”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
