# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是袋鼠帝。
最近我在折腾本地AI知识库的时候,在Github发现了一个特别有意思的新项目,叫seekdb。
它是一款开源的AI原生混合搜索数据库。
https://github.com/oceanbase/seekdb

seekdb的配置要求,低到离谱,最低只需要1核CPU,2GB内存,就能跑起来。
它是All In One的AI原生数据库,一个库包圆了向量、文本、结构化/半结构化数据。
PS:也就是既可以做向量数据库(实现RAG),又能存储业务数据(传统关系型数据库)非常全能~
还支持 MySQL协议,Navicat直接连(Navicat是一款非常经典的数据库可视化管理工具)

还能当MCP Server用,可以接入Trae、Claude Code、Cursor等任何支持MCP的工具或平台。

另外,还可以接入Dify,不是当作外部知识库接入哦,是可以直接掌管Dify的元数据和AI知识库,因为Dify官方的最新版本在底层对它做了兼容。
当下大多数团队在真正落地Agentic RAG应用的时候,或多或少应该都会遇到一个问题:底层数据架构过于复杂。
为了让检索足够精准,通常需要处理三种完全不同的数据形态:
一是业务元数据,比如Agent的创建时间、作者、权限,工作流的各种节点数据。这需要关系型数据库来存,因为它要求绝对的事务安全。
二是语义向量,这是把文字变成数学向量,让AI能理解语义。这需要向量数据库来存。
三是全文检索,也就是关键词匹配,因为有时候向量搜索会想太多、或者理解有偏差,反而搜不到一些具体的专有名词,这时候就需要传统的全文检索来兜底。
在过去,为了实现这三者的混合搜索(Hybrid Search),不得不采用一种拼图式的分布式架构:比如装一个MySQL或PostgreSQL存元数据,再装一个Milvus或Chroma存向量,为了搜得准,甚至还得再挂一个Elasticsearch做全文检索。
你得维护三套完全不同的成熟系统,还要自己处理它们之间的数据同步。最要命的是,这种跨系统的写入,很难保证事务一致性。比如网络一抖动,向量库写入失败了,但元数据写入成功了,你的知识库就精分了,一边告诉你文档在,一边又搜不到内容。
系统越复杂,人力投入就越大,风险越高..
但seekdb的思路非常清晰,就做减法:把向量、文本、结构化/半结构化数据,全部塞进了一个数据库里。
这意味着,你不需要再去维护那一堆乱七八糟的中间件了
一个seekdb,全搞定。
它的核心能力也是混合搜索。

seekdb直接在数据库内核层面,支持了向量、全文和标量过滤的混合查询。一条SQL语句,就能完成多路召回和精排。
它还内置了AI函数:

