# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 MiniMax M2.5 的发布并在社区引发热烈反响,很高兴能借此机会,分享在模型训练背后关于 Agent RL 系统的一些思考。
在大规模、复杂的真实世界场景中跑 RL 时,始终面临一个核心难题:如何在系统吞吐量、训练稳定性与 Agent 灵活性这三者之间取得平衡。为了解决这个问题,我们设计了一个异步的原生 Agent RL 系统—— Forge。在 Forge 中,我们通过实现标准化的 Agent-LLM 交互协议,支持了对任意 Agent 脚手架进行训练,并且通过极致的工程优化和稳定的算法与奖励设计,实现了超大规模的强化学习。
在面对数十万个真实的 Agent 脚手架和环境以及 200k 的上下文长度时,我们的 RL 系统做到了每天百万级样本量的吞吐,并实现持续稳定的 Reward 上涨和真实的模型能力提升,并最终造就了 MiniMax M2.5 模型的性能突破。
问题建模
在深入探讨架构设计之前,我们首先将 Agent 强化学习系统的优化目标形式化为“最大化有效训练收益(J)”:

其中,Throughput 是指每秒处理的原始 Token 数量,其主要受 RL 系统中的四部分控制: Rollout、Training、Data Processing 和 I/O。Sample Efficiency 则是指每个样本带来的平均性能提升,由数据分布、数据质量、算法效率以及 Offpolicy 程度决定。而稳定性和收敛性则能够基于训练过程中监测指标来判定。
要实现(J)的最大化,我们需要克服以下三类挑战:
当前常见的 RL 框架和范式对 Agent 的复杂度限制很大,主要体现在:
Rollout 的完成时间存在极大的方差——短则几秒长则数小时。这带来了一个异步调度问题:
RL 系统设计
为了实现真正可扩展的架构,我们不再局限于具体的 Agent,而是转向了通用的抽象层设计,将 Agent 的执行逻辑与底层的训推引擎彻底解耦。我们的 RL 系统由 3 个核心模块组成:
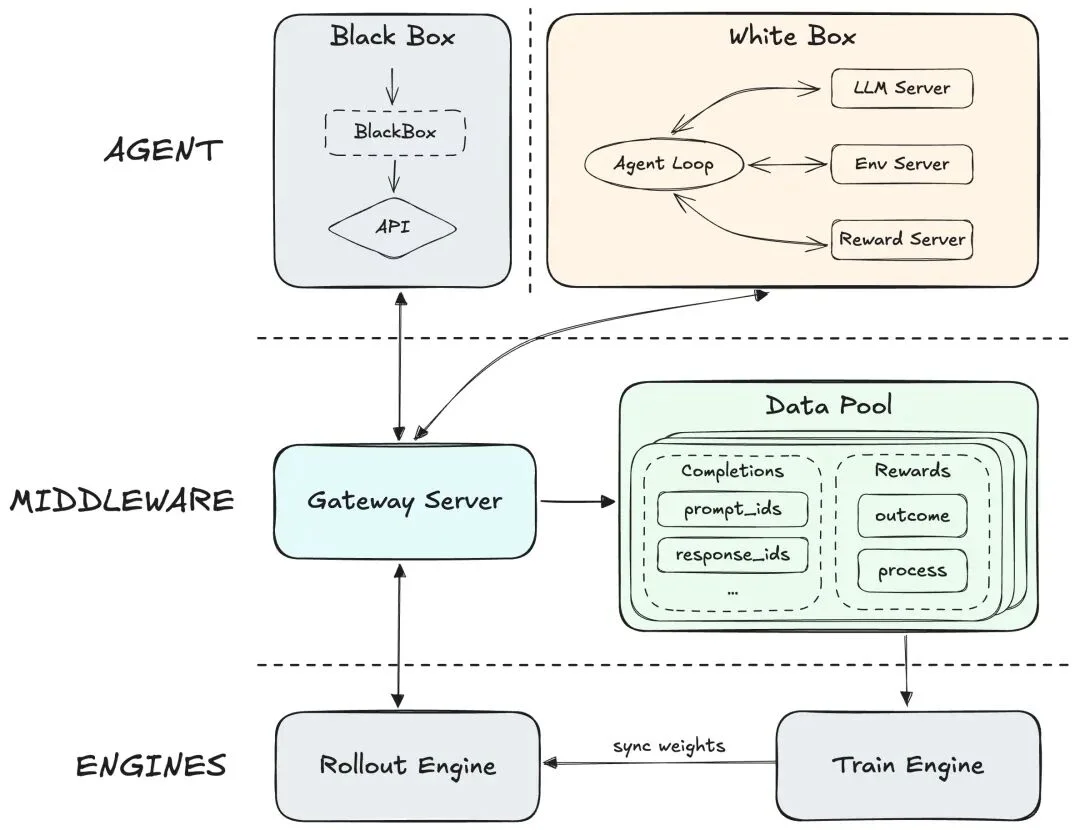
