# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。
Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。
在官方放出的测试数据中,Nemotron 3 Nano“拳打”Qwen3-30B,“脚踢”GPT-OSS-20B:
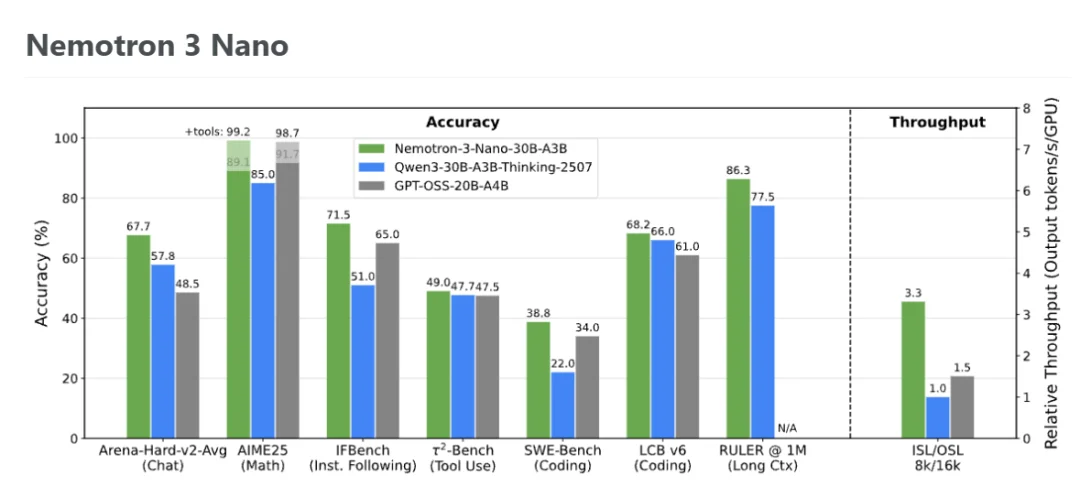
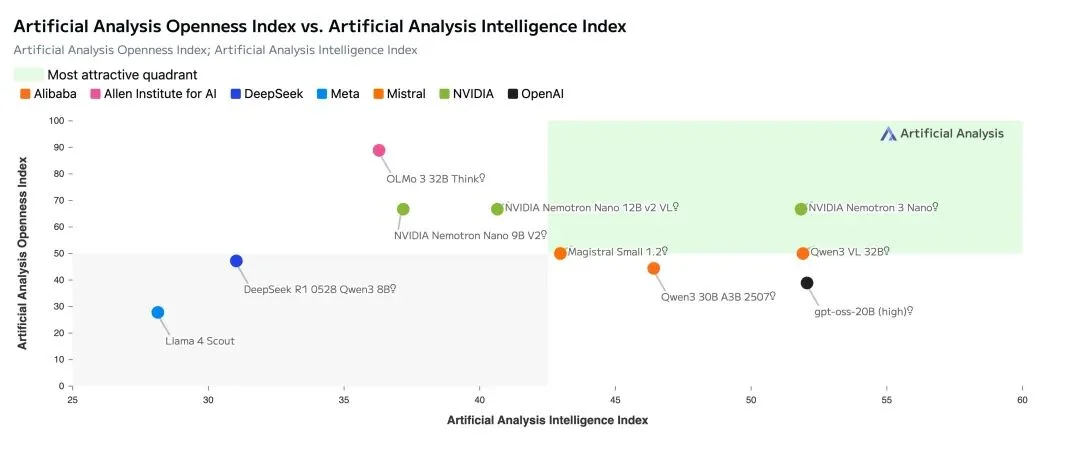
在Artificial Analysis的数据中,Nemotron 3 Nano也基本能和Qwen3-30B、GPT-OSS-20B 比肩。
官方还展示了一个在 Nemotron 3 Nano 上运行的桌椅逻辑谜题,可以看出其推理速度相当可观。
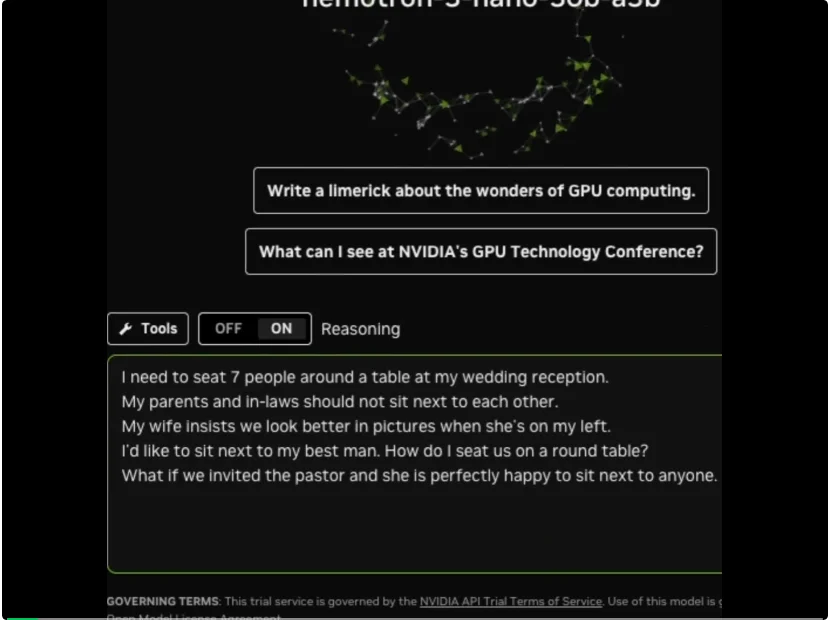
官方指出,Nemotron 3 Nano的推理速度比二代 Nano 快 4 倍,比同规模级的其他领先模型快 3.3 倍。
模型、代码库和技术报告也统统开源:
模型:
https://huggingface.co/blog/nvidia/nemotron-3-nano-efficient-open-intelligent-models
代码:
https://github.com/NVIDIA-NeMo/Nemotron
技术报告:
