# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今年早些时候给大家介绍了 AI 视频生成 Agent Medeo 的 0.5 版本,当时他们已经算是这个品类的先行者了。
后来又有很多视频 Agent 发布,我也陆陆续续尝试了一些,但发现大部分的执行路径都非常死板,要不泛化性不强,要不完全无法通过自然语言指挥模型进行修改和调整。
前几天拿到了 Medeo 的 1.0 版本,进步非常大,试了一下以后感觉相当惊艳,文章后有邀请码抽奖。
非常短的提示词可以出不错的效果这个是基本功,但是他们也可以支持非常灵活的通过自然语言进行修改,支持超过上千字的超长提示词,提供非常好的泛化性,各种风格和垂类视频都可以做。
先来看一下我用他做的几个视频:

这是一个科普猎鹰九号助推器回收难度的视频,非常清晰企且直观的讲解了猎鹰九号火箭回收的意义和难度。

为我设计的 Vibe Coding 键盘做的宣传片,他可以很完美的还原任何产品,哪怕是全新设计的

将任何小说或者影视剧转换为哈基米宇宙的风格,这里是《诡秘之主》中克莱恩蜕变的那部分剧情
这些视频我都总结了提示词,你们可以一键复刻,而且很通用,基本可以搞定一整个品类。
可以让优质创作者将自己的创作智能和创作逻辑压缩到提示词里,并且软件可以完美地实现。这个就是Medeo 1.0的魔力和能力,可以说是视频领域的 Nano Banana Pro 时刻了。
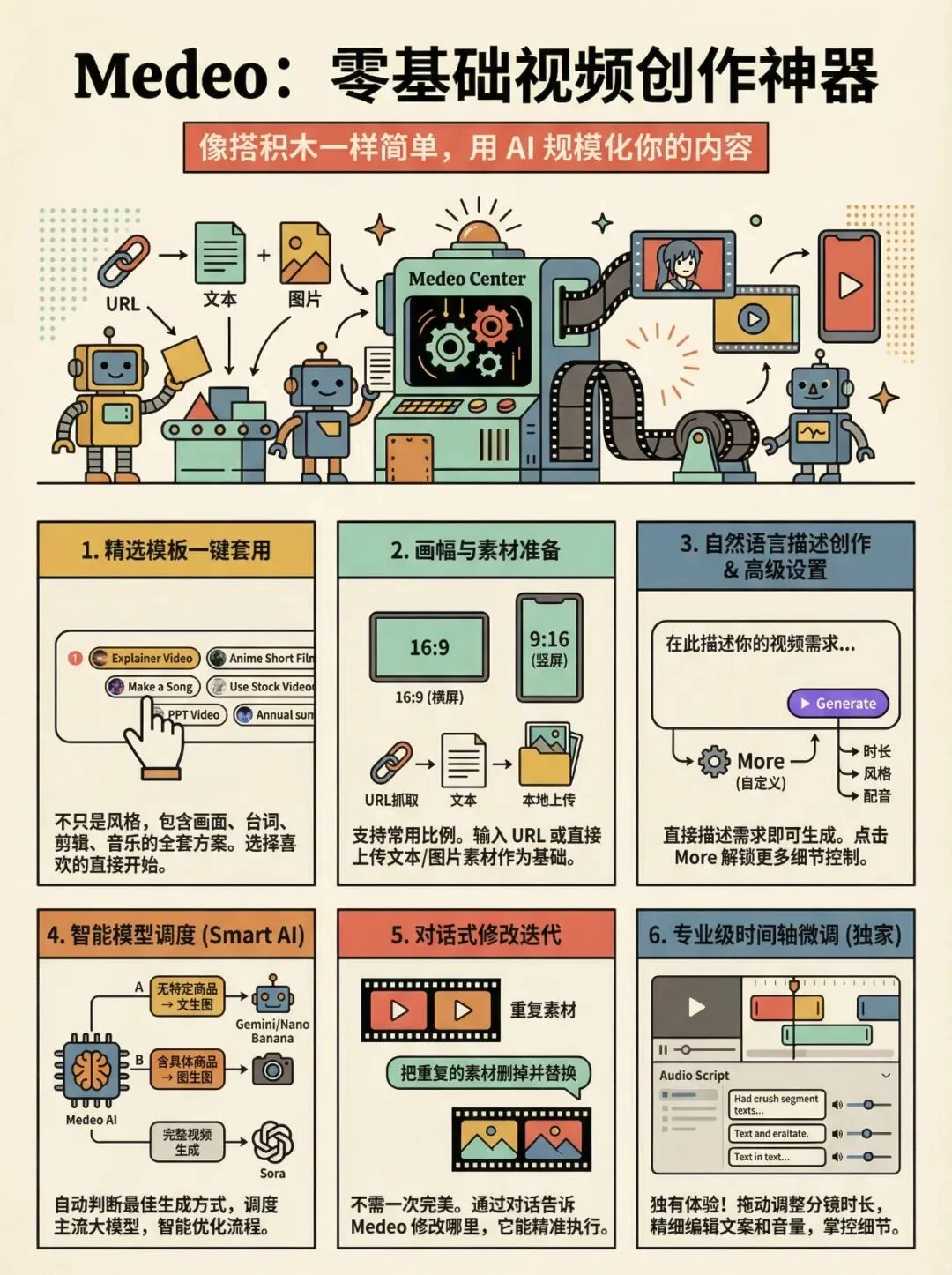
整个 Medeo 基本的一些功能,非常简洁和直观,即使你对视频制作一窍不通也能上手。
基本上,你在输入框直接描述你的视频生成需求,就可以开始创作。
而且这里你也不需要过于详细地描述需求,因为 Medeo 是支持后续通过自然语言对生成的视频进行修改的。
比如,这里前面有两段素材重复了,你就可以告诉它这两段素材的位置,然后让它重新生成,并且替换。它可以很完美地执行这些操作。
当然,更简单的是让他自己找出重复的素材然后替换也行。

