# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
凭借成功预测 Polymarket 题目,连续登顶 Future X 全球榜首的 MiroMind 团队,于今日(1 月 5 日)正式发布其自研旗舰搜索智能体模型 MiroThinker 1.5。
MiroMind 由全球知名创新企业家、慈善家陈天桥,与清华大学知名 AI 青年学者代季峰教授联合发起。去年陈天桥提出发现式智能才是真正意义上的通用人工智能这一重磅创新理念,引发全球业内人士关注。他同时提出建设发现式智能的 5 种关键能力,其中一项能力是在未知条件下重建对世界的理解,这正是 MiroMind 的使命。
在过去 7 个月里,当全行业都在「卷」参数规模、「卷」百万长文本的红海时,MiroMind 却在思考一个更本质的问题:智能的「奇点」究竟在哪里?他们给出的答案不是「把世界背进参数里」,而是押注「发现式智能」:真正的智能不靠全知,而靠会研究、会查证、会修正 —— 像顶级情报官一样对外极速取证、对内严苛去伪存真;像严谨研究员一样在不确定性里逼近真相,最终把「预测未来」从特权变成能力。
MiroMind 团队在 AGI 竞技场上,不信奉 “大力出奇迹”,而是追求以高智效比为核心的 「巧劲」。
MiroThinker-v1.5-30B 仅用 1/30 的参数规模跑出了比肩众多 1T 模型的性能表现,其 235B 的版本在多个搜索智能体基准测试中跻身全球第一梯队。
实力霸榜:指标是门槛,预测是天花板
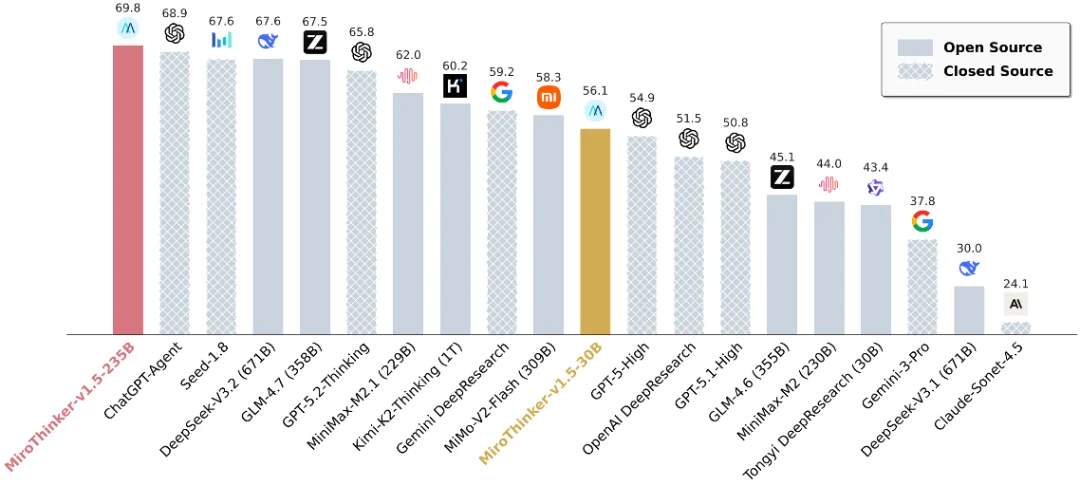
BrowseComp 性能对比
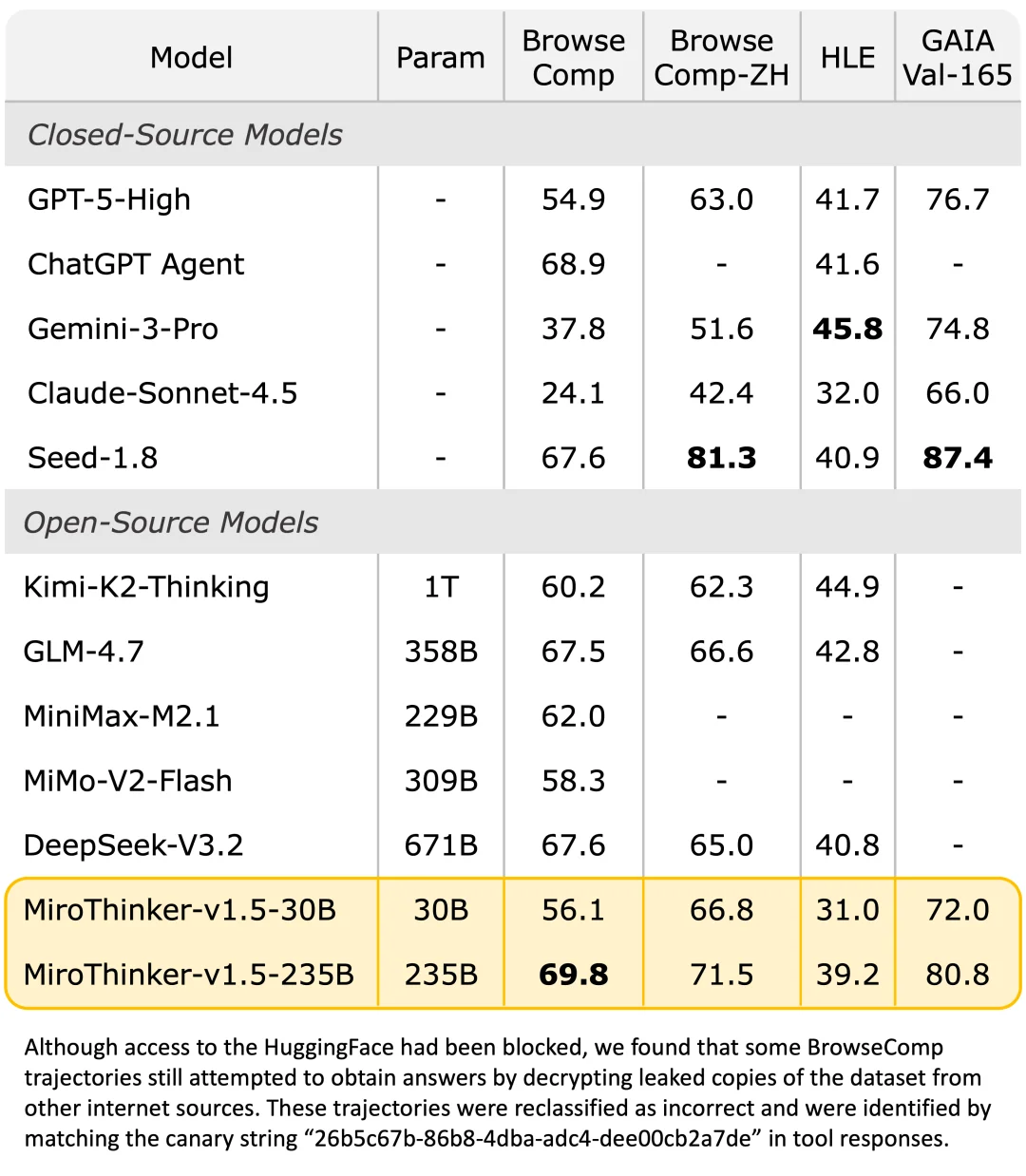
Agent 搜索评测基准性能对比
越级挑战:MiroThinker-v1.5-30B vs Kimi-K2-Thinking
面对参数量高达 30 倍的万亿参数巨兽 Kimi-K2-Thinking,MiroThinker-v1.5-30B 用极低的成本展示了旗鼓相当的表现:
核心洞察:从 「做题家模式」 转向 「科学家模式」
MiroMind 团队指出,以扩大模型内部参数量(Internal Parameters)为核心的传统 Scaling Law 已明显触及边际瓶颈;要继续提升模型性能,必须从「内部参数扩张」转向以「外部信息交互」(External Interaction)为核心的 Interactive Scaling,将智能的增长空间从内部参数扩展到外部世界。
为什么该模型能在大幅降低成本的同时,性能依然能打?
