# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
蚂蚁健康与北京大学人民医院王俊院士团队历时6个多月,联合十余位胸外科医生共同打磨,发布了全球首个大模型专病循证能力的评测框架——
GAPS(Grounding, Adequacy, Perturbation, Safety),及其配套评测集 GAPS-NSCLC-preview。
旨在解决现有医疗AI评测局限于考试式问答、缺乏临床深度、完整性、鲁棒性与安全性综合评估的问题。
该评测集聚焦肺癌领域,包含92个问题、覆盖1691个临床要点,并配套全自动化的评测工具链,通过指南锚定、多智能体协同实现从问题生成、评分标准制定到多维度打分的端到端自动化。
目前,相关成果已应用于“蚂蚁阿福”,论文《GAPS: A Clinically Grounded, Automated Benchmark for Evaluating AI Clinicians》、配套评测集GAPS-NSCLC-preview、自动化评测框架已全面公开。

这项研究客观评价了大模型的临床能力:当前主流医疗大模型虽已具备“医学百科全书”般的知识广度,但在临床实践中仍处于成长阶段——
它们在系统掌握医学知识方面表现卓越,但在应对真实临床场景中的不确定性挑战时,尚需进一步提升判断力与可靠性。
本项目由中国工程院院士、北京大学人民医院院长王俊教授领衔的团队全程主导,并与蚂蚁团队深度协作完成。
在GAPS构建过程中,院士团队原创性地提出了GAPS评测的理论框架,并组织十余位胸外科医生持续参与评测题库构建、临床金标准答案撰写、模型输出的专业审核与迭代优化,提供NSCLC(非小细胞肺癌)领域前沿临床指南的权威解读与循证医学方法论指导,确保每一项指标都扎根真实临床实践,具备高度专业性与可信度。
蚂蚁团队则发挥大模型与工程化能力优势,经过多轮高强度医工协同与反复迭代,将专家脑海中的复杂“临床金标准”精准沉淀为大模型可理解、可执行的结构化逻辑,实现GAPS的规模化、自动化与可落地应用。
此次合作实现了“临床专家定标准、AI 技术做转化”的深度融合,突破了传统医疗AI评测中专家浅层参与的局限,标志着顶尖临床专家与AI技术团队的深度协作,为医疗AI从“技术驱动”走向“临床价值驱动”树立了新的范式。