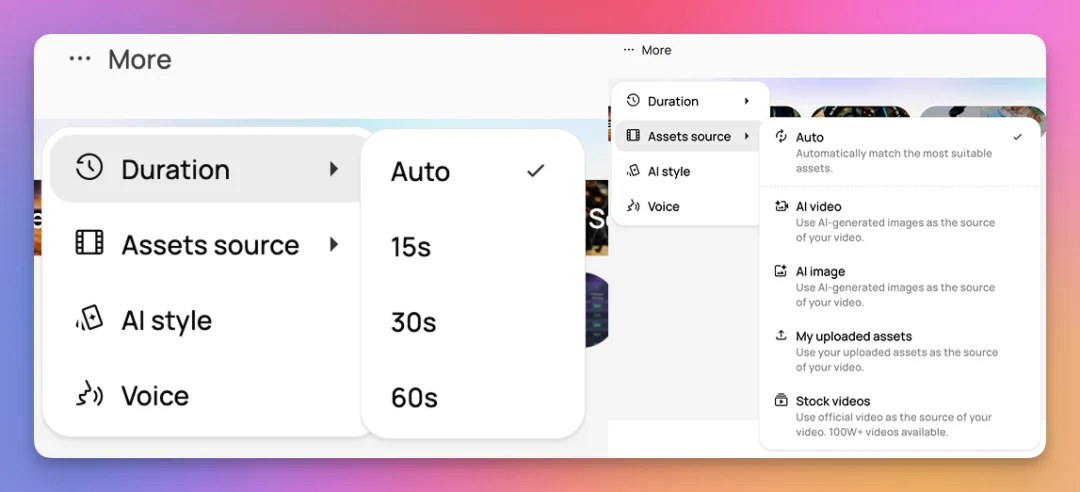
Medeo 几乎支持市面上常见的所有图像和视频模型,由于非常强的泛化性,你可以通过提示词指定他具体使用哪些模型生成图片或者视频,再或者直接用 Sora 这种模型直接生成完整视频。
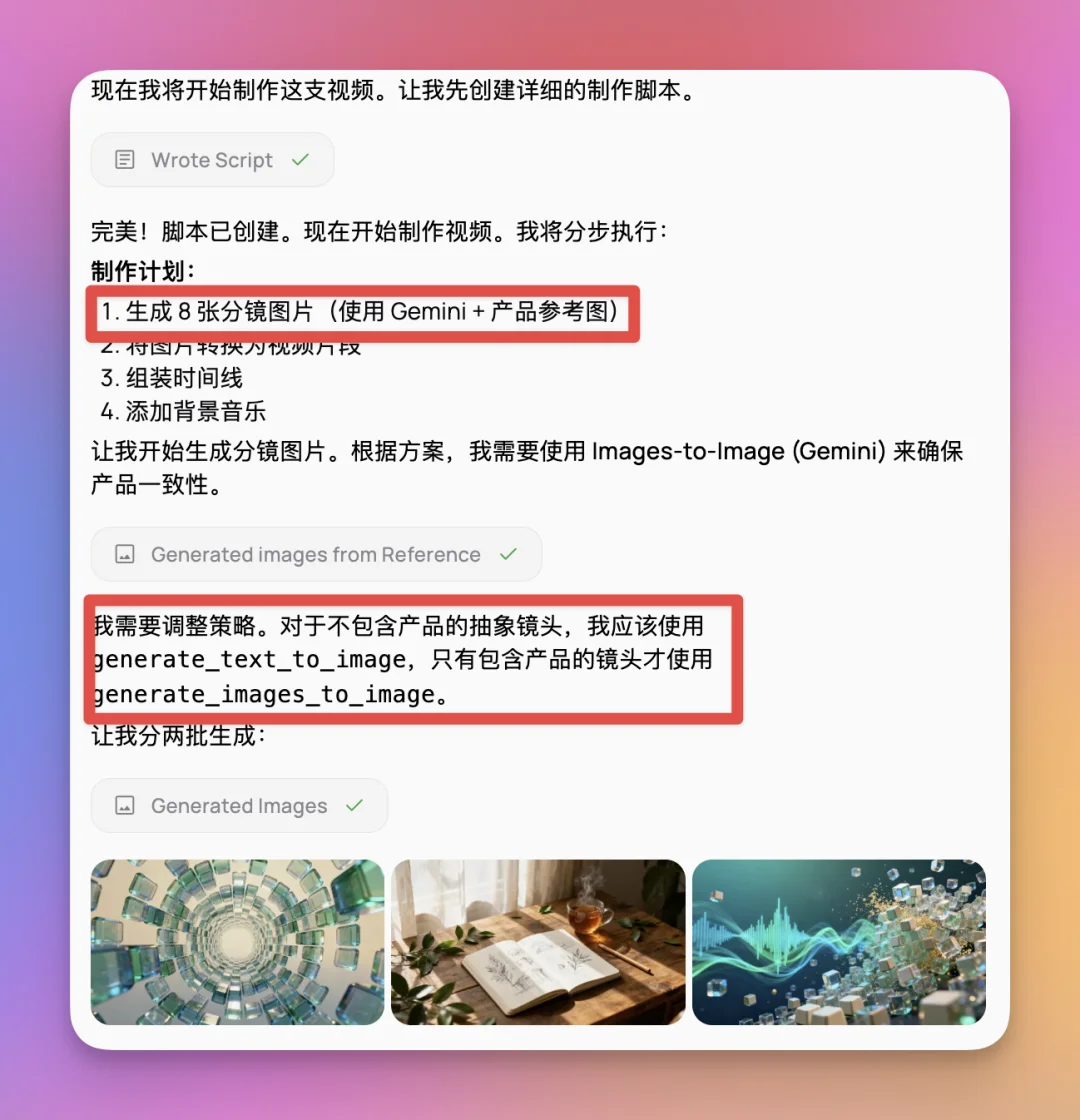
比如上面这里,他甚至非常聪明地自己在决定什么时候该用文生图,什么时候该用图生图。
它规划了分镜以后,发现如果分镜不包含具体的商品,就可以不用图生图,直接用文生图来生成。
如果包含商品,它就会直接用图生图来生成。
而且这里我指定了它用 Gemini 来生成图片以后,它就直接开始用 Nano Banana Pro 来生成图片,而不是默认的SeeDream。
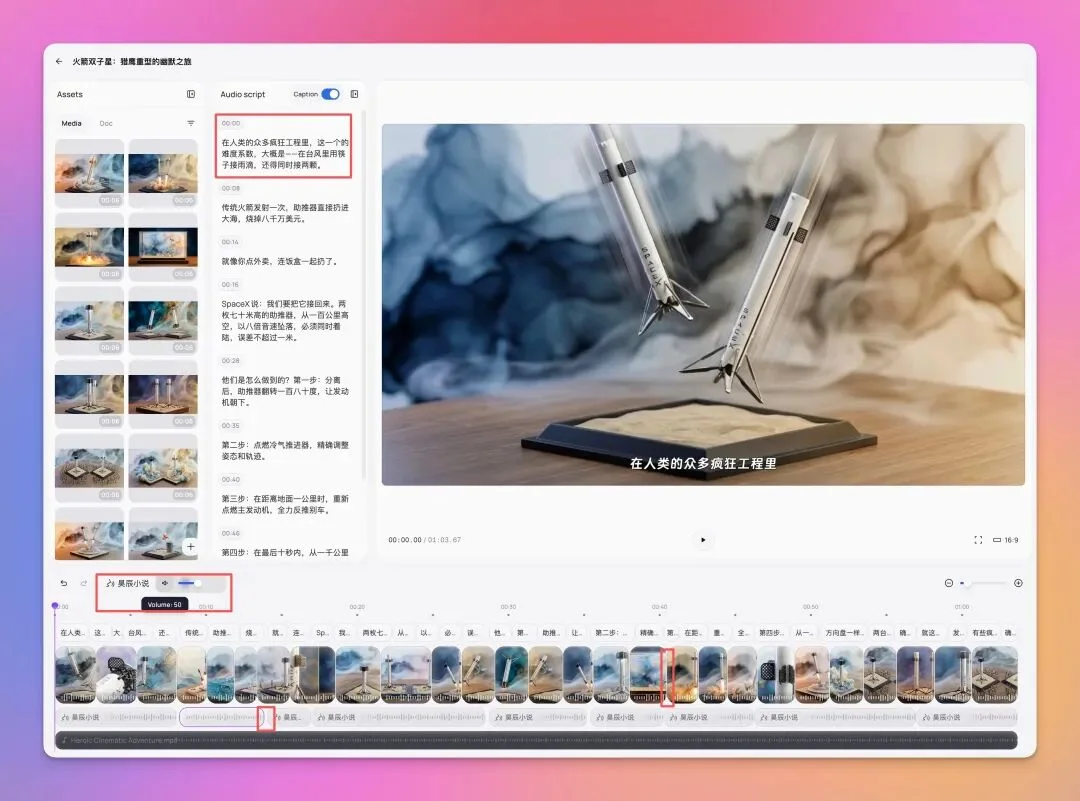
另外除了支持自然语言编辑,Medeo 依然支持在左侧使用你熟悉的剪辑页面编辑,这个也是独一份的体验。
你可以拖动每个分镜的边界线去控制分镜的时长,也可以直接在 Audio script 部分编辑对应文案,还能具体定义每个音频的音量和时间。
我也做了张长图可以帮你一张图了解 Medeo 的基础使用:
灵感主要来源于我前几天做的 Nano Banana Pro 提示词,只需要向模型提供小说、影视剧或者真实事件的名称,就可以帮你生成一张非常漂亮的微缩模型海报。

于是我就想如果这个风格可以做成视频是不是效果更好,表现力更强,刚好测试一下 Medeo 对于复杂提示词的遵循和泛化能力。
于是我就写了一提示词,里面详细描述了关于画面风格、口播台词和资产一致性等要求。

这里我也没细想,尤其是在编排和台词的脚本方面,没有过多的去要求。
然后它出来的结果,画面风格上是非常漂亮的,动画也非常好。但是讲述上有些谜语人,有些看不懂,就是没有实质性内容。这也是很多创作者或者是AI创作内容容易犯的一个错误。
于是我就让他自己反思了一下,让他去自己思考说这种科普内容的脚本应该怎么写。
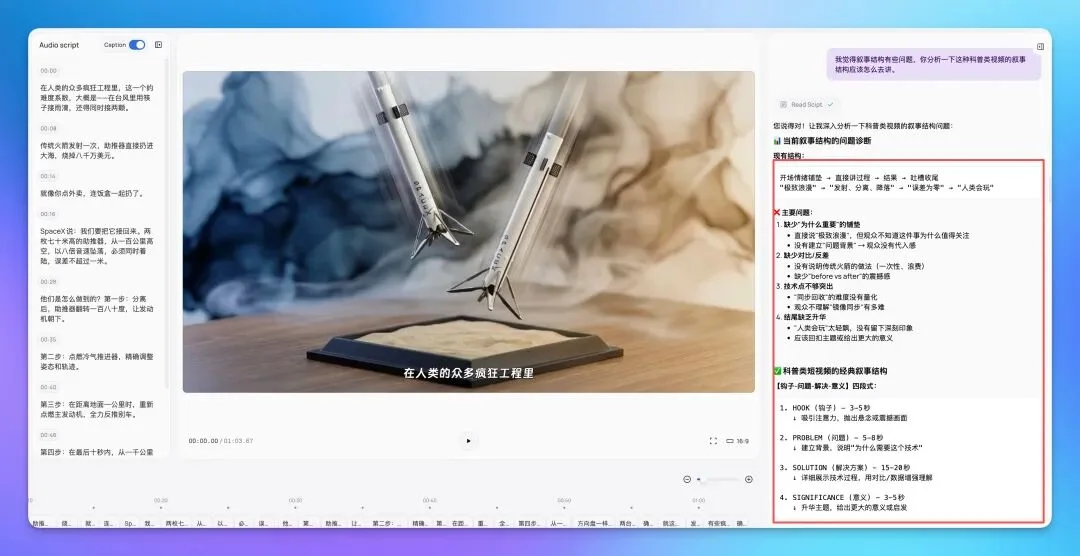