因为这不是「大参数碾压」,而是一次「科学家模式」对「做题家模式」的胜利。以 Scaling Law 为代表的路线,更像「做题家」:试图把全人类知识(也包括噪声与错误)尽可能背进模型里;一旦遇到生物学等领域的未知问题,就容易基于概率分布「编」出一个看似合理的答案 —— 幻觉往往由此产生。
在 MiroThinker 1.0 中,MiroMind 团队首次系统性提出 Interactive Scaling:随着工具交互频率与深度提升,研究式推理能力也稳定增强 —— 这构成了与模型大小、上下文长度并列的第三个可扩展维度。v1.5 更进一步,把这套机制内化为贯穿训练与推理全流程的核心能力:将模型训练成「科学家」,核心不是死记硬背,而是勤查证。遇到难题时,它不会给出概率最高的瞎猜,而是执行慢思考的研究闭环:提出假设 → 向外部世界查数据 / 取证 → 发现对不上 → 修正假设 → 再查证,直到证据收敛。
主流大模型往往盲目追求万亿参数,试图把整个互联网「背」在脑子里。而 MiroThinker 系列选择了一条反共识的路线:刻意将模型控制在 30B–200B 的轻量级规模。MiroMind 团队强调,省下的不是算力,而是把算力花在了更刀刃的地方 —— 对外的信息获取与交互。
