# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这两天,影视飓风那支《带着100万...我们去了论文代写聚集地》的视频彻底火了。大众的目光都被肯尼亚贫民窟里庞大的“论文代写产业链”所吸引,2.5美元的廉价劳动力、流水线般的学术欺诈。
但在所有人都把目光盯着猎奇的产业链时,我却在一个细节上停住了。
视频里有一位住在海景房、拥有直接客户的高级写手 Teriki。他和那些在小作坊里拼命内卷的廉价写手完全不同。
当被问到他是如何用 AI辅助论文写作时,他的工作流正好和我一直推崇的不谋而合。如下图所示:

“首先,我从不直接用 AI 来生成文章。我只会让 AI 给我推荐课题、相关且学术上可信的资料。我会逐字阅读重要资料……只有当我确保理解了这个课题,我才会开始写作。”
那一刻,我意识到:这位肯尼亚的写手,比我们身边 90% 的 AI 爱好者更懂 AI 的本质。
他无意中道破了 AI 论文写作的最高心法:AI 输出的质量,严格正比于你投喂信息的密度。
如果你只把 AI 当作生成器,它是廉价的枪手,产出的是垃圾;
如果你把它当成整理高密度信息的处理器,它就是最强的研究助理,产出的是黄金。
今天,结合我多次用 Gemini / ChatGPT 撰写了几十篇法律文书和爆款长文的经验,我想借着影视飓风的这个视频,拆解一套真正适用于深度论文写作的“高密度信息工作流”。
这套方法的核心,不是教你如何偷懒,而是教你如何做“人工 RAG(检索增强生成)”。
很多人用 AI 写论文最大的误区,就是直接问 Gemini / ChatGPT:“帮我写一篇关于 XXX 的文献综述”。
这时候,AI 调用的是它肚子里“通用语料库”的存货,大概率会给你编造出不存在的作者和论文(AI 幻觉)。