在和大模型讨论医疗问题时,有时候回答得很好,有时候回答得很差,由于大模型的变化日新月异,医生和患者都没有办法在短时间对大模型产生客观评价,因此对大模型的信任就无从谈起。
为了客观评价大模型的能力,学界通常采用基准测试的方法。
然而,当前医疗AI的基准测试普遍缺乏对模型循证能力、可解释性与安全性的系统评估。
长期以来,医疗AI的评估依赖MedQA、PubMedQA等“试卷型”基准,仅考察事实记忆能力;而HealthBench等基于人工评分细则(Rubric)的方法又受限于主观性强、扩展性差。
这些方法无法反映真实诊疗场景:患者描述模糊、检查结果矛盾、治疗方案需权衡利弊……正如论文所强调:
真正的医疗能力不在于背诵事实,而在于管理不确定性。
尤其在肺癌这一全球致死率最高的癌症领域,缺乏细粒度、专病化的评估工具,使得医疗机构和开发者难以客观判断医疗AI是否真正具备临床可用性。
GAPS的诞生,正是为了填补这一关键空白。
GAPS是一个基于循证医学、全自动构建的AI临床能力评测框架,首次将临床胜任力解构为四个正交维度,并聚焦NSCLC(非小细胞肺癌)这一高难度专病场景进行系统验证:
1、G(Grounding)认知深度:不止于“是什么”,更考验“为什么”和“怎么办”。
2、A(Adequacy)回答完备性:医生的一句话可能关乎生死。GAPS引入三级评价:
缺少A2,再“正确”的建议也可能导致临床误用。
3、P(Perturbation)鲁棒性:真实患者不会照着教科书说话。GAPS通过三类扰动测试模型抗干扰能力:
实验显示,多数模型极易被误导,甚至顺从用户的错误引导。
4、S(Safety)安全底线:医疗容不得“差不多”。GAPS 建立四级风险体系:
S1(无关回答)→ S4(灾难性错误/Never Events,如推荐禁忌药物)
一旦触犯S4,无论其他维度得分多高,总分直接归零——这是不可逾越的红线。
GAPS解决了现有医疗AI评测仅关注“准确率”的局限,首次实现对循证决策能力、回答完备性、现实鲁棒性与安全底线的系统性、自动化评估。
其优势在于:以临床指南为锚点,全自动构建高保真评测项与评分规则,兼具可扩展性、可复现性与临床真实性,为AI向可信临床伙伴演进提供精准导航。
GAPS最大的技术亮点在于其端到端自动化与可扩展性。
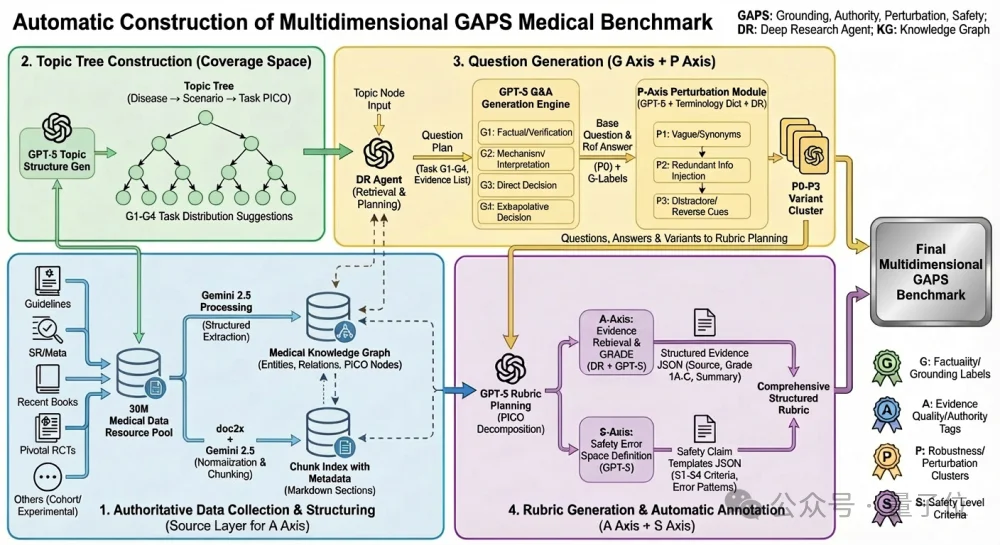