MiroMind 团队不追求让模型拥有一颗「最重的脑子」,而是培养它拥有一双「最勤的手」。当模型同时具备研究式确认机制与时序因果约束,这种围绕外部信息获取的交互过程才让「发现式智能」真正落地 —— 也正是对 Interactive Scaling 的深耕,使他们用小得多的模型,做到了大模型才能做到的事。
传统的模型思维链本质上是在模型内部知识空间的线性外推,推理偏差会随路径增长而不断累积,最终导致逻辑坍塌。
MiroThinker 1.5 的核心发力点,在于通过 Interactive Scaling 打破孤立推理的僵局,将「推理」与「外部环境」深度耦合。通过构建「推理 - 验证 - 修正」循环,引入外部信息作为校验锚点,用确定性的证据流来对冲不确定性的推演,解决逻辑坍塌问题。
Training-time Interactive Scaling 技术
当智能的 Scaling 范式不再局限于模型内部庞大的世界知识储备与缜密的长程逻辑推理,而是依托模型高频与外部世界中探索与交互并获得闭环反馈时,小而高效的探索者模型能展现比肩于甚至超出大而严谨的思考者模型的智力水平。
MiroThinker 1.5 正是基于这一判断,将 Interactive Scaling 从推理阶段的外挂能力,前移并内化为训练阶段的核心机制。模型并非被要求「尽量在脑中想清楚一切」,而是被系统性地训练成一个善于向外求证、敢于否定自己、能够快速修正路径的 Agent。
在训练过程中,MiroMind 团队刻意削弱对「单次完美推理」的奖励,转而强化以下行为模式:
通过这种训练方式,MiroThinker 1.5 逐步形成了一种「本能反应」:在不确定性面前,先交互、再判断;在高风险结论前,先查证、再收敛。这使得模型不再需要将庞大的世界知识全部内化为参数,而是学会在需要时,快速、精准地向外部世界「借力」。
最终,团队用更小的参数规模,换来了更高的智能密度:不是让模型记住更多,而是让它学会如何找到、验证并使用信息。这正是 MiroThinker 1.5 能在显著降低推理成本的同时,依然保持一线性能的根本原因。
时序敏感训练沙盒
时序敏感训练沙盒,是破解「因果律」的钥匙:普通大模型训练常处在「上帝视角」—— 它在数据里早已「见过结果」,学到的往往是复述与「剧透」,而不是预测。MiroThinker 的训练则约束模型「只能看过去,不能看未来」,在严格的时间可见性约束下做判断、再用同样受时序约束的证据去验证与更新。
在这种训练范式下,模型被迫学会在信息不完备、噪声存在、信号延迟的真实条件下进行推演与修正,而不是依赖静态数据集中的「标准答案」。时间由此从一个背景变量,转变为塑造模型行为与推理方式的核心约束,使模型更接近真实世界中的认知与决策过程。
Case 1: A 股涨停板预测
据介绍,这不是 「玄学」,更不是事后诸葛亮 —— 而是在信息极度噪声化、情绪快速切换的盘面里,用开放世界证据 + 因果推断去赌 「次日正确答案」。(注:以下仅为技术展示,不构成投资建议)