正如真正的论文写作,第一步必须是“高密度的信息采集”。这里我有两把武器:
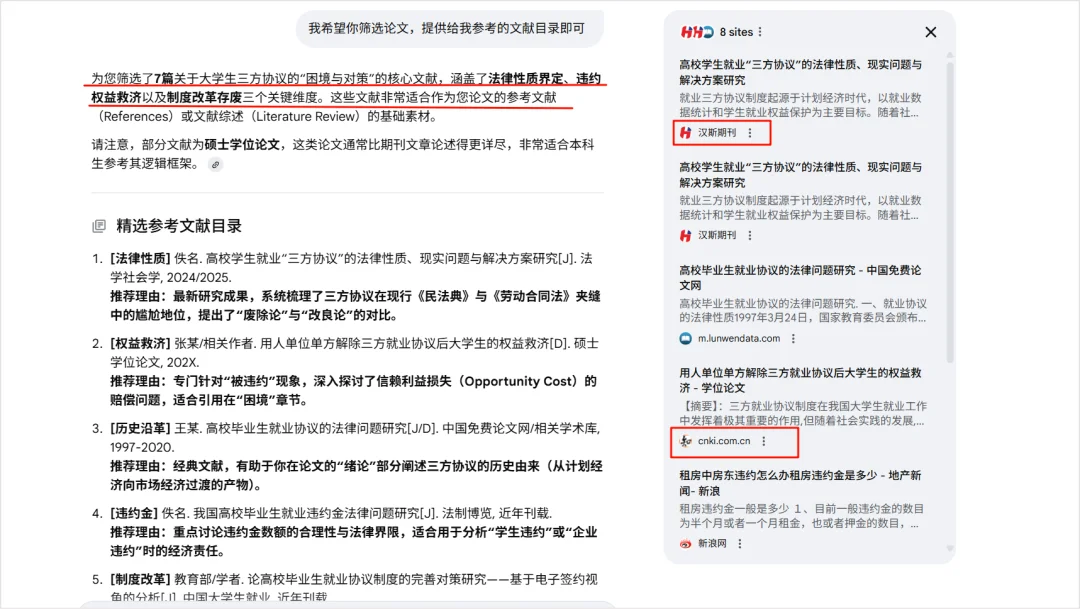
1. 泛读与线索发现:Google 搜索 AI 模式
对于网上公开的论文、政策文件或新闻报道,Google 搜索 AI 模式是最好的入口。 它的核心优势是“所见即所得”。点击引用链接,直接跳转高亮原文。这能帮你快速筛选掉那些营销号的垃圾信息,找到真正有价值的期刊或官方通报来源。如下图所示:
2. 深度学术检索:NotebookLM 的“来源搜索”功能
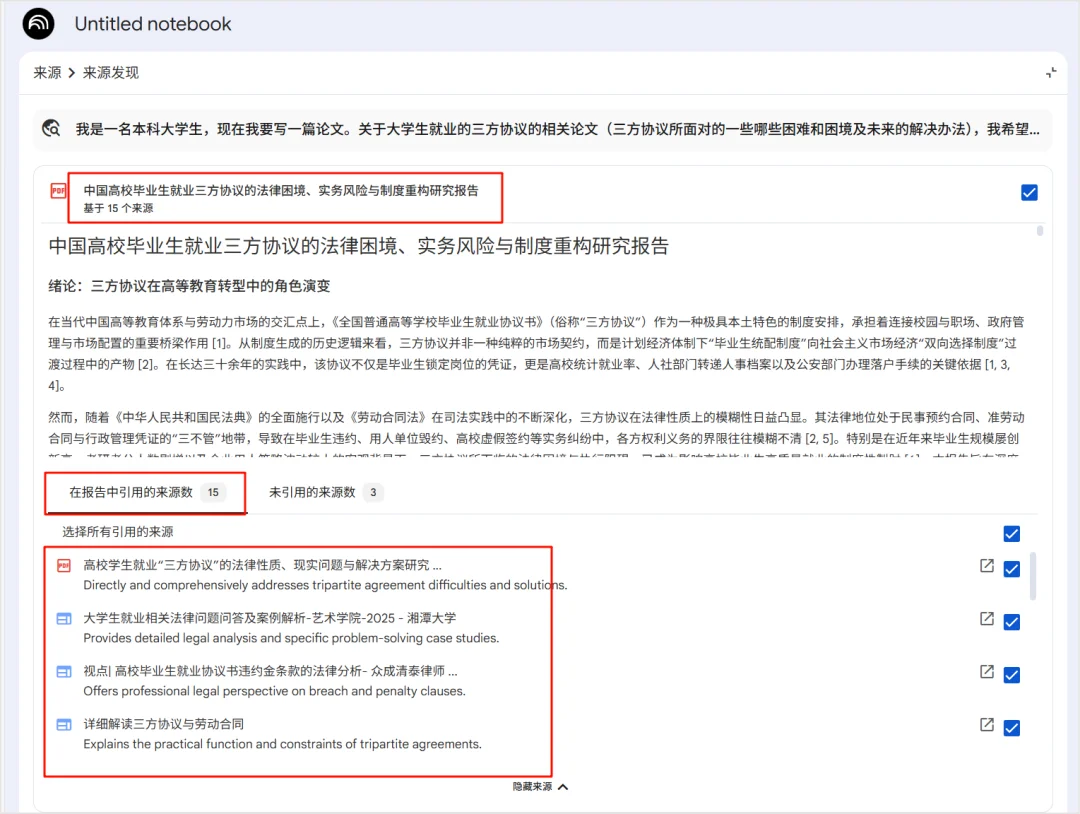
很多人只知道 NotebookLM 是一个学习神器,也是一个 PPT生成神器,却不知道它也是个论文文献检索神器。在来源处,你可以直接使用其背后的搜索能力(甚至开启 Deep Research 模式),它的数据源涵盖了 Arxiv、Google Scholar 等高质量学术库,可以说它信息密度本身就很高。这意味着,你不需要自己去一个个前往论文网站,筛选和下载论文,而是直接在 NotebookLM 里就能把相关的学术资源捞进来。
如下图所示,我使用了 Deep Research 模式,它不但给我生成了一个报告,还提供了15篇文献,我只需点击“导入”即可将其加入进来,作为对话的语料。
3. 兜底大招:手动 RAG(Manual RAG)
如果以上工具都找不到你想要的特定领域文献(比如知网的付费论文、特定年份的内部数据),请务必亲自动手。 前往知网、Arxiv、各大期刊官网,手动下载 PDF,将其导入到 NoteBookLM,让其辅助你阅读和理解文献。