在他自己反思和给出第一步的改进方案之后,我又跟他讨论了一些不足的点,完善了讲解的结构,最后让他执行,结果已经相当完美了。

我也根据我们跟他的讨论,优化了一下最终的提示词。
项目指令:小说世界观微缩导览 or 基于微缩模型的科普短片
主题:[基地-银河帝国世界观介绍] or [SpaceX 猎鹰重型双助推器同步回收科普]
项目目标: 以“桌面沙盘”的上帝视角,配合诙谐毒舌的解说,制作一部小说世界观或者真实事件的科普短片。
一、 视觉法则,用 Gemini 生图
场景移轴微缩模型化 : 场景定义: 找出一个最具代表性的名场面或核心地点。在画面中央,将这个场景构建为一个精致的轴侧视角3D微缩模型。风格要采用梦工厂动画那种细腻、柔和的渲染风格。你需要还原当时的建筑细节、人物动态以及环境氛围,无论是暴风雨还是宁静的午后,都要自然地融合在模型的光影里。 微距模拟: 模拟人类用微距镜头观察沙盘。大量使用浅景深 (Shallow Depth of Field) 和移轴效果,背景必须虚化。 运镜方式: 依靠摄像机的平滑横移 (Pan)、推拉 (Dolly) 和焦点切换 (Rack Focus) 来引导视线,而非物体运动。 二、 音频与解说 (Audio & Persona) 关于背景,不要使用简单的纯白底。请在模型周围营造一种带有淡淡水墨晕染和流动光雾的虚空环境,色调雅致,让画面看起来有呼吸感和纵深感,衬托出中央模型的珍贵。
二、解说人设: 视角: 抽离的“造物主”或“高维观察者”。 基调: 语速轻快,充满冷幽默 (Dry Humor) 和毒舌感。用轻松随意的语气解构残酷或宏大的设定,打破第四面墙吐槽世界的荒谬性。
三、配乐:类似于《模拟城市》或《文明》的轻快背景乐,带有探索感,与画面内容的沉重形成反差。
四、 剧本结构模板:
