# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
中美正忙着堆算力打AI战,欧洲却突然杀出一条血路:模型落地更重要!Mistral一口气扔出Large 3和Ministral 3,全开源、能看图、能跑在大多数电子设备上,甚至断网也能用。未来,AI是巨头的专属权力,还是人人都能握在手中的智能?这一次,欧洲给出了自己的答案。
就在昨天,「欧洲版DeepSeek」一口气公布了两件事:
全部开源、全部多模态、全部能落地。

这次Mistral推出的Mistral Large 3,规格上看几乎是「开源界的准天花板」:
41B active / 675B total的MoE架构、原生图像理解、256k context、多语言能力在非英中语种上强得离谱,LMArena排名直接杀到开源模型第6。
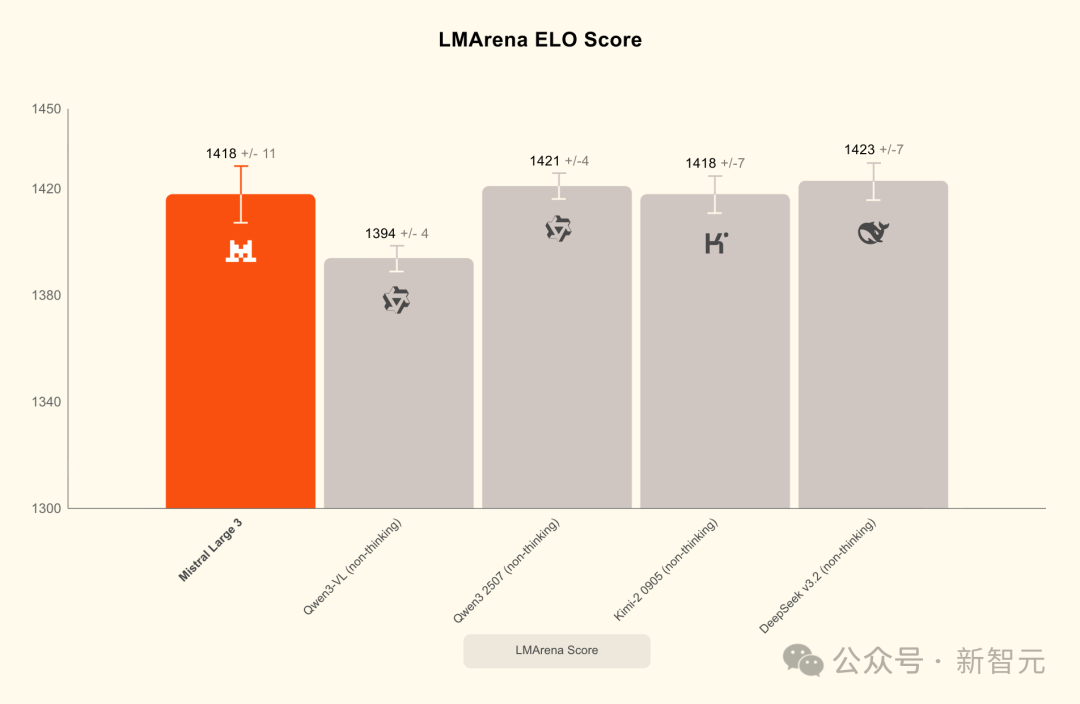
Mistral Large 3的ELO得分在开源大模型中稳居第一梯队,和Kimi K2打成平手,仅落后DeepSeek v3.2一小截
它的底模表现也不弱,在多个基础任务上与DeepSeek、Kimi这种体量更大的模型正面交手。