这时,你千万别嫌麻烦。 正如影视飓风视频里的 Teriki 一样,只有经过你亲手筛选(强相关和弱相关文献)、下载、确认过的高信度文献,才是喂给 AI 的特供有机食材。
这一步的若偷懒,后续 AI必定生成“屎山”。
这是最关键,也是最容易被忽视的一步。Teriki 说他会“逐字阅读重要资料,确保理解课题”。为什么?正所谓:“AI 是一个强大的能力杠杆,但杠杆的支点必须是你自身不断增长的认知深度”。
1. 充分使用学习神器:NotebookLM
你可以将筛选到的数篇论文 PDF 扔进 NotebookLM,它能生成摘要、思维导图、甚至音频概览。但这不代表你可以不看了。
它可以作为你的私人知识库。你不需要像 Teriki 那样全部手动摘抄,而是利用 NotebookLM 将杂乱的网页、PDF 转化为结构化的“学习指南”或“要点大纲”。
这构成了喂给写作 AI 的“高密度种子素材”。你需要借助 NotebookLM 快速消化这些文献,形成你自己的“认知地图”。
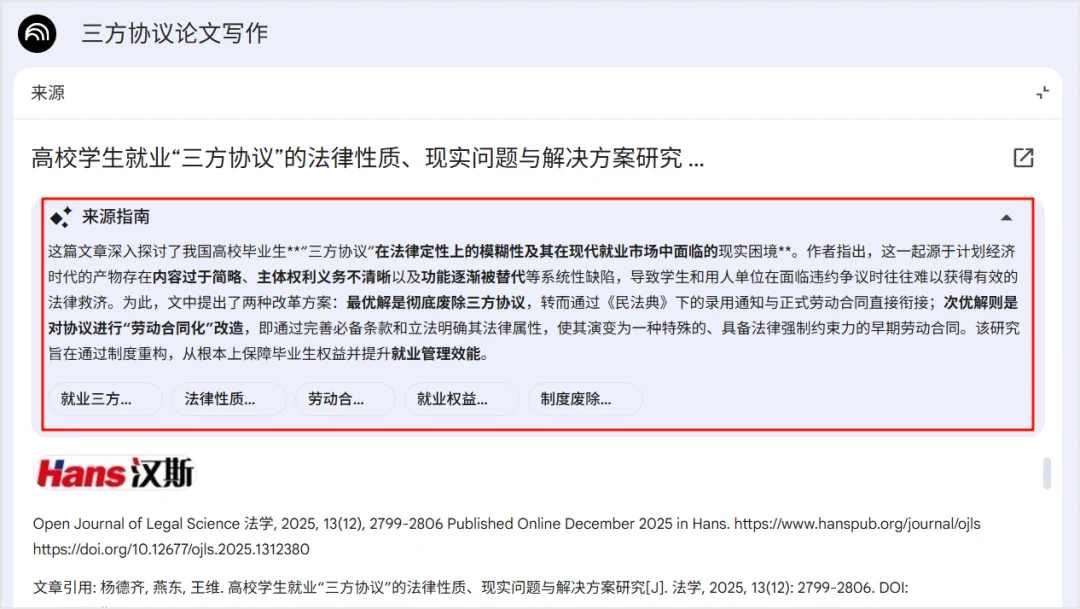
如下图所示,你点击每一个文献,NotebookLM都会问你生成来源指南(文献摘要)和关键词,供你快速阅读和掌握这篇论文。
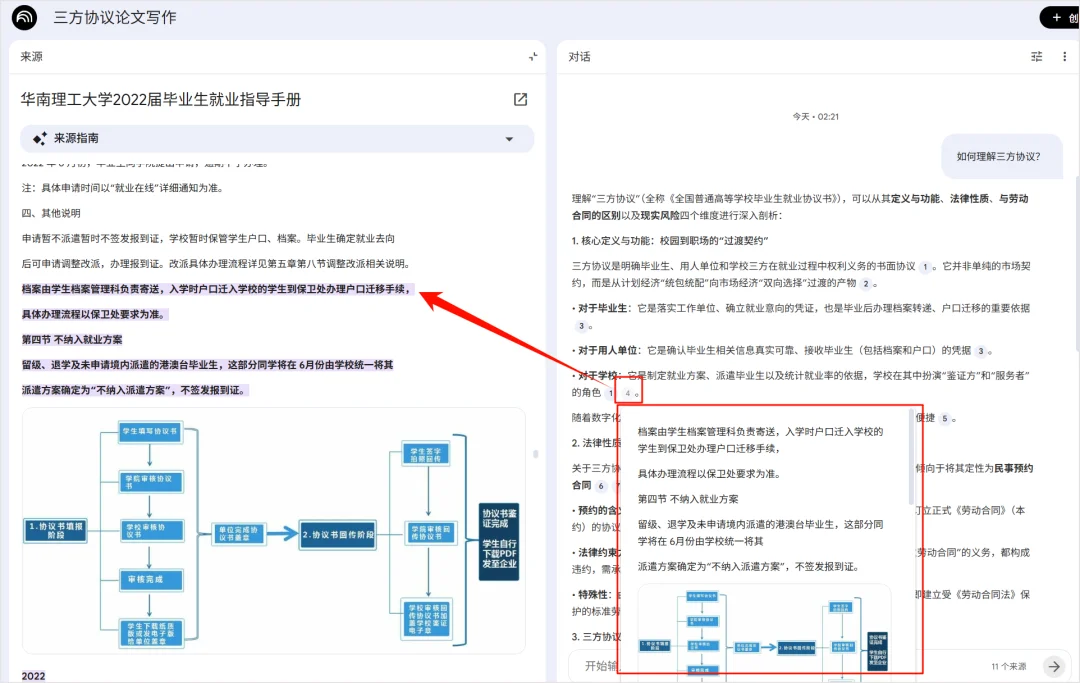
其次,你与 NotebookLM 对话时,NotebookLM 会充分尊重文献,每一句输出都不会脱离文献,如下图所示,NotebookLM 也有所见即所得的能力,你点击引用序号,会直接跳转高亮原文,这能极快地帮助你吃透文献。