你可以在数据库里,直接调用大模型或者向量模型,完成数据的嵌入和推理。
这就是,AI原生数据库,自己带了个脑子
这是seekdb和其他开源数据库的对比
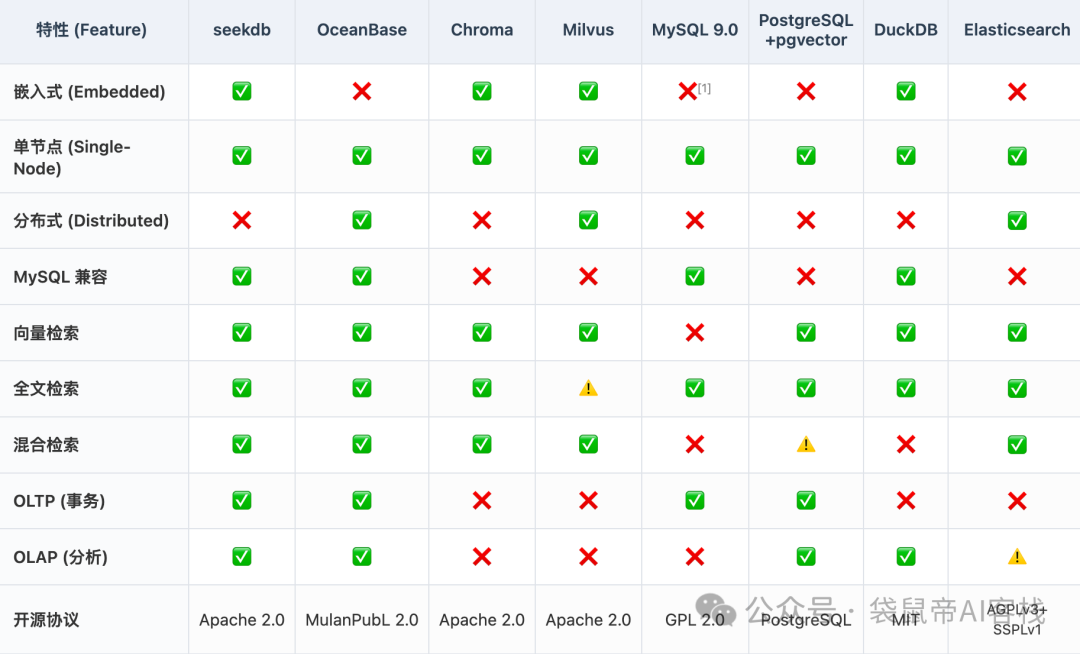
我觉得,这玩意儿特别适合几个场景:
一个是个人或者小团队的本地知识库。因为它轻量,资源占用少,随便找台旧电脑或者便宜的云服务器就能跑。
另一个是边缘设备上的AI应用。比如手机,车机,或者工业网关,这些设备的资源有限,跑不动那些重型数据库,但seekdb这种轻量级架构,正好能派上用场。
当然,还有就是作为Agent的记忆体。它能同时存储结构化的对话记录和非结构化的向量记忆,非常适合用来给AI Agent做长期记忆。
好了,话不多说,我们直接上实操!
部署seekdb,简单得让我有点不适应。
如果你习惯用Python,直接pip安装就行。
pip install pyseekdb
如果你想用Docker,也是一行命令的事。
docker run -d --name seekdb -p 2881:2881 oceanbase/seekdb:latest
启动速度非常快,几乎是秒级。
安装好之后,你可以用Python SDK来操作,也可以直接用MySQL客户端(比如Navicat)连接。
Dify虽然好用,但它的开源版在做AI知识库这块,检索效果确实有点差强人意。
而且Dify的默认元数据库(PostgreSQL)和向量数据库(Weaviate)是分开的,相比seekdb有以下不足:

seekdb通过粗排 + 精排机制,能保持毫秒级响应,支持百亿级向量检索。
现在最新的Dify v1.10.1正式兼容了MySQL数据库
这意味着我们可以把Dify的元数据库(存储业务数据)和向量数据库,都切换成seekdb(因为它支持MySQL协议)。
看能不能提升一下Dify的知识库效果
需要做两个地方的改动:
一个是在Dify的docker/docker-compose.yaml文件里,把api、worker、worker_beat、web服务的image版本号改为1.10.1,或main
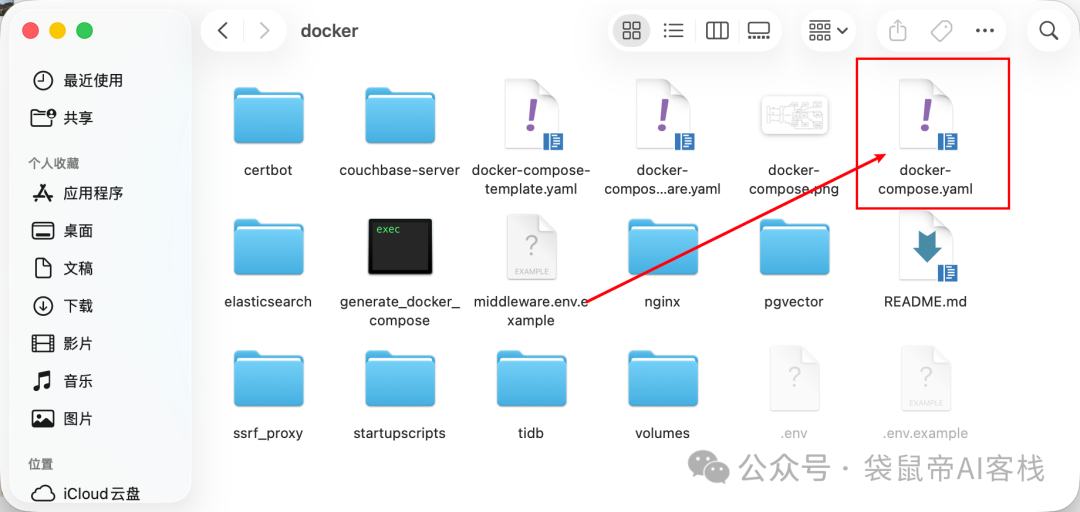
比如langgenius/dify-api:1.10.1
或者langgenius/dify-api:main
第二个改动是把dify/docker下的.env.example 复制出来,改名为.env

