# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
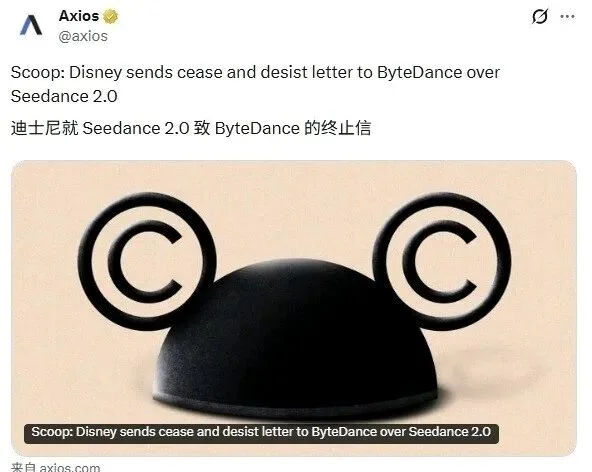
作为对数字科技法律实务感兴趣的律师,我全程跟踪了2026年2月这场引爆全球的AI版权风波——字节跳动刚发布3天的Seedance 2.0,就收到了迪士尼的正式侵权律师函,随后事件迅速发酵,引发全网关于AI与IP版权的大讨论。
本文所有事实均有权威媒体报道、公开司法文书交叉验证,带你看懂事件背后的法律逻辑、行业变局,以及这场战争对每一个人的影响。
先给大家还原经权威信源确认的完整事件时间线,同时厘清网传信息的核心误差,这是我们后续所有法律分析的基础:
2026年2月12日,字节跳动正式发布新一代AI视频生成模型Seedance 2.0,同步接入豆包App、即梦App等平台,凭借广播级画质、丝滑运镜、多镜头叙事控制的工业级生成能力,迅速引发全球行业关注。
模型上线仅2天,当地时间2月13日,华特迪士尼公司即向字节跳动全球总法律顾问发出正式停止侵权律师函,指控Seedance 2.0未经许可使用迪士尼旗下《星球大战》《漫威》等核心IP作品用于模型训练,且服务预置了包含迪士尼版权角色的素材库,用户可直接生成侵权内容,要求字节跳动立即停止侵权且不得再犯,措辞极为严厉,将其行为形容为“虚拟的打砸抢”。2月14日,该事件经Axios、国内主流财经媒体曝光后,彻底引爆全网。
这里必须先纠正全网流传的5个核心事实错误,杜绝以讹传讹:
从2022年Midjourney V1生成粗糙图像,到2026年Seedance 2.0实现电影级视频生成,AI技术4年的跨越式迭代,已经彻底突破了传统版权保护的边界,技术跑在了法律前面,利益冲突必然演变为全球性的法律战争。
很多人问我,迪士尼这封律师函,到底意味着什么?在我看来,这不是一次简单的商业维权,而是撕开了全球AI版权混战的口子,背后藏着三个足以颠覆整个AI行业规则的核心法律争议。
AI大模型的核心是数据训练,而训练数据的合法性,是本次争议的第一道红线,也是全球AI版权诉讼的核心矛盾。
迪士尼的维权逻辑,完全符合我国《著作权法》及全球多数国家版权法的基本规则:字节跳动未经著作权人许可,将迪士尼享有复制权、改编权、信息网络传播权的影视画面、角色形象、剧情表达纳入训练数据,无论是否直接生成原作品,都涉嫌侵犯著作权人的核心权利。
但在司法实践中,“训练行为是否构成著作权法意义上的复制”,目前全球并未形成统一裁判规则,需分法域严谨说明:
这里还要纠正一个全网普遍的绝对化误区:“AI训练的合理使用抗辩,并非完全不成立”。
合理使用,简单说就是著作权法规定的,在特定情况下可以不经授权、不支付报酬使用作品的情形,核心要件是“非商业性、少量使用、转化性使用、不影响原作品的正常使用”。对于仅使用作品的思想、规则,而非具体表达的训练行为,以及非商业性的科研训练行为,仍存在适用合理使用的空间,不能一概而论。
Seedance 2.0的核心能力是“一键生成影视级视频”,如果用户用模型生成迪士尼IP的侵权内容,责任该谁来担?这是本案的第二大核心争议,也是目前我国司法实践已有明确裁判规则的领域。