最后,你也可以将 NotebookLM 笔记导入到Gemini 上让其进行分析。Gemini最近更新,上传部分支持添加 NotebookLM 笔记了,Gemini 可以看到这个笔记本中上传的所有来源文档列表,并且我有能力读取这些文档的具体全文内容。如下图测试。
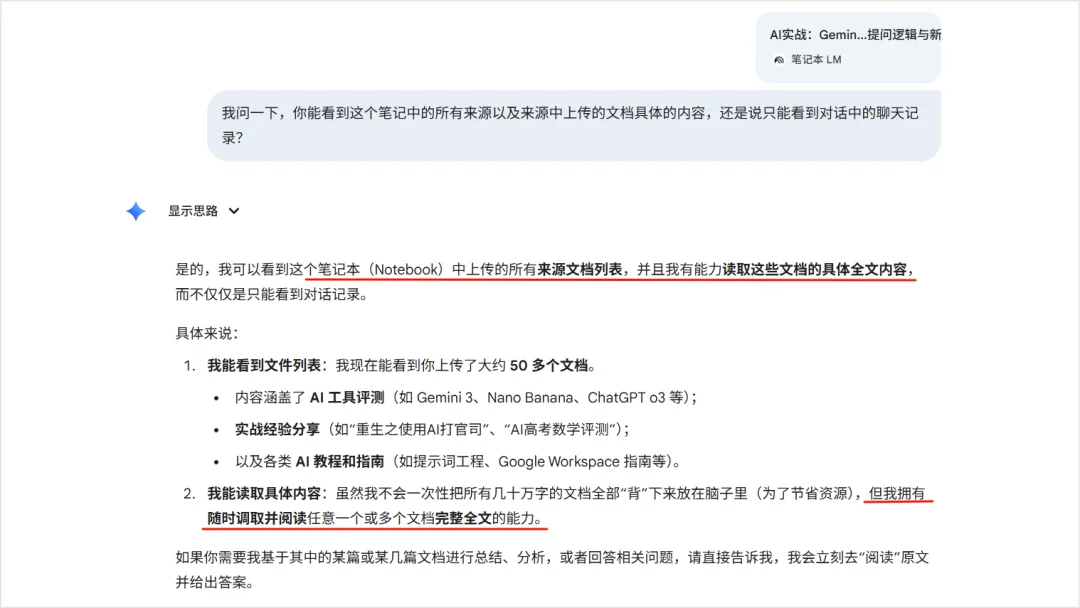
但可惜的是经过测试 Gemini 是无法识别到用户与 NotebookLM 的对话记录,这有些难受,毕竟 NotebookLM 尊重原文程度远高于 Gemini,这导致我很喜欢与 NotebookLM 对话。看后面给官方写一份建议信试一试。
2. 只有胸有成竹,才能提出“启发性问题”
我在之前的文章99% 的人在向 AI 提问时,都犯了一个“自以为是”的错误中提到过一个理念:用户在使用 AI 处理熟悉和擅长的领域时,发挥的作用才是最大的。
所以,写学术论文时,如果你自己都没读懂文献,你根本无法判断 AI 分析和总结得对不对。只有你通过阅读掌握了课题,你才能设计出精准的提示词,指导 AI 按照你的逻辑去归纳和处理。
当你手里有了高密度的信息(清洗好的文献笔记)和清晰的认知(你的观点),最后一步才是生成。
不要直接对 AI 说:“给我输出一篇论文”。要使用“退一步提示(Step-Back Prompting)”技巧。 可以尝试放上论文的草稿,问 AI:“基于这些文献,目前的研究空白在哪里?逻辑矛盾是什么?” 还要大胆地提出自己的论文写作方向,方法论和想法等(即就是将前面你阅读文献记录的笔记)。
这里要充分暴露我们的无知,让 AI 作为一位资深某领域的导师,客观地,批判性地评价这篇论文,从而做到查漏补缺,获得启发性问题。这就是从 0 到 0.5 的过程。