不过在文件夹里面,这两个文件都是隐藏文件,正常是看不到的。
Mac查看隐藏文件的快捷键 command+shift+.
Windows快捷键是ctrl+shift+h

在.env里面修改几个配置
如果既作为元数据库又是向量数据库的话,修改以下配置
DB_TYPE=mysql
DB_USERNAME=root
DB_HOST=seekdb
DB_PORT=2881
DB_DATABASE=test
VECTOR_STORE=oceanbase
OCEANBASE_VECTOR_HOST=seekdb
OCEANBASE_VECTOR_USER=root
COMPOSE_PROFILES=seekdb
如果仅作为元数据库,只需要改下面这些:
DB_TYPE=mysql
DB_USERNAME=root
DB_HOST=seekdb
DB_PORT=2881
DB_DATABASE=test
COMPOSE_PROFILES=${VECTOR_STORE:-weaviate},seekdb
如果仅作为向量数据库(只替换知识库功能),只改下面这些配置:
VECTOR_STORE=oceanbase
OCEANBASE_VECTOR_HOST=seekdb
OCEANBASE_VECTOR_USER=root
COMPOSE_PROFILES=seekdb,${DB_TYPE:-postgresql}
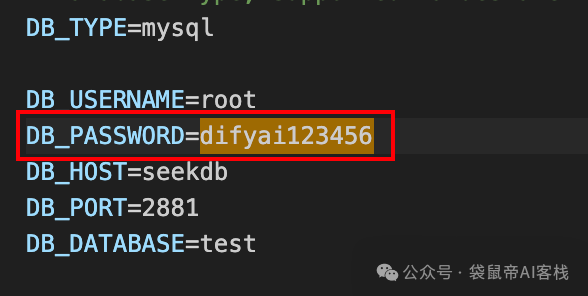
启动之后,dify会帮seekdb设置一个默认密码:difyai123456
PS:这个密码也可以在.env文件里面修改
做完上面这些之后,执行docker-compose up -d重新拉取新镜像,同时也会自动重启服务。
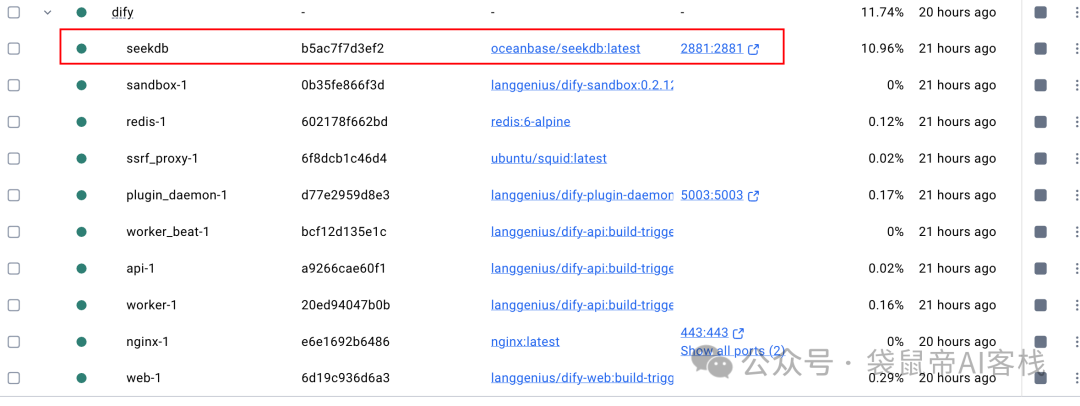
启动之后,seekdb就会同时扮演元数据库、向量数据库和全文检索系统的角色
然后我把最近在公众号发布的一些文章通过Dify打造了一个知识库