Mistral Large 3(Base)在MMLU、GPOA、SimpleQA、AMC、LiveCodeBench等多项基础任务上与DeepSeek 37B、Kimi K2 127B保持同一水平,属于开源系的第一梯队底模
再看预训练能力,它和Qwen、Gemma的底模在核心评测上也是正面硬刚:

Mistral Large 3在多个核心基准上与DeepSeek、Qwen正面对比
但官方却没把重点放在数值上,反而强调:
我们开源Apache 2.0,全权在你;你想怎么改、怎么部署都行
为了实现这一点,他们和NVIDIA做了一件简单,但却很关键的事:
为了让Large 3运行得更稳定,Mistral联合NVIDIA把底层推理链路重新做了一遍:
采用NVIDIA的FP4,并重写了Blackwell的注意力与MoE内核,让Large 3在Blackwell NVL72上既快、又稳、又便宜。
这不是简单的适配,而是把Blackwell的注意力机制、MoE内核、预填充/解码分离和投机解码等关键推理路径重新做了一遍。

真正让Mistral得意的,是Ministral 3系列。
它们体量小,但性能强。
3B、8B、14B三种大小,全部有base、instruct、reasoning三个版本,全部能看图,全部在官方benchmark里表现不俗。
这意味着:你的笔记本能跑,你的台式机能跑,无人机、机器人、汽车、边缘摄像头都能跑,甚至脱离互联网也能跑。
更关键的是,模型不只是「小」,而是「更聪明」。
Ministral 3的instruct版本在综合智能指数上的得分分别是31(14B)/ 28(8B)/ 22(3B)──全部跑赢上一代Mistral Small 3.2,参数量甚至多40%。
也就是说这代小模型不仅便宜、能跑在更多设备上,本身能力也从底层被拉升了一大截。

Large 3相比上一代Large 2提升了11分,达到38分。
但即便这样,它仍没有进入GPT-5、Gemini 3、Claude Opus那种顶级专有模型所在的第一梯队。
Artificial Analysis的综合榜单里,前排依旧被GPT-5、Gemini 3、Opus系列占据;
DeepSeek和Qwen也在持续贴近第一梯队,Mistral Large 3则恰好卡在两者之间。

这是一次可见的进步,但它的定位从来都不是「跑分之王」。
但这并不影响它的工程价值。Large 3用的是稀疏MoE架构,本身就很吃算力。
所以这次Mistral直接和NVIDIA深度绑定,把Blackwell 系列最新的注意力机制、MoE加速内核都接了上来。