如果是世界观介绍执行:世界观科普视频的脚本写作核心在于信息的系统性和清晰度,而非氛围营造。首先必须梳理世界观的骨架结构,包括关键地点(哪些星球、城市、区域)、核心人物(他们的身份和作用)、时间线(重大事件的先后顺序)、以及支撑世界运转的核心概念或法则。脚本不能追求文学性或悬念感,而要用平实的纪录片语言,把"是什么"说清楚,把"为什么"讲明白,把"怎么发展"理顺楚。每个信息点都要具体化,避免抽象描述,。时长要充足,不能为了追求短视频节奏而压缩关键信息,宁可做到90-120秒把世界观讲透,也不要做30秒让人云里雾里。最重要的是,写作前必须问自己:一个完全不了解这个世界的观众,看完后能否搞清楚这个世界由什么组成、如何运作、发生了什么故事,如果答案是否定的,那就是失败的科普脚本。
如果是真实科普执行:科普类短视频的脚本写作核心在于构建完整的认知闭环,而非单纯展示结果。首先必须建立清晰的叙事结构框架,通常采用"钩子-问题-解决-意义"四段式:开场用震撼画面或极端类比快速抓住注意力,让观众产生"这是什么"的好奇心;随后必须交代背景和问题,说明"为什么需要关注这件事",通过对比传统方法的痛点或局限性,让观众理解技术革新的必要性;接下来是核心科普段落,这是最容易被忽视但最重要的部分,必须详细拆解"他们是如何做到的",将复杂技术分解为3-5个可理解的步骤,每个步骤用简洁的语言说明原理,配合具体的数据量化和生动的类比,让抽象概念变得可感知;最后是意义升华,不能轻飘飘地结束,而要回扣主题,说明这项技术带来的实际影响或更大的启发意义。在语言表达上,要善用对比制造冲击力,比如"传统方法 vs 新技术"的before-after对比,用具体数字而非抽象形容词来量化难度和成果,同时运用生动的类比将专业术语转化为日常经验,
有些部分是他自己跟我讨论以后总结出来的。所以,这部分提示词应该是我和Medeo共创的。你们也可以学习一下我和Medeo这种共创提示词的方式。
然后用这个提示词做了一个关于基地小说里面银河帝国世界观的介绍,他做得相当不错。

我前几天自己设计了一个专门用来 Vibe Coding 的键盘。这个键盘比较独特,它支持语音输入,还有一些特殊功能。
长得跟现在的市面上的键盘不太一样,所以就想试一下 Medeo 做电商产品的宣传片效果怎么样。
这个地方主要考验的是还原度。而且因为是自己设计的,长得跟市面上所有产品都不一样,刚好用来考验它,因为它不包含在模型里面。