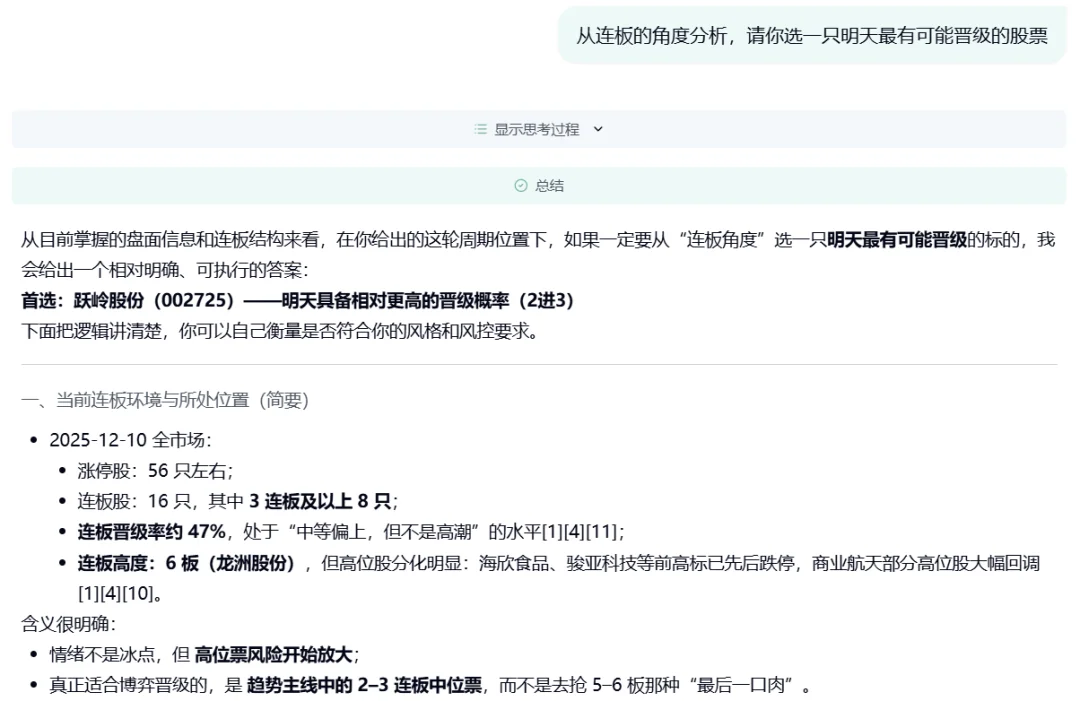
对话链接:https://dr.miromind.ai/share/07430808-d84d-4e40-9615-bf07d6e71365

对话链接:https://dr.miromind.ai/share/eccc29b9-889b-43f9-b6bf-f4b2b7c8dc1e
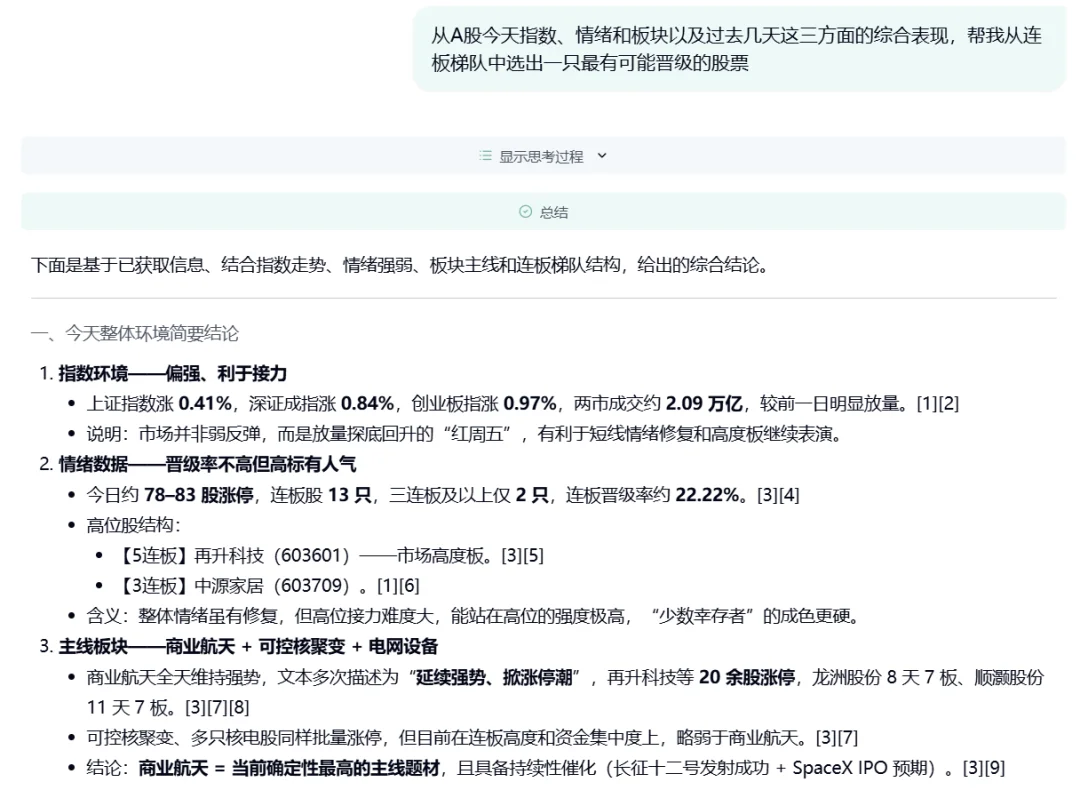
对话链接:https://dr.miromind.ai/share/e9db058d-3e8c-4922-b483-cf5efae2f414
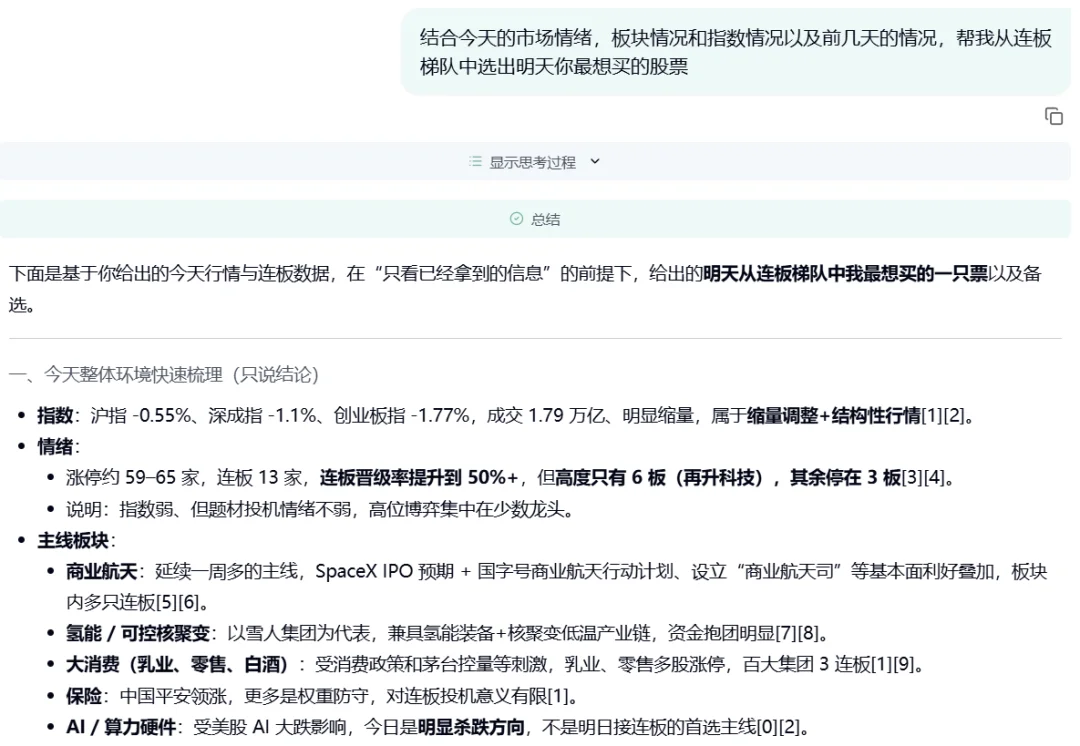
对话链接:https://dr.miromind.ai/share/3dc7dae0-78cb-4a97-8f61-359ab2d3e1a0
Case 2: 下周有哪些大事件会对美股七巨头产生影响?预期的市场反应和潜在波动方向是什么 ?
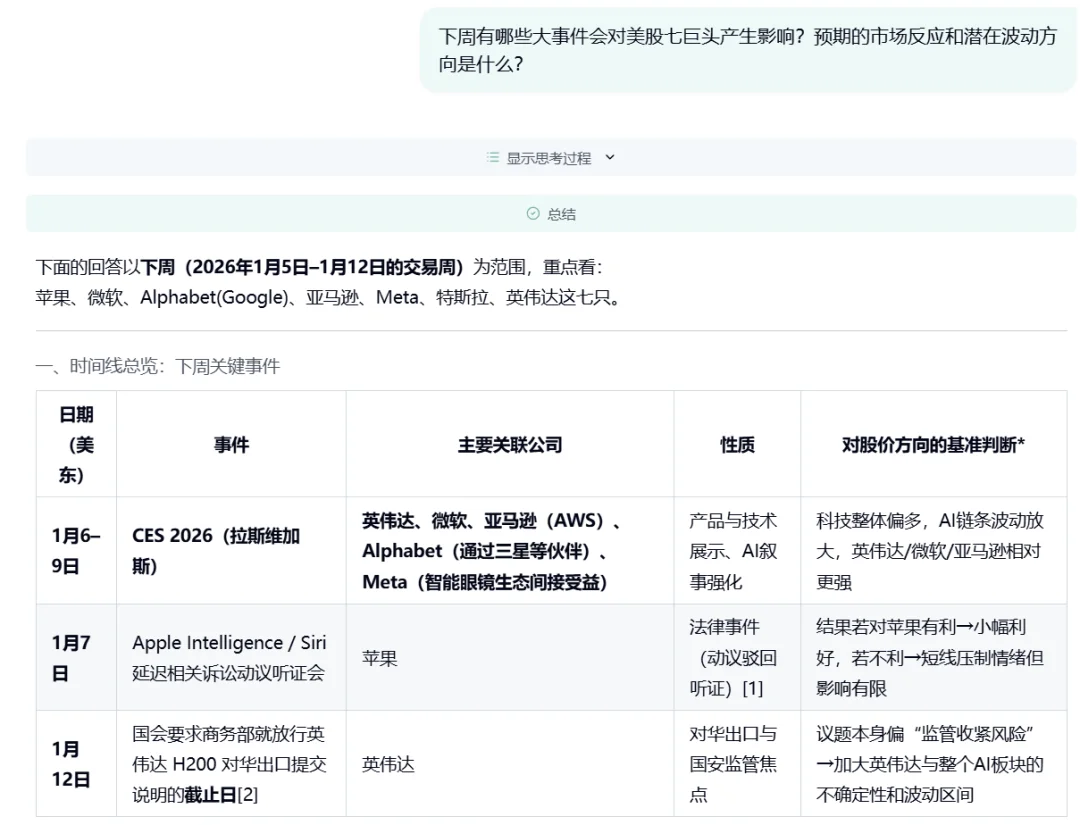
对话链接:https://dr.miromind.ai/share/f4afae1a-21e1-4f6d-8eef-16909c2d7b79
Case 3: GTA 6 明年能按时发布吗?
