# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家还记得Mira Murati吗?那个曾经主导ChatGPT开发的“AI女王”,OpenAI的前CTO,2024年突然离职后,让整个科技圈炸锅!
她没闲着,2025年2月就低调创办了Thinking Machines Lab,带着一群OpenAI旧将,直接杀入AI前沿战场。
短短几个月,融资20亿美元,估值飙到120亿美元,现在更传出新一轮融资目标直冲500亿美元!这速度,这手笔,简直是AI界的“神话”!而最近的重磅炸弹来了:他们的首款产品Tinker正式全面开放!不再需要等待名单,人人可用!
她在X上发帖:Tinker 已经全面可用,并更新了新模型和新功能,这其中就包括两款国产模型:Kimi K2 Thinking 和 Qwen-VL系列。
离开 OpenAI 之后,Murati 的 Thinking Machines Lab 并没有急着再做一个“更强的模型”。
他们团队选择切入的是一个看起来不性感但又非常关键的位置:模型训练与模型使用之间的断层。
在行业叙事里,大模型微调有一种很简单的说法:“准备数据 → 调几个参数 → 跑一轮训练”。但现实中,大多数团队卡在了这些地方:
微调不是一项算法能力,而是一整套工程系统能力。这也是为什么,真正把微调用起来的,往往是少数大厂或顶尖研究团队。

Thinking Machines 的联合创创始人Lilian Weng就曾发帖解释了业界研究者微调前沿大模型的困局:
现在GPU 价格昂贵,而且要把整套基础设施搭建好、让 GPU 真正高效地为你工作,本身就非常复杂。这使得研究人员和机器学习从业者在前沿模型上的实验变得困难重重。
因此,提供高质量的研究工具,是提升更广泛社区研究效率最有效的方式之一,而 Tinker API 正是我们朝这个使命迈出的重要一步。
所以,Thinking Machine Labs 要做的就是就是把模型训练这件高度封闭的事情,改造成面向大众选手的、可“边训练、边验证”的工具。
今年10月,Thinking Machine Labs 团队终于发布了产品 Tinker!让开发者们告别了“基础设施烦恼”。
简单说,Tinker是一个超级强大的AI模型微调平台,让开发者、研究者和普通黑客都能轻松定制前沿大模型,而不用自己操心复杂的分布式训练、GPU集群和基础设施。
这就是Tinker的设计理念:让用户能够专注于LLM微调中真正重要的部分——数据和算法,而平台则负责处理分布式训练的繁重工作,比如后台自动处理调度、资源分配、故障恢复等。