最有意思的是,他们一起把「预填充 / 解码分离」和「投机解码」也做进了底层,让长文本、高并发这种企业级场景跑起来更稳、更快。
更关键的是,Ministral 3系列不仅体积小,它们已经被官方优化到能直接跑在各种真实设备上:DGX Spark、RTX PC、普通笔记本,甚至是 Jetson 这种嵌入式板子。
从数据中心到机器人,从工厂到无人机,只要有块GPU,就能跑Mistral的小模型。
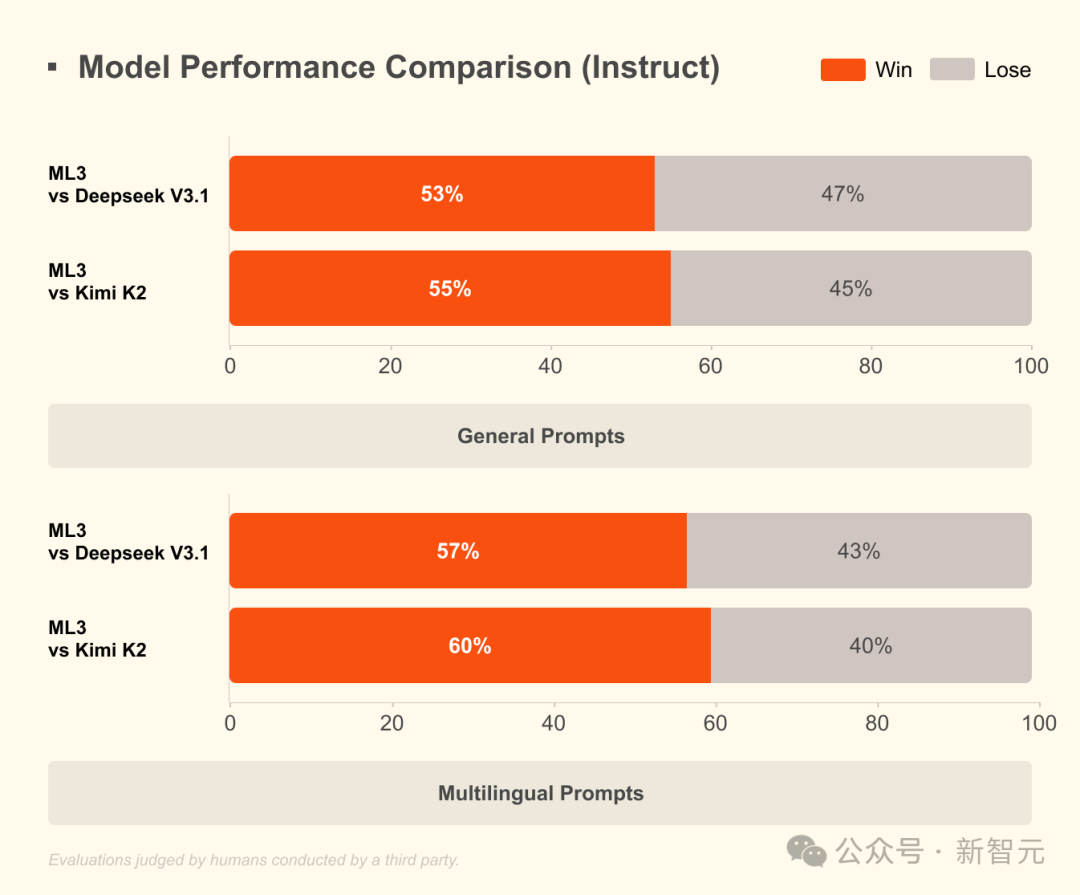
Mistral Large 3(Instruct)在真实任务评估中对比 DeepSeek V3.1 / Kimi K2的胜率
再看reasoning版,AIME’25(数学推理)能在14B下做到85%。
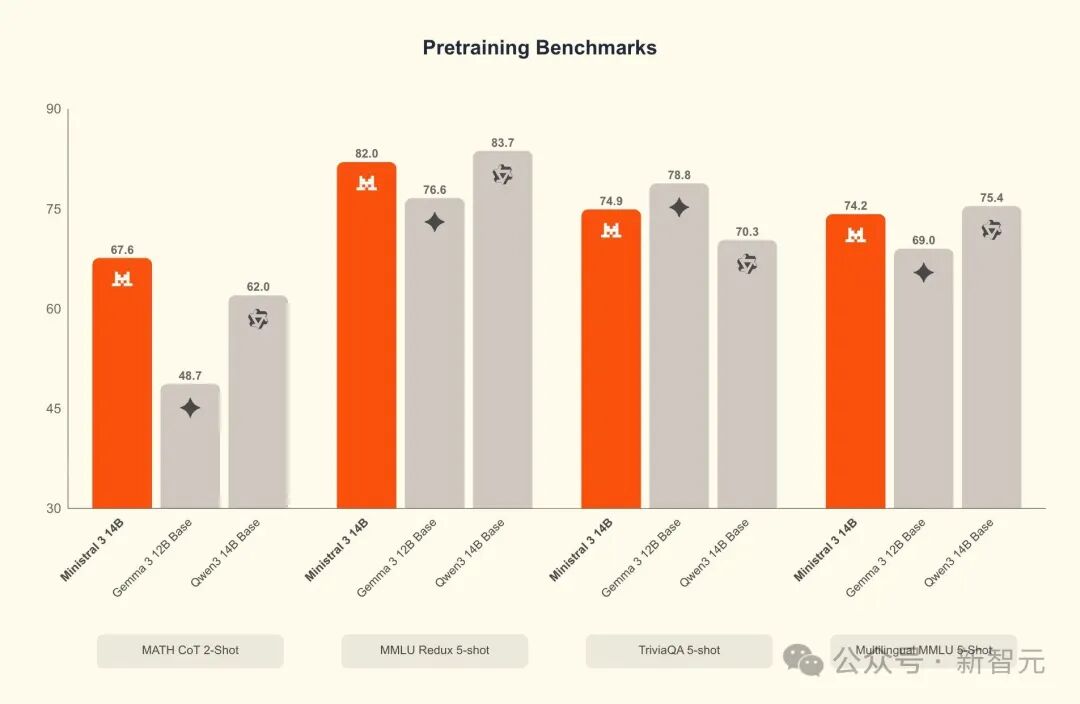
Ministral 14B的底模实力远超同量级对手,在数学、知识问答、多语言任务中几乎全面领先Gemma 13B和Qwen 1.8B
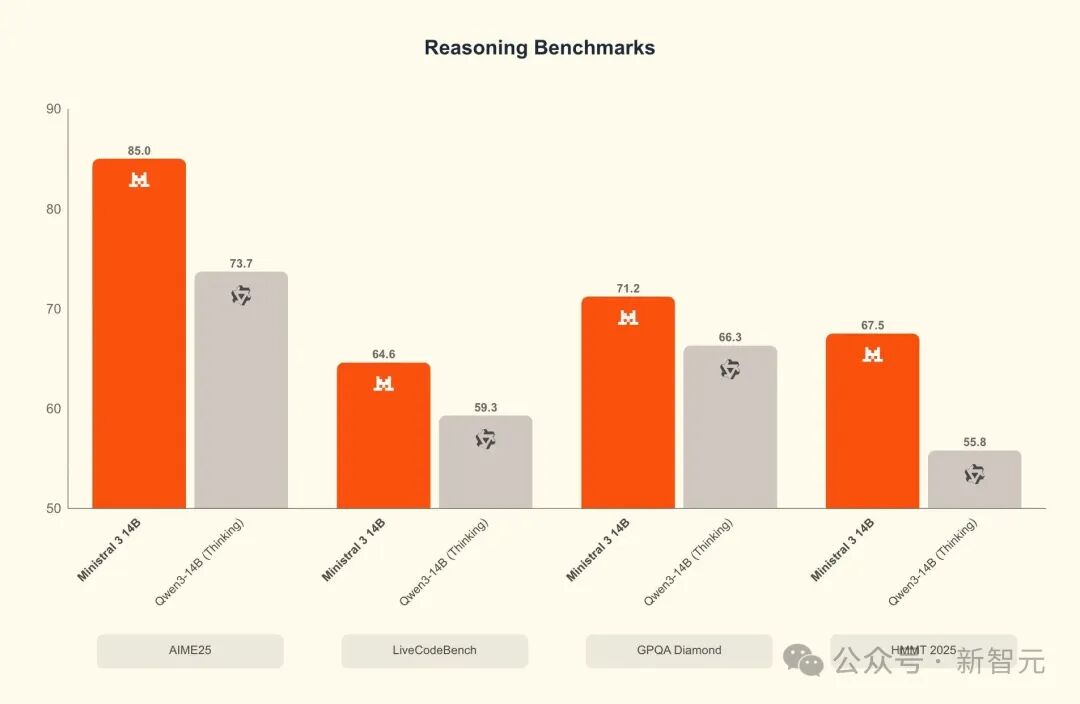