1.Agent:该层抽象了通用 Agent(涵盖白盒和黑盒架构)及其运行环境。它负责协调环境交互,使 Agent 成为一个纯粹的 Trajectory Producer。通过将环境交互与 LLM generation 解耦,Agent 可以专注于核心业务逻辑(如 context management 和复杂的环境交互等),而无需关心底层的训练和推理细节。
2.中间件抽象层:作为桥梁,该层在物理上将 Agent 侧与训练/推理引擎隔离。
3.训练与推理引擎:
我们在离线评估中发现,不同 Agent 脚手架会导致显著的性能偏差。借助该模块化设计,我们在无需修改 Agent 内部代码的情况下,使用大量的 Agent 框架进行了训练。这种“引擎与 Agent 完全解耦”的架构确保了模型能在各类环境中泛化,目前我们已集成了数百种框架和数千种不同的工具调用格式。
对于白盒 Agent,我们可以通过充分的脚手架设计和增广,以直接观测和优化模型在特定类型 Agent 上的表现。在 M2.5 中,我们特别优化了过去模型在带上下文管理的长程任务(如 DeepSearch)中出现的一些问题:
为了解决这些问题,我们将上下文管理(Context Management, CM)机制直接整合到 RL 交互循环中,将其视为驱动状态转换的功能性动作:
许多用户的真正在用的 Agent 实际上是闭源的,我们完全无法感知内部的 Agent loop 逻辑。为了确保模型在不透明架构上也能对脚手架针对性优化,我们采用了以下方案:
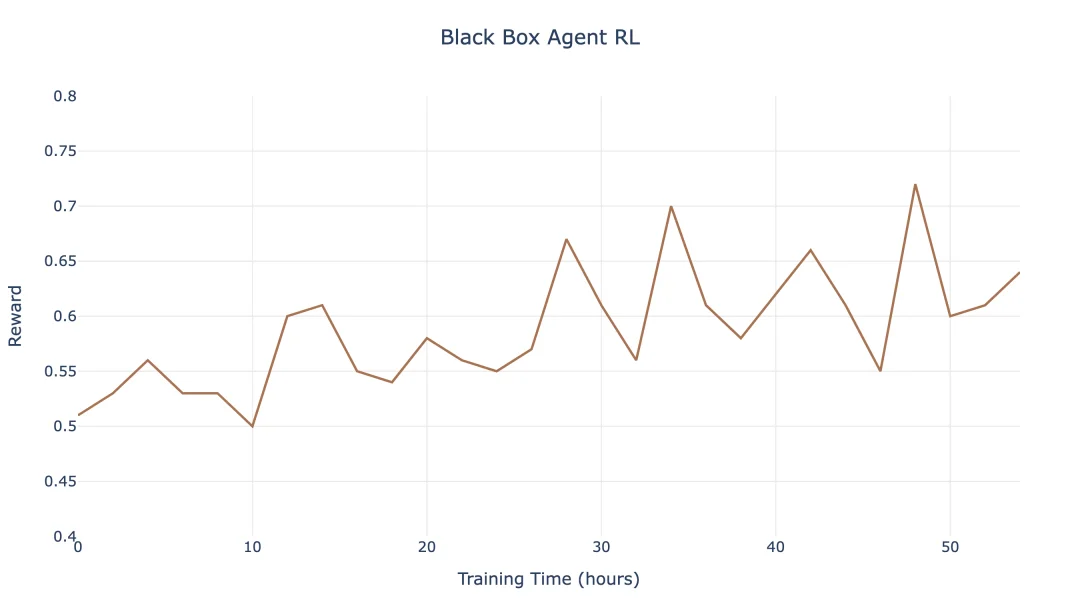
为了解决吞吐量与数据分布一致性之间的冲突,我们提出了 Windowed FIFO 调度策略。该策略介于 FIFO 和 Greedy 之间,即可以保证系统的吞吐,也控制了样本的 off-policyness。
假设当前达到了最大的生成并发量(如 N = 8192),生成队列为 Q,当前头部位于索引 H。训练调度器受限于一个大小为W(如 W=4096)的可见窗口:
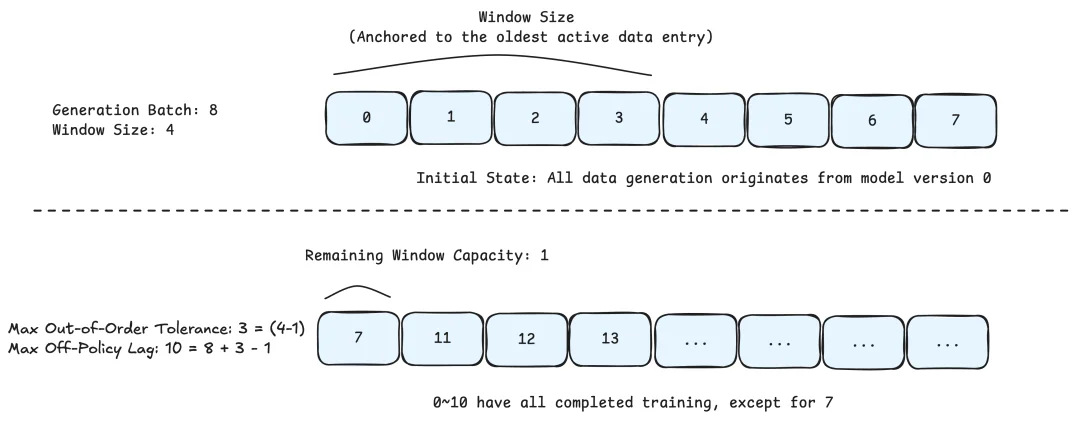
Agent 的多轮请求间存在很高的上下文前缀重合度,传统方法将每个请求视为独立样本,重复计算公共前缀,浪费了大量的训练算力。
我们提出了 Prefix Tree Merging 方案,将训练样本从“线性序列”重构为“树形结构”,下面是具体的数据处理和训练策略:
引入异步 RL 之后虽然 Rollout 阶段算力占比降低到了 60% 左右,但推理本身还有很大优化空间,我们通过下面的几项优化来加速 LLM 推理:
在 M2 系列中我们整体上沿用了 M1 时期提出的 CISPO 算法,尽管场景发生了显著变化——从几十 k 的 Long CoT 到 200k Context 的 Agent 场景,CISPO 依然提供了很强的 baseline。在此基础上,我们也针对 Long-horizon Agent 的特性进行了专门的适配与优化。同时在 Windowed FIFO 的基础上,我们采用了 Multi-Domain 混合训练策略。我们将 Reasoning、General QA、Code Agent、General Agent 等多个领域的任务同时混合训练。这缓解了分阶段训练中的遗忘问题,显著增强了模型的泛化能力。
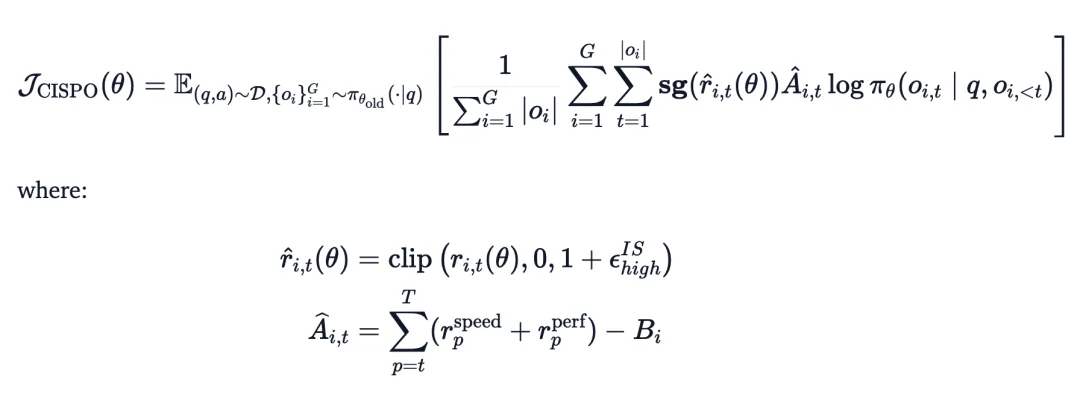
为了解决超长轨迹的信用分配问题并确保稳定,我们设计了一个由三部分组成的复合奖励:
1.过程奖励(Process Reward):监督 agent 的中间行为(如惩罚语言混合或特定工具调用错误),提供密集反馈,而不只依赖最终结果。
2.任务完成时间奖励:将相对完成时间作为奖励信号。因为真实延迟不仅取决于 Token 生成,还受工具执行和子 Agent 调用影响,这能激励 Agent 主动利用并行策略、选择最短的执行路径来加速任务。
3.用于降低方差的后续奖励(Reward-to-Go):长周期任务的稀疏奖励容易引发高梯度方差。我们使用 Reward-to-Go 来标准化回报,大幅提高了信用分配的精度,稳定了优化过程。
训出一个真正好用的模型,工程、数据、算法缺一不可,能赶在年前交出这份答卷,离不开背后每一位同事的努力。看到了社区非常多的正向反馈感到非常开心,其实 M2.5 还有很大的提升空间,内部 RL 也还在继续跑,性能也在持续涨。目前,M2.5 已经全面开源。
Hugging Face: huggingface.co/MiniMaxAI/MiniMax-M2.5
GitHub: github.com/MiniMax-AI/MiniMax-M2.5
春节马上到了,祝大家新年快乐!
文章来自于微信公众号 "MiniMax 稀宇科技",作者 "MiniMax 稀宇科技"



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