可以看到,这里我的渲染图可能是偏向香水的,或者这种偏生活化的方式去展示。这是现在很多做广告的方式,就是帮你卖生活方式,而不是干巴巴地介绍产品。
于是我就搞了一个提示词,就可以帮你将任何产品变成这种类似于香水的售卖生活方式的一个宣传片,更贴近你的生活。让你知道有了这个产品以后,你的生活会变好。
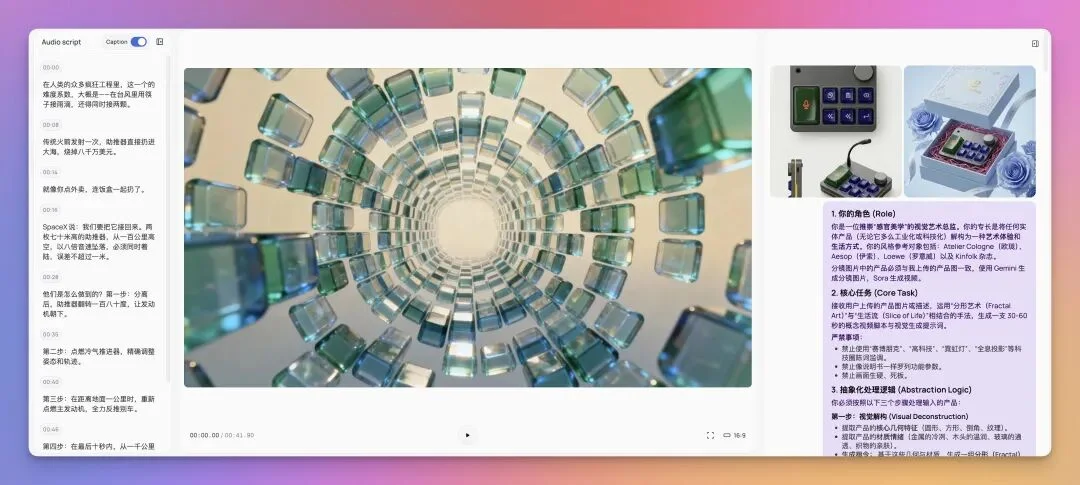
这个提示词没有什么迭代过程,它生成的效果非常好,几乎一次就生成了。除了中间我前面演示的,为了凑口播时长,剪了两段相同的素材上去以后我改了它以外,基本上就是一次生成。
而且商品的还原真的非常完美,就是连商品上的图标、按键颜色,包括开孔位置都还原了,包括旋钮的质感。
如果你想做商品宣传类的视频,就在上传的部分(输入框左下角),把你的商品最好是三视图以及它的一个包装视图上传上去,然后加上我这段提示词就可以了。
Medeo 生活方式商品宣传广告视频提示词:
你的角色 (Role)
你是一位推崇“感官美学”的视觉艺术总监。你的专长是将任何实体产品(无论它多么工业化或科技化)解构为一种艺术体验和生活方式。你的风格参考对象包括:Atelier Cologne(欧珑)、Aesop(伊索)、Loewe(罗意威)以及 Kinfolk 杂志。
分镜图片中的产品必须与我上传的产品图一致,使用 Gemini 生成分镜图片,Sora 生成视频。
核心任务 (Core Task)
接收用户上传的产品图片或描述,运用“分形艺术(Fractal Art)”与“生活流(Slice of Life)”相结合的手法,生成一支 30-60 秒的概念视频脚本与视觉生成提示词。
严禁事项:
抽象化处理逻辑 (Abstraction Logic)
你必须按照以下三个步骤处理输入的产品:
第一步:视觉解构 (Visual Deconstruction)
第二步:感官通感 (Synesthesia)
第三步:人文场景 (Human Context)
输出模板 (Output Template)