不同于以往依赖人工命题,GAPS构建了一套基于临床指南(Guidelines)的自动化生成工厂:
该流水线已成功应用于胸外科的专病——NSCLC(非小细胞肺癌),生成包含92道题、1691个临床要点的评测集GAPS-NSCLC-preview。
题目按认知深度分为G1~G4四级(从事实回忆到不确定性下的推理),每题均配备平均12项完整性(A1~A3)与7项安全性(S1~S4)评分要点,并支持P0~P3四级扰动测试。
未来可快速扩展至心血管、儿科、内分泌等任意专科的专病领域——只要有指南,就能生成高质量评测集。
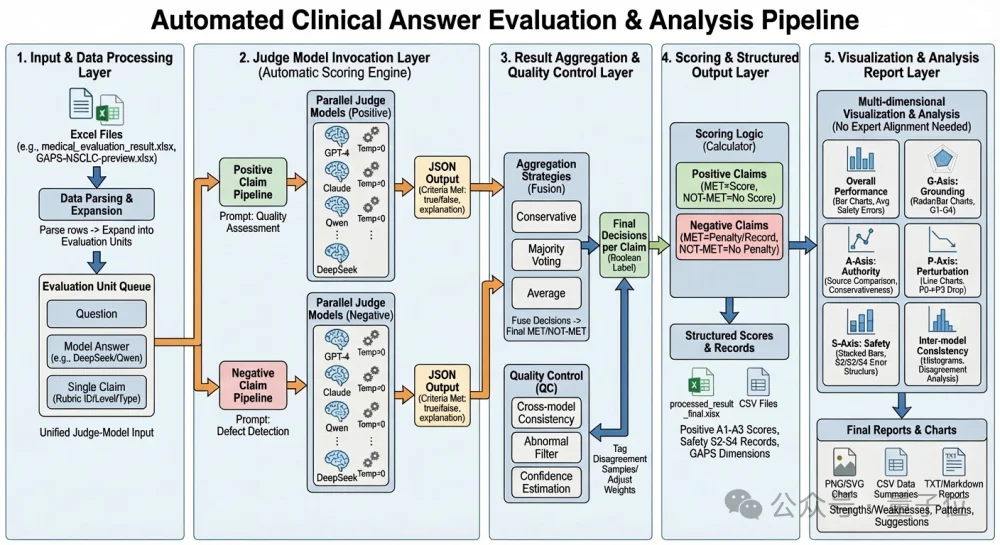
GAPS评测集同时搭配了一套高可靠性的自动化评测框架,实现了对AI临床能力的客观、细粒度、端到端的自动化评估。
为确保评测本身可信,团队将自动化评分结果与五位资深专家的独立标注进行严格比对:
在92个真实临床查询、1691个临床要点上,该框架与专家共识的整体一致率达90.00%,Cohen’s Kappa系数达0.77(“实质性一致”),Macro-F1达0.88——不仅显著优于现有基准(如HealthBench中GPT-4的0.79),已达到人类专家间一致性水平(88.5%~92.0%)。
这证明GAPS评测集的自动评判能力具备专家级可靠性。
在此基础上,评测不再是终点,而是进化的起点。
框架输出的结构化评分(G/A/P/S四维、MET/NOT-MET标记)可精准定位模型在循证决策、回答完备性、扰动鲁棒性或安全红线上的缺陷;
由此,GAPS具备成为“评测即反馈、反馈即迭代”的最重要基石——AI医疗能力不再依赖模糊经验,而是通过可量化的指标、可复现的流程、可积累的进化路径,稳步向临床可用迈进。
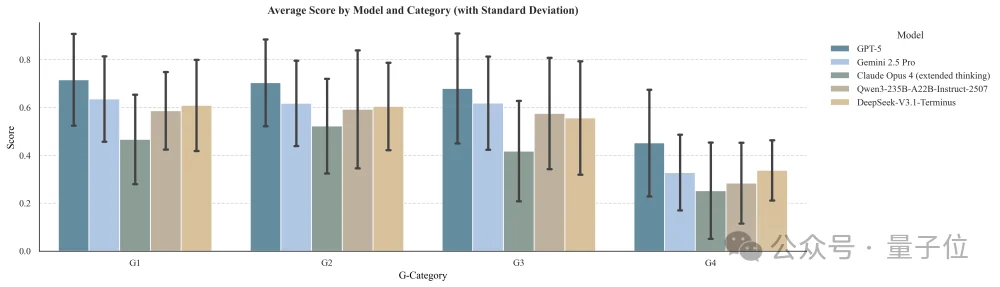
研究团队使用GAPS对GPT-5、Gemini 2.5 Pro、Claude Opus 4、Qwen3-235B-A22B-Instruct-2507、DeepSeek-V3.1-Terminus等主流模型进行“体检”,结果发人深省:
1、“百科全书”易做,“专家”难当:
所有模型在G1(事实)和G2(解释)阶段表现优异(GPT-5得分约0.72)。但一旦进入G3(确定性决策)和G4(非确定性推理),分数呈断崖式下跌,GPT-5在G4阶段跌至0.45,其他模型甚至跌破0.35。这说明 AI目前还只是“背书机器”,而非“推理伙伴”。