https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Nano-Technical-Report.pdf
Nemotron3 提供三种不同规模的版本:
Nemotron 3 支持 1M token 的上下文窗口,使模型能够在大型代码库、长文档、延展式对话以及聚合检索内容之上进行持续推理。与依赖碎片化分块启发式方法不同,智能体可以将完整的证据集合、历史缓冲区和多阶段规划全部保留在单一上下文窗口中。
官方指出,这一超长上下文能力得益于 Nemotron 3 的混合式 Mamba–Transformer 架构,该架构能够高效处理极长序列。同时,MoE 路由机制降低了单个 token 的计算开销,使得在推理阶段处理如此大规模序列在实际中具备可行性。
在企业级检索增强生成(RAG)、合规性分析、持续数小时的智能体会话或单体代码仓库理解等场景下,1M token 的上下文窗口能够显著提升事实对齐能力,并减少上下文碎片化问题。
官方表示,目前 Nano 版本已正式发布,Super 和 Ultra 预计将在 2026 年上半年发布。
此次 Nemotron 3 系列最大的技术亮点在于:引入了开放的混合式 Mamba–Transformer MoE 架构,面向多智能体系统中的高速、长上下文推理场景。
英伟达已经在其多款模型中采用了混合Mamba-Transformer MoE 架构,其中包括Nemotron-Nano-9B-v2。
Nemotron 3 将三种架构整合进同一个主干网络中:
Mamba 在极低内存开销下即可有效追踪长程依赖关系,即使在处理数十万 token时也能保持稳定性能。Transformer 层则通过精细的注意力机制进行补充,捕捉代码操作、数学推理或复杂规划等任务所需的结构性与逻辑关系。
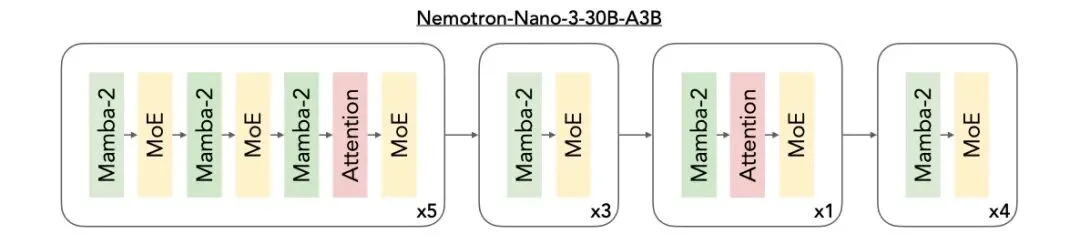
MoE组件在不引入稠密计算成本的前提下,显著放大了模型的有效参数规模。对于每个 token,仅会激活部分专家网络,从而降低延迟并提升吞吐量。该架构尤其适合多智能体集群场景:大量轻量级智能体需要并发运行,各自生成计划、检查上下文,或执行基于工具的工作流。
官方指出,与Nemotron 2 Nano相比,这一设计“最多可实现4倍的token吞吐量提升”,并通过将推理token的生成量最多减少60%,显著降低了推理成本。
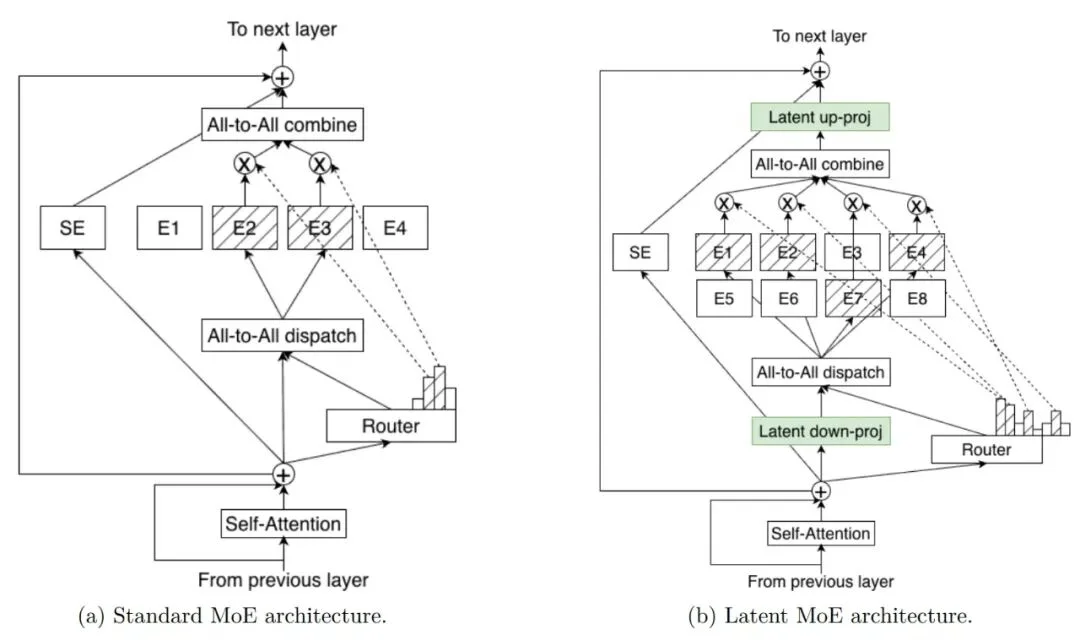
Nemotron 3 Super 和 Ultra 在实现更先进的精度和推理性能的同时,也引入了一项突破性创新:latent MoE(潜在空间专家混合) 。
各个专家在共享的潜在表示空间中进行计算,随后再将结果投射回 token 空间。这种设计使模型在相同推理成本下能够调用多达 4 倍的专家数量,从而在细微语义结构、领域抽象以及多跳推理模式等方面实现更强的专门化能力。
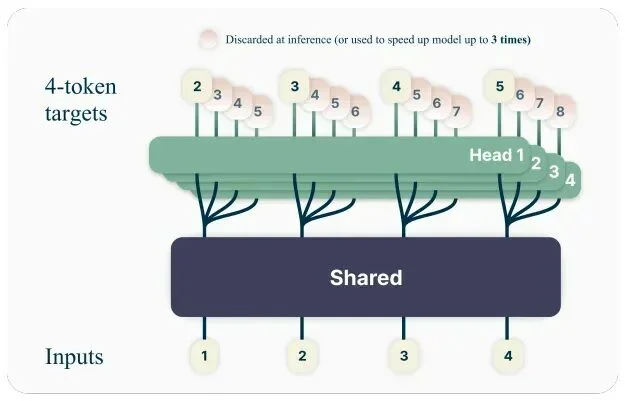
新模型中还采用了多token预测(MTP),使模型能够在一次前向计算中预测多个未来 token,显著提升长序列推理和结构化输出的吞吐量。在规划、轨迹生成、延展式思维链或代码生成等场景中,MTP 可以降低延迟并提升智能体的响应速度。