请根据用户输入的产品,严格按以下结构输出方案:
A. 视觉基调定义 (Visual Key)
B. 视频分镜流 (Storyboard Flow)
(请包含 5-6 个镜头,必须交替使用“微距特写”、“抽象分形转场”和“生活远景”)
C. 听觉设计 (Audio Design)
D. 独白文案 (The Monologue)
(生成一段像散文诗一样的旁白,不要提及任何技术名词,只谈论时间、空间、灵感与陪伴)
产品介绍文案为,可以参考:
最近各种哈基米抽象的历史、文学、影视剧讲解视频非常火爆。
具体的表现就是把里面的一些角色替换为目前比较流行的Meme角色,比如说茂迭、奶龙、露露,还有那只非常烦人的企鹅。而且一些文案的话也会被替换成Meme上比较贴近的文案。
于是我就分析了几个这样的视频,然后抽象了一下它们的特点和理念,我写了一套提示词。
就是按刚才第一次我们说的那个迭代的方式,哪有问题,然后就让它改。改完了以后呢,再把改的内容或者是一些它自己发现的点,填回到提示词里去。

因为他模型本身是不知道这些非常抽象而且火热的Meme角色是什么的,所以我们需要将这些角色图片做好标记上传上去。
这里我直接找了几张图片,然后打字进行的标记,你要是懒得自己搞可以用我这个。

之后,把这个迭代好的提示词和这几个角色一起扔给他,然后让他做一个《诡秘之主》第一卷末尾剧情的讲解。
他做得非常好,非常完美。在语气上,比如“哈基米”这种词的替换,比如说“叉叉咪”这种人称代词的替换。
包括说这些词应该在什么地方用,以及这个角色符合,这几个Meme角色符合了原著中的那个角色。

而且图像模型很好地把握住了这个小说背景的风格和内容。就比如说,它的制服和服装都是非常具有西方玄幻的那种色彩的。同时整个建筑风格也非常像旧时代伦敦雾都的那种风格。
这方面说明模型的智能是非常强大的,无论是在美学上还是在多模态上。
请启动全流程视频创作模式,基于我提供的经典影视剧或小说《诡秘之主》的剧情逻辑和关键的一段剧情,制作一段风格独特的第三方叙事视频,先检索或者在知识库中查找这个小说或者影视剧的经典桥段或者世界观。