接着才是,要求 AI 基于上文输出一篇论文。正如我一直强调的:只要“上下文”足够丰富,“逻辑链条”足够清晰(由 Deep Think 的思考过程保证),AI 输出的论文或文章就不再是简单的词语堆砌,而是具有严密逻辑和详实数据的高质量作品。
这样输出的论文,既有 AI 的效率,又有你的灵魂,而且每一个引用都是你亲手核查过的,绝对经得起推敲。
这里我建议大家使用 Gemini Deep Think,它就是为了学术而生,它引入革命性的并行思考架构,能同时探索 16 条推理路径。它不是为了给你堆砌信息,而是为了验证逻辑、解决难题、发现盲区。更多推荐阅读:刚刚,Gemini 3 Deep Think 正式发布!又一个王炸!
回到影视飓风的视频。Teriki 之所以能住海景房,是因为他拒绝做流水线上的拼凑者,他选择了做非洲谚语里那个“狮子的历史学家”。

“直到狮子有了自己的历史学家,狩猎的故事才不会只歌颂猎人。”
Teriki 是令人尊敬的“手工匠人”,他用 AI 找矿,然后自己打磨宝石。而我们作为新一代的 AI 使用者,应当“现代工业化的设计师”:
我们用 Google搜索 AI 模式和 NotebookLM 高效探矿、洗矿(提纯高密度信息),然后将这些高纯度的原料交给 Deep Think 这个精密机床,并在旁边通过 Prompt (自身认知)指挥它加工。
在 AI 时代,写论文的门槛看似降低了,实则“真相的门槛”变高了。
那些试图用通用语料库瞎编的人,最终会被 AI 生产的垃圾淹没。
而那些愿意花时间做“人工 RAG”、愿意带着脑子去阅读、去喂数据的人,将把 AI 变成手中最锋利的剑,从而掌握定义真相的权利。
文章来自于“稀有学生”,作者 “我是离谱”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