值得注意的是,在预训练过程中,Super 与 Ultra 版本采用的是NVFP4 格式。NVFP4 是NVIDIA 的 4 位浮点格式,在训练和推理中具有业界领先的成本-精度表现。
针对 Nemotron 3,官方设计了更新版 NVFP4 训练方案,以确保在 25T token 的预训练数据集上实现准确且稳定的预训练。在预训练过程中,大部分浮点乘加运算均使用 NVFP4 格式完成。
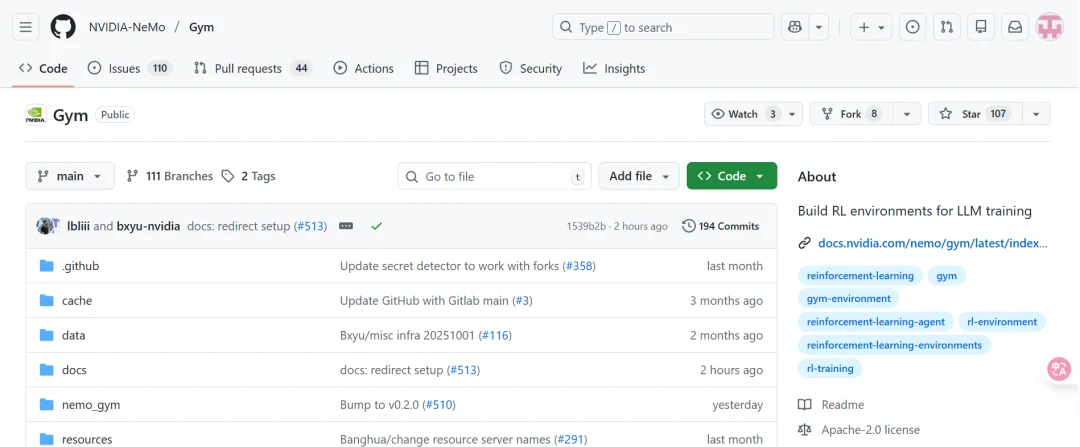
为了使 Nemotron 3 更好地对齐真实的智能体行为,模型在后训练阶段通过 NeMo Gym 中的多环境强化学习进行训练。
NeMo Gym 是一个用于构建和规模化强化学习环境的开源库。这些环境评估模型执行动作序列的能力,而不再局限于单轮回答,例如生成正确的工具调用、编写可运行的代码,或产出满足可验证标准的多步骤规划。
这种基于轨迹的强化学习训练方式,使模型在多步工作流中表现更加稳定可靠,能够减少推理漂移,并更好地处理智能体流水线中常见的结构化操作。
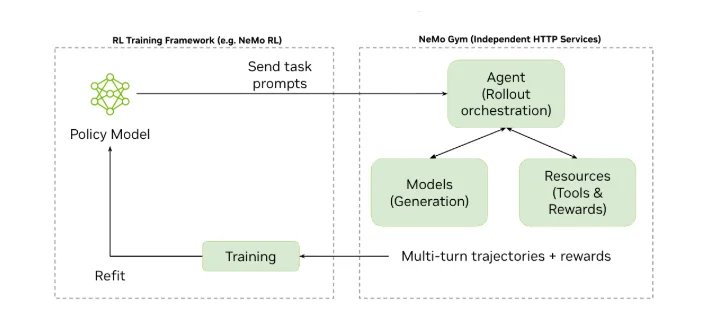
值得注意的是,英伟达还为广大开发者开源了NeMo Gym,可以带来以下能力:
github链接:
https://github.com/NVIDIA-NeMo/Gym
看到这里,有些朋友可能会有疑问了:英伟达不是一家做GPU的硬件公司吗?为什么要做自己的AI模型呢?