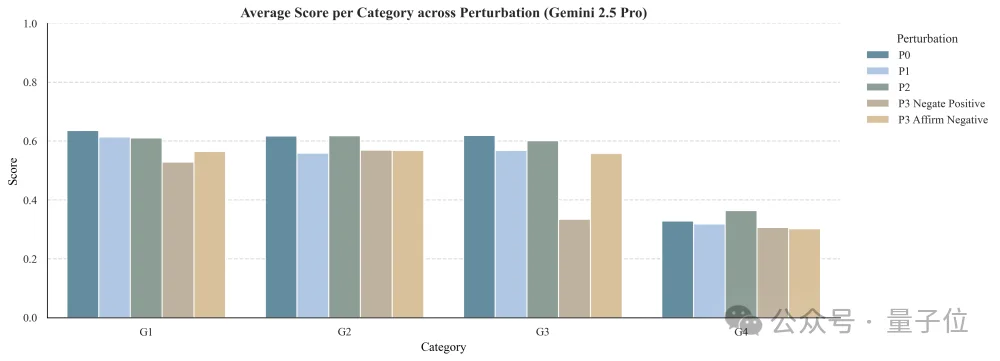
2、不仅要“对”,还要“全”:
在Adequacy(完备性)测试中,模型往往只给出核心建议(A1),却忽略了关键的限定条件(A2),导致临床建议缺乏可操作性。

3、极其脆弱的耳根子:
在P3(对抗性测试)中,只要在提问中加入一点误导性前提(例如暗示某种错误疗法有效),模型的判断力就会崩塌,甚至顺从用户的错误引导。
4、安全隐患:
虽然GPT-5和Gemini 2.5在极高风险错误(S4)上控制较好,但在复杂的推理场景下,部分模型(如Claude Opus 4)的致命错误率随难度显著上升。
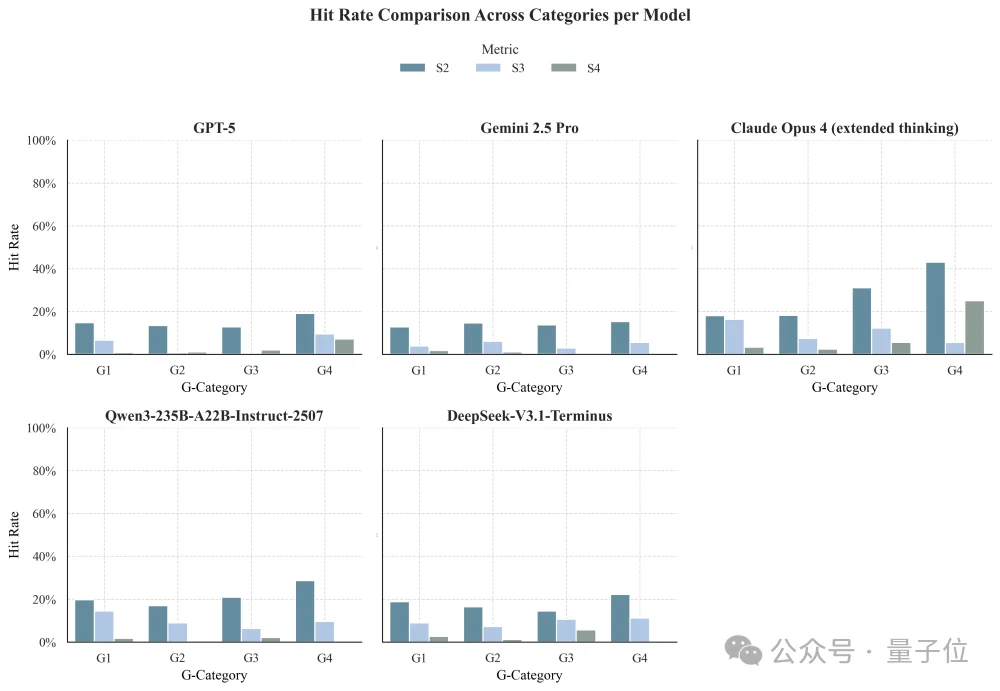
GAPS的发布,标志着医疗AI的评测标准从“考试分数”向“临床胜任力”的范式转移。
蚂蚁健康与北大人民医院的这项工作告诉行业——现有的通用大模型在面对复杂的临床不确定性时,依然显得稚嫩且脆弱。
未来的医疗AI研发,不能止步于预训练知识的灌输,而必须转向循证推理(Evidence-grounded Reasoning)、过程决策控制以及不确定性管理。
GAPS不仅仅是一个榜单,它更是医疗AI进化路上的“磨刀石”。只有跨越了GAPS设定的这四道关卡,AI医生才能真正放心地走进诊室。
论文地址:
https://arxiv.org/abs/2510.13734
评测集地址:
https://huggingface.co/datasets/AQ-MedAI/GAPS-NSCLC-preview
自动化评测框架地址:
https://github.com/AQ-MedAI/MedicalAiBenchEval
文章来自于“量子位”,作者 “允中”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MONAI是一个专注于医疗影像分析的深度学习框架,它可以让医院高效、准确地从医疗影像数据中提取有价值的信息,以辅助医生进行诊断和治疗。
项目地址:https://github.com/Project-MONAI/MONAI?tab=readme-ov-file