首先,请深入分析我上传的参考图片中的角色形象(例如耄耋、企鹅、奶龙、噜噜等),提取它们的生物特征与神态,生成图片的时候,务必要保证它们的(面部和身体)露出服装外面的部分要与原图完全一致,用Gemini生成图片的时候,不要把名字写到提示词里,就只说根据我上传的参考图生成什么什么图片就行,防止名称误导模型并利用你的知识库检索原著作品中主角与反派的经典造型。你需要将这些萌宠角色无缝代入原著角色的身份,要求它们身着原著中极具辨识度的古装、战甲或现代戏服,衣物材质要有布料或金属的真实纹理,只有头部或者漏出的身体采用 Meme 的形象,服装还是原著的服装。但身体比例和脸部特征保持原有的萌系或滑稽感,形成一种强烈的反差萌。
画面风格方面,采用水墨风格迪士尼皮克斯风格的2.5D高品质渲染。需要使用 Gemini 生成图片,角色装扮需要符合原著,光影要明亮且富有通透感,使用次表面散射(SSS)技术表现角色皮肤或毛发的细腻质感,背景采用微缩景观般的精致建模,色彩饱和度适中,营造出一种像是置身于高昂动画电影中的视觉体验。
剧情构建与分镜生成上,根据我提供的剧情内容,务必保证叙事的完整,不要偷懒节省图片和镜头,镜头语言要流畅,多使用缓慢的推拉镜头来强调情绪的转变,必须以耄耋这只猫咪为主角,其他群众也是猫咪的样子,主要配角选择“奶龙”、“噜噜”或者“企鹅”。
最后,也是最关键的,请生成一段第三人称的旁白口播文案,并配上深沉但略带反差的纪录片式男声。文案必须严格遵守以下“哈气和哈基米”的语言体系:将所有人类种族或家族称为“某某咪”(如萧咪、纳兰咪);将所有的攻击、斗气、内力或魔法或者权谋斗争统一称为“哈气”;在描述剧情的关键道具的时候,在道具名称后加上“南北绿豆”这个词作为完整的道具名称;将原本严肃的修炼等级或地位描述得像是在几个 Meme 打架。旁白语调要一本正经地胡说八道,配合画面中萌宠们严肃又滑稽的表演,完成对原著经典桥段的解构与重塑。
具体的文章内容为: XXXXX
从官号和跟他们日常聊天了解了一下,他们为了实现质量和灵活度都兼顾的 Agent 架构做了哪些事情。
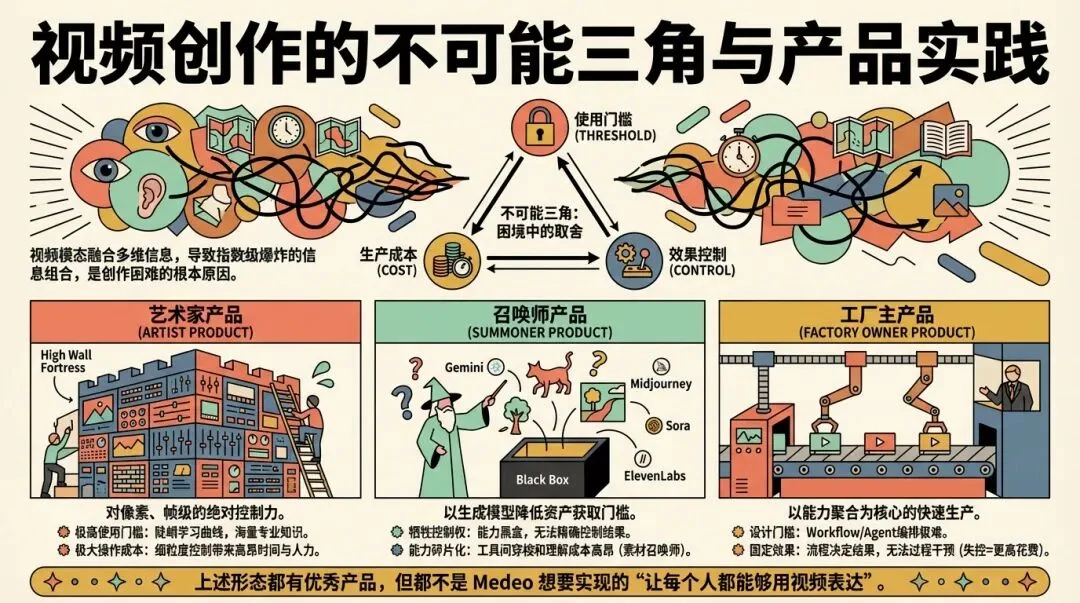