实际上,除了提供芯片和GPU之外,英伟达也提供大量自有模型,涵盖物理仿真、自动驾驶等多个领域。
2024年,英伟达就发布了 Nemotron 品牌下的首批模型,基于 Meta 的 Llama 3.1 设计。
此后,英伟达推出了多款不同尺寸和针对特定场景调校的 Nemotron 型号,并且都以开源形式发布,供其他公司使用。包括Palantir Technologies在内的一些企业,已经将英伟达的模型整合进自身产品中。
就在上周,英伟达还宣布了一款新的开放推理视觉语言模型 Alpamayo-R1,专注于自动驾驶研究。英伟达表示,增加了更多涵盖其 Cosmos 世界模型的工作流程和指南,这些模型是开源且采用宽松许可,以帮助开发者更好地利用这些模型开发物理 AI。
从种种举动可以看出,英伟达是有意推动构建开源生态了。
官方说法也证实了这一点。企业生成式 AI 副总裁 Kari Briski 表示,英伟达的目标是提供一个“人们可以信赖的模型”。
“我们会把这些 LLM 当作一个库来看待。我们会把它公开,让开发者检查代码,这样你们可以理解它、在它基础上构建、我们可以修复 bug、改进它,然后再把改进后的版本重新发布出去。我们越是开放,开发者的参与度就越高。”
英伟达创始人兼首席执行官黄仁勋也公开表示:
“开放式创新是人工智能进步的基础。通过Nemotron,我们正在把先进AI转变为一个开放平台,为开发者提供在大规模构建智能体系统时所必需的透明性和效率。”
因此有媒体指出,在OpenAI、Anthropic、Meta等一系列已经转向或正在转向闭源的美国公司中,英伟达有望成为美国最主要的开源模型提供商之一。