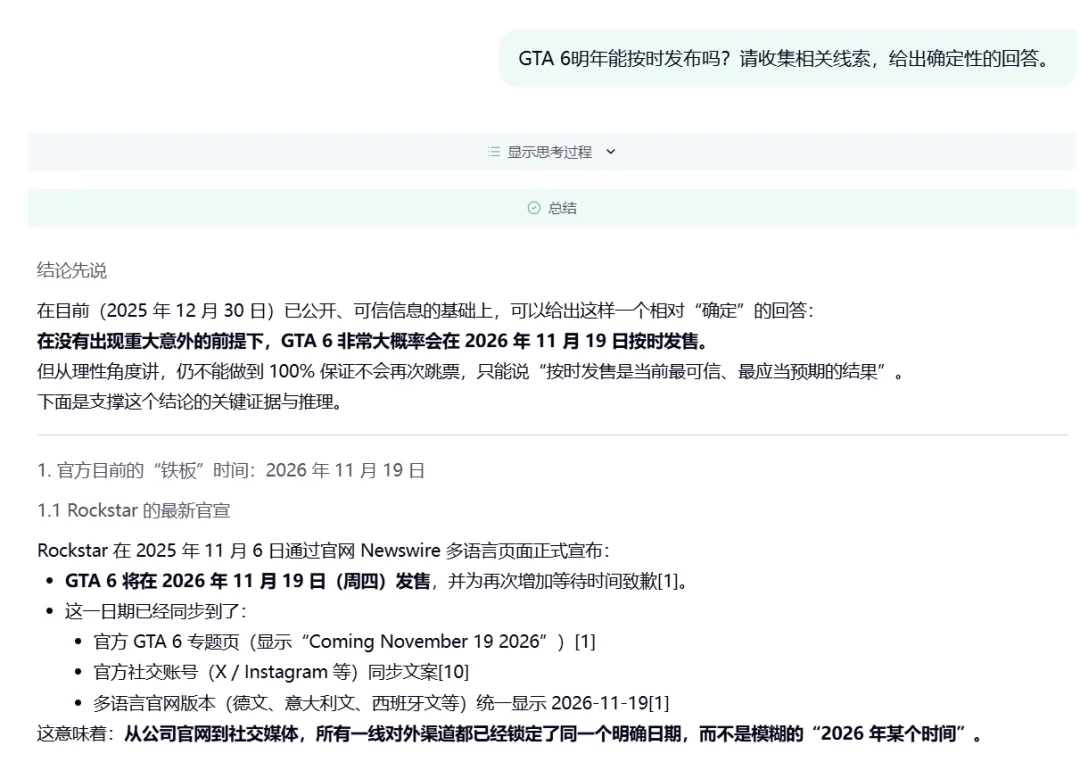
对话链接:https://dr.miromind.ai/share/10e5d1fd-c6b6-4b96-a2ed-4b776a3e1dcd
人才招募
MiroMind 面向全球持续招募人才,简历投递:talent@miromind.ai
产品体验
立即体验 MiroMind,免费解锁预测未来的能力: https://dr.miromind.ai/
加入社群:
相关链接:
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