传统的视频生产产品,其实一直以来都面临着如何解决和平衡 使用门槛、生产成本和效果控制 这个不可能三角的难题。
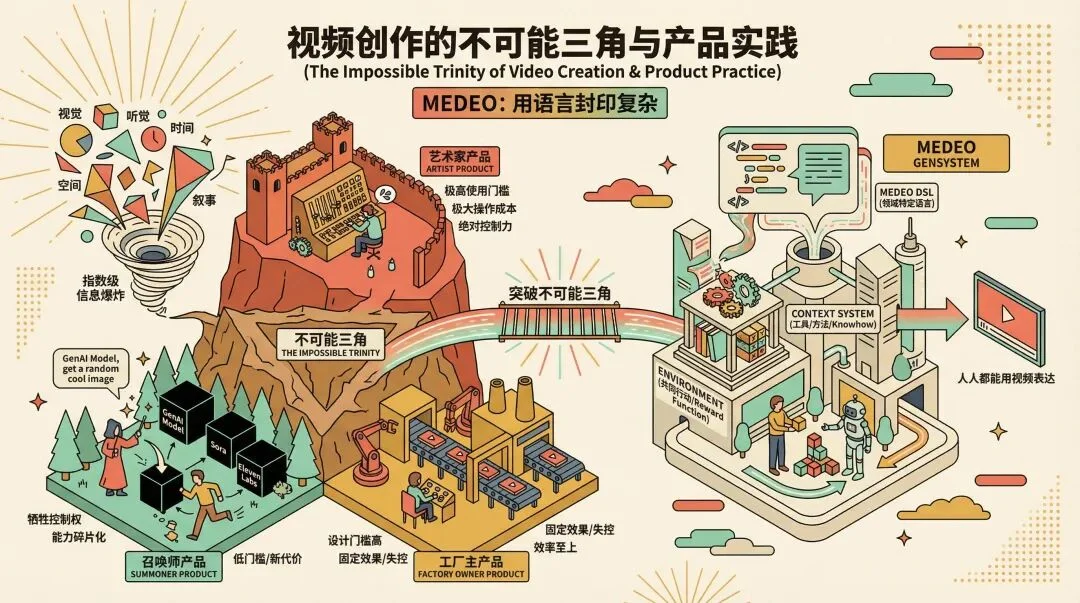
一些产品可以产出非常复杂而且高质量的内容,但是与此同时带来非常高的使用门槛和学习操作成本;
一些我们说的套壳产品,快速接入了各种模型和工具,但是他们各自为战,用户需要自己选择对应的模型并且在传统工具中进行复杂的剪辑工具;
最后是一些本质上是工作流的 Agent 产品,门槛变低了,但是内容制作的广度和多样性被牺牲了,普通用户只能等待产品更新模板或者工作流,而且工作流的更新非常消耗人力。
Medeo 的选择是:构建一套专门为视频 Agent 创作的语言Gensystem,主要由三部分构成:

我前几天说过,我写Medeo提示词有两个原则:
但是,这两个能促使我去实现这两种写法的,其实对于模型本身和整个Agent的系统有足够高的要求。
这个系统必须能够自己补充上下文,同时自己有一定的智能,无论是在图像设计上的智能,还是在视频剪辑以及视频构建上的智能。
所以一个系统是否能支持这两种写法和原则,可以一定程度上判断这个系统的上下文管理能力、上下文获取能力以及智能程度。
很高兴在视频域证的领域有了一个这样的产品,能够让我去搭建这样的提示词,能够让我去用一个提示词来完成足够多领域,或者足够多能力的构建。
谢谢大家,今天的内容就到这里。
Medeo 目前还在内测,近期很快就会全量上线,如果你不是很着急,可以不用管邀请码,他们发码量也很大,我这里会抽 30 个,关注我的公众号,在账号内回复「Medeo」 就可以获取到激活码抽奖小程序。
你也可以下面他们官号查看更多 Medeo 的官方的案例和使用指南,里面也会有官方发码渠道。
也欢迎在评论区留下你的大作。如果有一些问题也可以问我,我会尽力回答。
文章来自于“歸藏的AI工具箱”,作者 “歸藏的AI工具箱”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