Ministral 14B(Reasoning)在AIME’25、LiveCodeBench、GPOA Diamond、HMMT等推理任务上全面领先Qwen 14B「Thinking」,数学和代码推理几乎是同量级中的天花板。
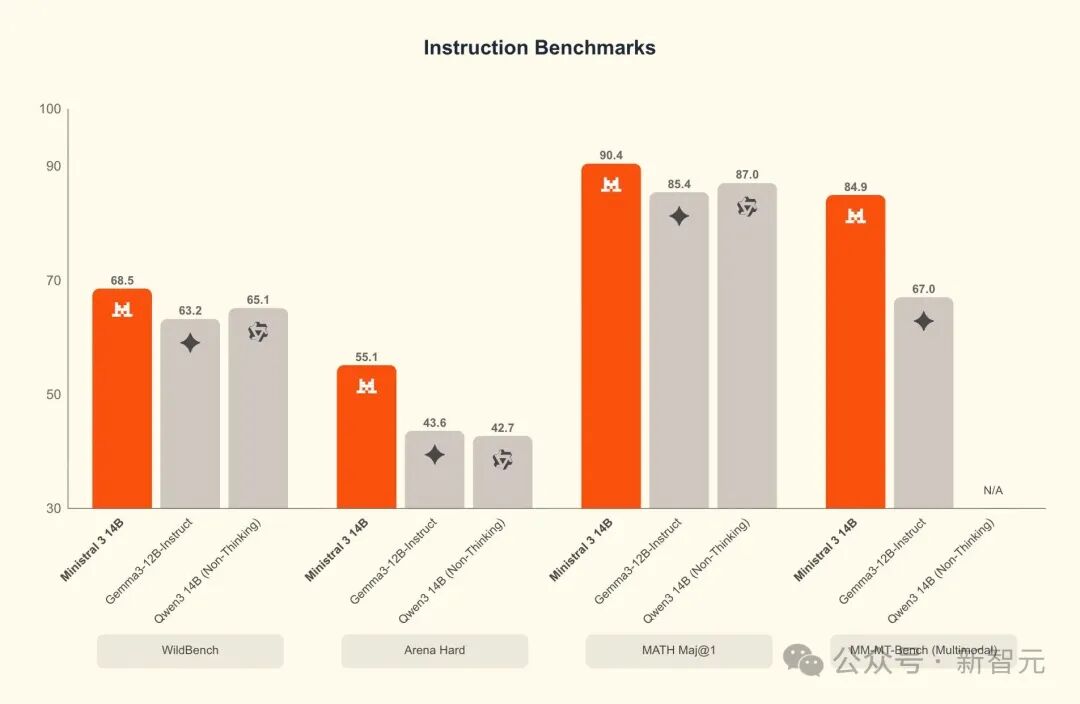
Ministral 14B(Instruction)在WildBench、Arena Hard、数学推理和多模态任务上全面领先Gemma 13B与Qwen 1.8B,指令调优后的综合能力几乎碾压同量级模型。
这在小模型推理中,几乎是突破天花板的表现。
Mistral首席科学家Guillaume Lample一语点破:
超过90%的企业任务,用微调过的小模型就足够了。
这相当于对OpenAI的直接挑衅。
OpenAI的最强模型需要昂贵的显卡,每个token都在烧钱;Google、Anthropic的Agentic模型配置更高。
但企业真正要的是:能用、可控、便宜、可靠。
Ministral 3正是在针对这一痛点。

Lample在一次采访中提到这样一个有趣的现象:
很多公司用最强闭源模型做原型,结果上线时发现成本太贵、延迟太高,只能退回来找我们。
闭源头部模型有天然的缺陷:出了问题企业无法修复,企业数据必须上传云端,成本高的吓人......