在seekdb里面找到vector_index开头的表,可以看到,已经有对应的向量数据存储进来了。

接入GLM-4.6做了一些知识库搜索的测试,感觉效果还是不错的:



seekdb还提供了MCP-Server。
我们可以把它接入本地的Trae、Cursor、Claude Code等工具,作为一个本地Agent的知识库工具,给Agent补充一些私有的专业知识,或者让它记住你的偏好。
接入步骤也很简单,分为两步,不过需要先满足以下前置条件:
1.已经在本地部署seekdb;
2.本地Python版本在3.11或以上;
3.需要安装Python包管理器uv:pip install uv,安装完成后执行uv --version验证是否安装成功。
然后第一步:安装OceanBase MCP Server
1.克隆项目到本地(也可以去Github下载zip包):
git clone https://github.com/oceanbase/mcp-oceanbase.git
2.进入源代码目录:
cd mcp-oceanbase
3.安装依赖:
uv venv
source .venv/bin/activate
uv pip install
第二步:接入本地Agent,比如Trae
在Trae里面配置seekdb的MCP-Server

{
"mcpServers": {
"oceanbase": {
"command": "uv",
"args": [
"--directory",
"/path/to/your/mcp-oceanbase/src/oceanbase_mcp_server",
"run",
"oceanbase_mcp_server"
],
"env": {
"OB_HOST": "127.0.0.1",
"OB_PORT": "2881",
"OB_USER": "root",
"OB_PASSWORD": "difyai123456",
"OB_DATABASE": "test"
}
}
}
}
注意:路径替换成自己的oceanbase_mcp_server绝对路径
第一次启动的时候,会下载MySQL相关驱动,有点慢。
成功后,如下图,有10个工具