在Tinker上,用户只需在自己的CPU机器上编写一个简单的Python训练循环,其中包含数据(或环境)和损失函数。Tinker平台则负责将用户指定的计算任务,高效、精确地运行在大量GPU上。
值得一提的是,在Tinker上切换不同规模的模型非常简单,从一个小型模型换到一个大型模型,只需在代码中更改一个字符串。
更令人叫好的是,Tinker并非一个让微调变简单的黑盒,而是一个清晰的抽象层。它在为用户屏蔽分布式训练复杂性的同时,完整保留了用户对训练循环和所有算法细节的控制权。
在Tinker中,即便模型还在训练,也可以通过标准接口直接调用,查看当前效果。
这次的Tinker已经全面面向公众开放注册,已经无需 waitinglist 的等待。
入口地址:
https://thinkingmachines.ai/tinker/
这还没完,今天 Tinker 还推出了三项重磅更新!
第一,新增万亿参数级推理模型:支持Kimi K2 Thinking模型。众所周知,该模型是专为长时长推理和工具调用设计的“怪物级”模型!这也是Tinker目前产品线中最大的模型。用户现在可以在 Tinker 上对 Kimi K2 Thinking 进行微调。
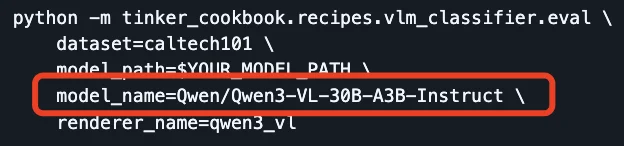
第二,视觉语言模型加持:新增了两款Qwen3-VL系列模型,Qwen3-VL-30B-A3B-Instruct 和 Qwen3-VL-235B-A22B-Instruct。
借助这两款模型,用户可以处理图片、屏幕截图和图表,用于各种应用场景。
model_input=tinker.ModelInput(chunks=[tinker.types.ImageChunk(data=image_data,format="png"),tinker.types.EncodedTextChunk(tokens=tokenizer.encode("What is this?")),])
这意味着,开发者也可以在Tinker上玩转多模态AI了!
第三,兼容OpenAI API:新增了与 OpenAI API 兼容的脚手架功能,用户可以通过指定路径快速从模型中采样,即使模型仍在训练中。这也意味着 Tinker 现在可以即插即用,与任何兼容 OpenAI API 的平台配合使用。
response=openai_client.completions.create(model="tinker://0034d8c9-0a88-52a9-b2b7-bce7cb1e6fef:train:0/sampler_weights/000080",prompt="The capital of France is",max_tokens=20,temperature=0.0,stop=["\n"],)
可以说,本质上做了三件事:
一、让模型在训练过程中就能被调用和验证;二、用 OpenAI API 兼容接口,统一推理使用方式;三、把推理、微调、多模态能力,压进一个工程平台里。
那么Tinker怎么用呢?官网上还放出了一个非常有意思的实例教程:微调一个视觉语言模型(也就是现在很流行的VLM)图像分类器。
团队发现,即便每个类别只有一个样本,Qwen3-VL-235B-A22B-Instruct 也能取得合理的准确率;随着标注数据的增加,性能还会进一步提升。
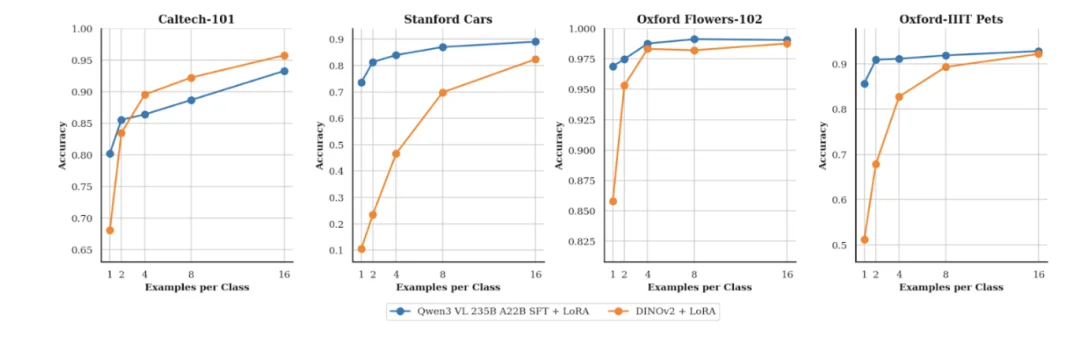
在放出的CookBook中,团队用Qwen3-VL模型战胜了常被用作纯计算机视觉任务的骨干网络的 DINOv2 (一个自监督的视觉 Transformer)。
文章中还解释了原因——因为VLM模型天生具备语言知识。
在小样本数据场景下,Qwen3-VL-235-A22B 的表现优于 DINOv2。这不仅因为它模型规模更大,还因为作为 VLM,它天生具备语言知识(例如知道“金毛寻回犬”或“向日葵”是什么)。
正是这种语言与视觉相结合的通用能力,使 Qwen3-VL 能够轻松扩展到分类之外的更多视觉任务。
首先,毫无疑问是 Mira Murati的个人光环。
她是ChatGPT的核心缔造者之一,离职后直接拉起一支“OpenAI梦之队”,包括John Schulman、Lilian Weng等大牛。她的每一步都牵动AI圈神经!
其次,AI民主化浪潮。当下AI越来越封闭,OpenAI、Google们把顶级模型锁得死死的。Tinker反其道而行,推动开放科学,让更多人参与前沿研究。这不只是工具,更是理念革命!
然后,时机完美。2025年AI竞赛白热化,Tinker一出,直接拉低了自定义模型门槛。想象一下:数学推理、化学建模、法律文书、医疗诊断……无数场景即将爆发新应用!
以前 fine-tuning 大模型是巨头们的专利,需要海量计算资源和工程团队。现在?Tinker 把门槛砸到地板,让中小团队、独立开发者也能玩转前沿AI!
Mira Murati说,这正是他们公司的愿景:让AI更易懂、更可定制、更普惠,让每个人都能探索AI的极限。
让人工智能系统被更广泛地理解、可定制并具有普遍能力,通过坚实的基础、开放的科学和实际的应用,让人工智能变得更有用、更易懂,从而推动人工智能的发展。
接下来,这支梦之队计划如何?很简单又很伟大,只有四个字:全面微调!

期待这台“思考机器”,接下来给世界带来的新产品!
文章来自于微信公众号 “51CTO技术栈”,作者 “51CTO技术栈”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