Mistral直击要害:模型不够好?我们下场帮你造数据、帮你调模型。
他们直接派工程师进驻客户公司,把模型变成按需定制的「企业专属AI」。
用一个14B,干掉别人70B、400B的大模型,在企业场景里完全可能。
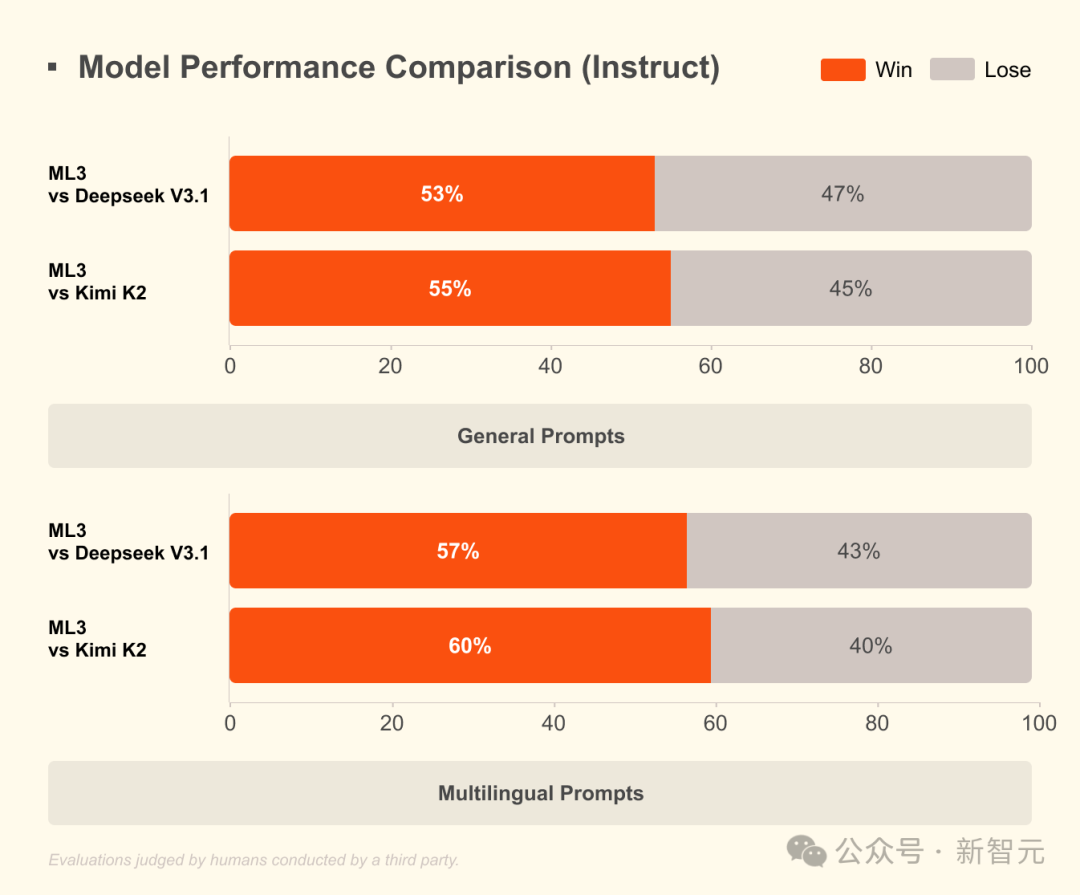
在真实人工评估中,Mistral Large 3在通用任务和多语言任务里对DeepSeek V3.1、Kimi K2取得53%–60%的胜率
把视线从模型本身移开,就会发现Mistral不仅仅是卖模型。
它在悄悄把自己变成一种平台型的存在,而那套结构现在已经清晰到让人无法忽视。
Mistral Agents API,它不仅能跑模型,还能直接在API内部接Code Interpreter、执行代码、接连工具、保持长期记忆、做结构化推理。

Magistral,专门为「复杂推理、透明推理、多语言推理」训练的模型系列。
还有突然爆火的AI Studio。官方称其能「部署在任何地方」。

由此可见,Mistral在走一种不同寻常的AI路线。
它不像美国那套「云端神谕」,更像是欧洲式的「软件制造业」哲学:
把能力做成标准件,让所有人随取随用。
Mistral 3的发布,让全球AI版图出现了一个新的裂缝。
一边是不断做大的「云端巨兽」,另一边是开始渗透到笔记本、无人机、工厂、公共机构里的「小而强AI」。
AI的未来到底属于几家巨头,还是属于每个人的设备、每个国家的生态?
这场争夺从今天才正式开盘。
参考资料:
https://mistral.ai/news/mistral-3
https://venturebeat.com/ai/mistral-launches-mistral-3-a-family-of-open-models-designed-to-run-on
https://x.com/MistralAI/status/1995872768601325836 https://x.com/ArtificialAnlys/status/1995946145236001168
文章来自于“新智元”,作者 “倾倾”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