1. execute_sql:在 OceanBase 服务器上执行任意 SQL 语句。
2. get_ob_ash_report:生成 OceanBase 的 ASH(活跃会话历史)报告,用于性能分析,可指定起止时间和租户。
3. get_current_time:获取 OceanBase 的当前系统时间。
4. get_current_tenant:获取当前连接会话所属的 tenant(租户)名称。
5. get_all_server_nodes:列出 OceanBase 集群中所有 server 节点(需要 sys 租户权限)。
6. get_resource_capacity:获取集群资源(CPU/内存等)容量信息(需要 sys 租户权限)。
7. search_oceanbase_document:基于关键字从 OceanBase 官方文档里自动检索相关内容,为 LLM 提供上下文知识。
8. oceanbase_text_search:在 OceanBase 表里做全文检索,可指定文本列、搜索词、WHERE 条件和返回列。
9. oceabase_vector_search:对表中的向量列执行向量相似度搜索,可指定距离算法、是否返回距离、TopK 等。
10. oceanbase_hybrid_search:同时结合「结构化过滤(如年龄>20)」和「向量相似度」进行多模态混合搜索。
OceanBase MCP的使用方式还是有挺多的,我给大家展示两种:
一种是传统数据库的增删改查:
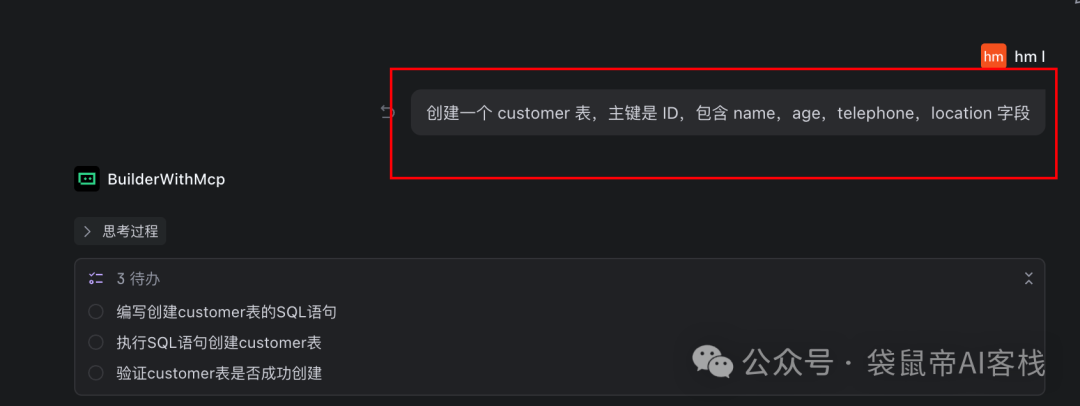
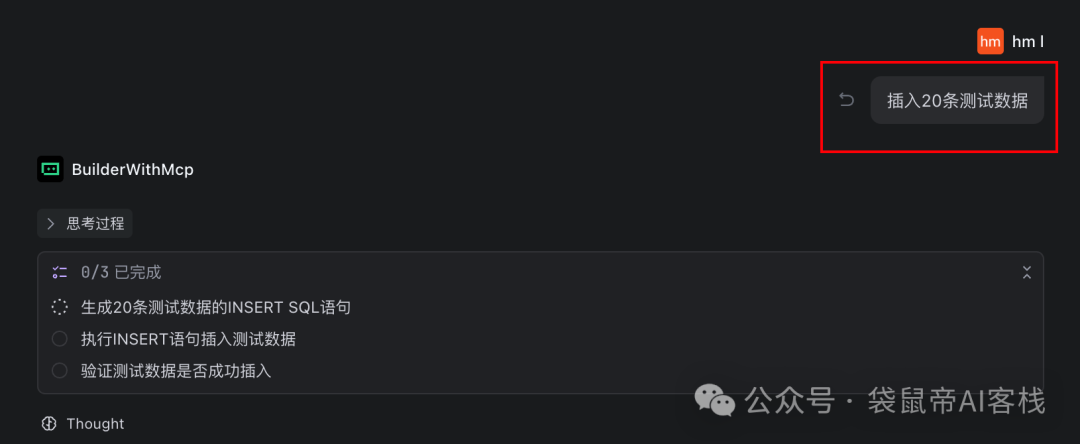
另外一种是混合检索(全文检索+语义检索)。
不过AI并不清楚混合检索的sql语句,所以需要给上下文(也就是sql示例,我这里写在了输入框,后续可以放到Trae的规则,或者作为一个文件,放在当前文件夹下)
sql示例可以在seekdb官方文档找到:
https://www.oceanbase.ai/docs/zh-CN/
向量表的表名也得给对(可以去navicat里面找vector_index开头的)
这里的提问:搜索一下PaddleOCR-VL是什么

这样AI就能通过OceanBase MCP进行语义搜索,找到我通过Dify向量化存储到seekdb的PaddleOCR-VL文章的相关信息,并整理回答。


更多信息可以在seekdb官方文档里面查看:
https://www.oceanbase.ai/docs/zh-CN/
我感觉,数据库这个行业,终于也开始被AI重塑了。
过去,我们为了适应数据库,不得不把数据拆开,去适应不同的存储引擎。
现在,seekdb把向量、文本、结构化数据重新融合在了一起,用一种更符合AI的使用方式,来存储和检索数据。
而且能无缝兼容MySQL协议,意味着很容易迁移/切换
我查了一下seekdb,还是蚂蚁旗下的OceanBase团队开源的项目
如果你正在为AI项目的数据架构头疼,或者只是想在本地快速搭个好用的知识库,可以去试试这款全新的AI数据库--seekdb
文章来自于“袋鼠帝AI客栈”,作者 “袋鼠帝”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