我国广州互联网法院、杭州互联网法院审理的“奥特曼IP AI侵权案”,已确立了明确的二元责任裁判规则:AI服务提供者与用户承担分层责任,用户承担直接侵权责任,AI平台根据其过错程度承担相应的侵权责任。具体拆解:
这里也要纠正一个误区:“奥特曼AI侵权案”的生效判决,仅针对AI生成内容的侵权责任作出了认定,并未对“训练数据未经授权是否构成侵权”作出明确裁判,网传的“该案已认定AI训练侵权”,属于对裁判文书的扩大解读。
AI技术无国界,但版权保护具有严格的地域性,这是本案最容易被忽视、却最具颠覆性的法律痛点。
迪士尼作为全球IP巨头,可同时在全球多个法域对字节跳动发起维权,而不同法域的版权规则、侵权认定标准、赔偿力度天差地别,AI企业的合规成本将呈几何级飙升:
这意味着,一款AI产品想要实现全球运营,必须同时满足全球数十个国家的版权合规要求,任何一个法域的维权诉讼,都可能导致产品在该区域的全面下架,这对所有AI企业而言,都是前所未有的合规挑战。
Seedance 2.0事件不是终点,而是AI版权持久战的起点,其冲击将远超技术层面,引发全产业链、全行业的结构性变革,而非简单的“中间环节消亡”。
未来3-5年,文创与AI行业将形成清晰的两极格局,行业利润将向两端集中,中间环节面临结构性收缩风险:
目前全球AI版权法律仍处于“司法探索先行,立法逐步跟进”的阶段,而Seedance 2.0事件,将倒逼全球各国加速AI版权立法进程,三大规则变革已成必然:
对于AI企业而言,合规将不再是可选项,而是生存底线;对于IP企业而言,版权维权将从“被动投诉”转向“主动布局”,版权运营将成为企业的核心竞争力。
网传的“翻译、影楼修图、会计等职业成耗材”的表述,过于情绪化且不符合客观规律,在此以律师视角作出严谨预判:
AI不会淘汰整个职业,只会淘汰职业中可被标准化、重复性替代的基础环节。
比如,基础的文档翻译、证件照修图、记账报税等工作,确实会被AI大幅替代;但法律翻译、文学翻译、商业片调色修图、IPO审计、税务筹划等具备高专业度、强创造性、高风险责任的核心工作,不仅无法被AI替代,反而会借助AI工具提升效率。
对于相关从业者而言,唯一的应对路径,就是从标准化的基础环节,向高附加值的核心环节转型,构建AI无法替代的专业护城河。
Seedance 2.0遭迪士尼围剿,看似是一次普通的商业维权,实则是数字时代版权保护的一次宣言:AI技术可以颠覆内容生产方式,但不能颠覆著作权法的核心底线;技术创新可以加速奔跑,但不能以侵犯他人知识产权为代价。
作为法律人,我始终坚信,技术创新与版权保护从来不是零和博弈。从印刷术到广播电视,从互联网到AI,每一次传播技术的革命,都会引发版权规则的重构,但最终都会形成“保护创作者权益、激励技术创新”的平衡格局。
未来,AI公司与IP巨头不会是永远的对手,而是合规合作的伙伴;这场席卷全球的AI版权海啸,终将推动行业走向“正版化、合规化、有序化”的良性发展轨道。而对于每一个身处其中的企业、从业者而言,唯一的生存法则,就是尊重版权、敬畏法律、拥抱合规。


本文仅代表作者个人观点,不构成正式法律意见。具体法律问题请咨询专业律师。
文章来自于微信公众号 "魏慧芳律师",作者 "魏慧芳律师"


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