Nemotron 3 Nano 已经发布,很快在Reddit上引发了网友热议。
不少网友指出,实测下来 Nano 的表现并没有比GPT-OSS-20B和Qwen3-30B更强。
比如新模型虽然参数比 GPT OSS 20B 多 10B,但性能只是“匹配”,并没有大幅超越。
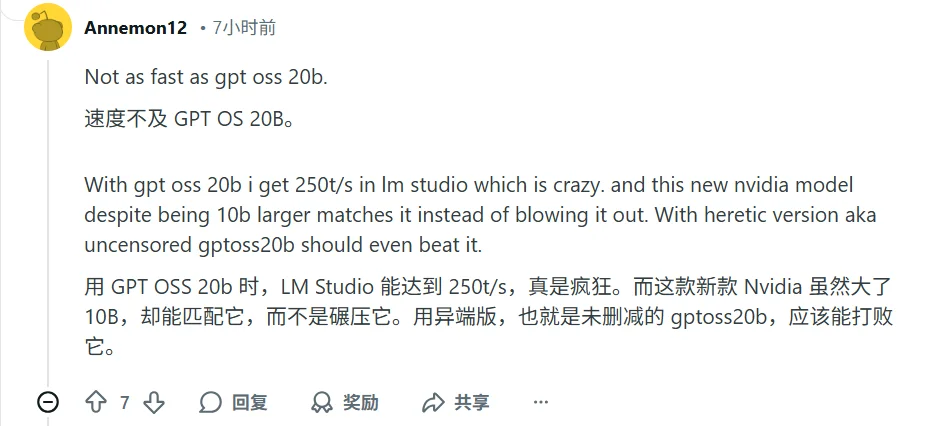
或是新模型的文件更大,不一定是 Qwen3-30B-A3B 的理想替代。

有网友用模型进行了微积分测试,结论是:GPT-OSS-20B在数学分析上表现更优。

还有网友发现,Nemotron 3 Nano 在长上下文和信息提取任务中仍存在幻觉、重复和推理不稳定的问题,而 Qwen3 系列在类似任务上表现更稳健,这可能是因为是llama.cpp对模型的发挥存在限制。

但总的来说,也是有不少网友点赞的,比如新模型在特定量化和硬件下的高吞吐性能,以及英伟达的开源精神。
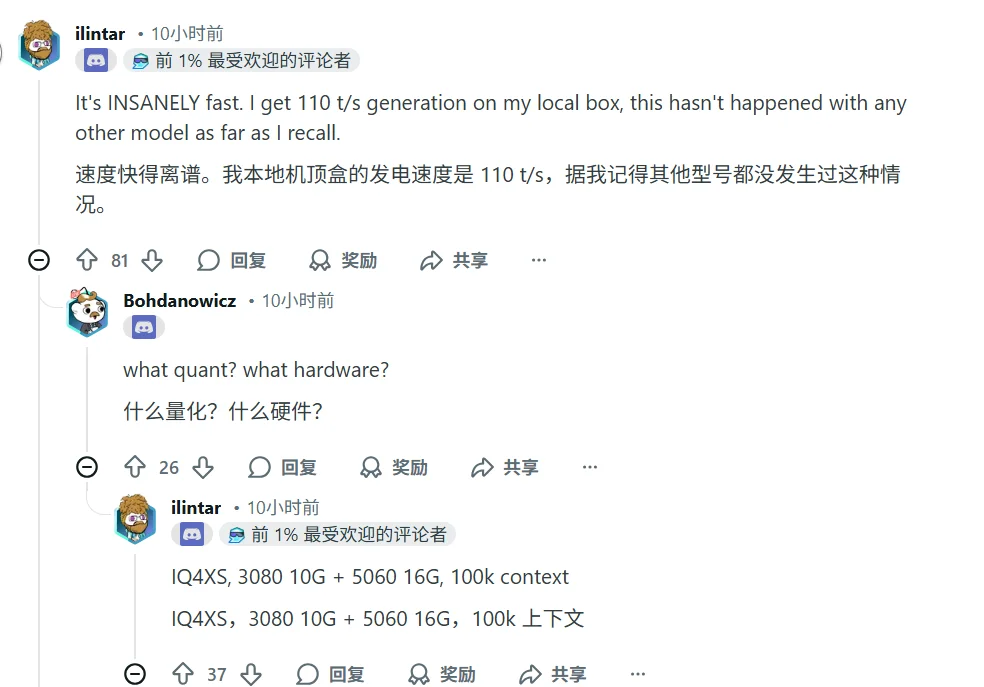
官方也发布了几个主要推理引擎(vLLM、SGLang、Tensor-RT)的Cookbooks,方便开发者部署和运行Nemotron 3 Nano。
感兴趣的朋友都可以去试试!
参考链接:
https://developer.nvidia.com/blog/inside-nvidia-nemotron-3-techniques-tools-and-data-that-make-it-efficient-and-accurate/
文章来自于“51CTO技术栈”,作者 “听雨”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
